[번역] 에이전트 기반 테스트: E2E 테스트 스택에서 에이전트의 역할
I
Inkyu Oh
SW Engineering•2026.06.17
Sergii Gorbachov - 2026년 6월 11일
초록 (Abstract)
에이전트 기반 엔드 투 엔드(E2E) 테스트는 테스트에 새로운 탐색적 계층을 추가하지만, 이것이 기존의 결정론적(Deterministic) 테스트를 대체해야 할까요? 우리는 에이전트 기반 테스트가 우리와 여러분의 테스트 스택에 어떻게 적합할지 알아보기 위해, 비프로덕션 데이터를 사용하는 테스트 워크스페이스에서 Playwright MCP, Playwright CLI 및 에이전트 생성 Playwright 테스트를 사용하여 200개 이상의 에이전트 기반 E2E 워크플로우를 실행했습니다.
1. 여정에서 목표로 (From Journeys to Goals)
전통적인 엔드 투 엔드 테스트는 UI를 통한 특정 여정(Journey)을 검증합니다.
클릭 → 클릭 → 입력 → 단언(Assert)
반면, 에이전트 기반 테스트는 종종 지침(예: "스레드 메시지 보내기")으로 표현되는 목표(Goal)를 달성할 수 있는지 여부를 검증합니다.
목표 → 에이전트 적응 → 결과 확인
이 차이는 간단히 요약할 수 있습니다.
테스트는 여정을 강제하고, 에이전트는 목표를 검증합니다.
우리가 실행한 에이전트 기반 테스트 전반에서 전체적인 워크플로우(예: 로그인 → 검색 → 결과 → 초기화)는 일관되게 유지되었지만, 구체적인 작업 순서는 다양했습니다. 실제로 에이전트들은 동일한 결과에 도달하기 위해 서로 다른 경로를 택했습니다.
- 서로 다른 입력 방식 (검색 제안 클릭 vs 엔터 키 누르기)
- 서로 다른 탐색 패턴 (검색창 다시 열기 vs 기존 상태 재사용)
- 단계 추가 또는 생략 (추가 클릭, 스냅샷 또는 중간 작업)
에이전트는 필요할 때 중간 단계를 여전히 검증할 수 있지만, 이러한 유연성에는 신뢰성, 비용 및 실행 시간 측면에서의 트레이드오프(Tradeoff)가 따르며, 이에 대해서는 다음 섹션에서 살펴보겠습니다.
문제점
에이전트 기반 E2E 테스트는 유망해 보이지만, 실제적인 의문을 제기합니다. 실행당 15~30달러의 비용이 들고 10분 이상 걸리는 것이 현대적인 테스트 워크플로우에 실제로 적합할까요?
언뜻 보기에 대답은 '아니오'인 것 같습니다. 하지만 200회 이상의 실행을 통해 우리는 이것이 전통적인 테스트와 근본적으로 다르다는 것을 발견했습니다. 에이전트 기반 테스트는 매우 높은 신뢰성을 가질 수 있으며 테스트 스택에서 명확한 자리를 차지할 수 있습니다.
이는 에이전트가 코드를 작성하고, 실패를 디버깅하며, 사용자 인터페이스와 직접 상호작용할 수 있게 해주는 대규모 언어 모델(LLM)의 최근 발전 덕분입니다. 이러한 기능은 테스트를 위한 새로운 실행 모델을 도입하지만, 기존 E2E 워크플로우의 어디에 적합한지는 항상 명확하지 않습니다.
2. 실험 내용
에이전트 기반 테스트가 E2E 워크플로우에 어떻게 적합한지 이해하기 위해, 우리는 신뢰성, 실행 속도 및 비용을 측정하고자 여러 구성에 걸쳐 200회 이상의 자동화된 실행을 수행했습니다.
실행 모델 (Execution models)
우리는 세 가지 다른 접근 방식을 평가했습니다.
- 에이전트 + Playwright MCP 에이전트는 영구적인 컨텍스트(DOM 스냅샷 및 로그)와 함께 미리 정의된 브라우저 작업(요소 클릭, 입력 타이핑, DOM 상태 읽기 등)을 사용하여 Playwright MCP를 통해 브라우저와 상호작용합니다.
- 에이전트 + Playwright CLI 에이전트는 셸을 통해 Playwright CLI 명령을 실행하여 브라우저와 상호작용하며, 한 번에 한 단계씩 실행하고 업데이트된 UI 상태에 따라 다음 작업을 결정합니다.
- 생성된 Playwright 테스트 AI 에이전트가 자연어 설명으로부터 결정론적인 Playwright 테스트 코드를 생성하고, 이를 표준 E2E 테스트로 실행하며, 통과할 때까지 반복적으로 수정합니다.
실험 설정
- 에이전트 모델 (Playwright MCP / CLI): Claude Sonnet 4.5
- 생성된 Playwright 테스트에 사용된 모델: Claude Opus 4.6
- 실행: 비대화형 Claude Code (
claude -p)
- 브라우저 도구:
- Playwright MCP
- Playwright CLI
- 환경 설정:
- Slack Dev API MCP
- 모든 실험은 비프로덕션 데이터를 사용하는 테스트 워크스페이스에서 수행되었습니다.
테스트 플로우 (Test flows)
다양한 복잡도를 다루기 위해 두 가지 플로우를 사용했습니다. 직접적인 비교가 가능하도록 모든 실험에서 이 플로우들을 일관되게 유지했습니다.
- 스레드 답장 (단순): 채널 생성, 메시지 전송, 스레드 답장 및 스레드 상태 확인을 포함하는 짧은 워크플로우 (~15–20단계)
- 검색 탐색 (중간 복잡도): 검색어 입력, 결과 탐색, 뷰 간 이동(검색, 채널, 스레드) 및 예상 결과 확인을 포함하는 긴 워크플로우 (~25–30단계)
입력 형식 (Input formats)
에이전트 기반 접근 방식에 대해 두 가지 입력 유형을 평가했습니다.
- 자연어 (NL): 워크플로우와 예상 결과를 설명하는 상세하고 사람이 읽을 수 있는 지침(예: "스레드에 답장하고 '모든 스레드'에 나타나는지 확인")으로, 종종 단계별 목록으로 작성됩니다.
- 구조화된 YAML: 명시적인 단계, 작업, 대상 및 예상 결과가 포함된 구조화된 형식으로 표현된 동일한 워크플로우입니다.
차이점은 세부 정보의 수준이 아니라 그 세부 정보가 어떻게 표현되느냐에 있습니다. 자연어는 에이전트가 지침을 해석하고 작업에 매핑해야 하는 반면, YAML은 해당 매핑을 더 명시적으로 정의합니다.
각 구성은 20회씩 실행되었습니다. 아래 실험 매트릭스는 전체 설정을 보여줍니다.
실험 매트릭스
실험 | 실행 모델 | 입력 유형 | 도구 | 스레드 답장 | 검색 탐색 |
|---|---|---|---|---|---|
1 | 에이전트 (Playwright MCP) | NL | MCP | 20 | 20 |
2 | 에이전트 (Playwright MCP) | YAML | MCP | 20 | 20 |
3 | 에이전트 (Playwright CLI) | NL | CLI | 20 | 20 |
4 | 에이전트 (Playwright CLI) | YAML | CLI | 20 | 20 |
5 | 에이전트 (생성된 테스트) | NL | Code | 20 | 20 |
3. 관찰 결과
결과 요약
개별 지표를 살펴보기 전에, 자연어 및 YAML 기반 실행 모두에서 다양한 접근 방식이 전반적으로 어떻게 수행되었는지 간략히 살펴보겠습니다.
접근 방식 | 실패율 (스레드 답장) | 실패율 (검색 탐색) | 평균 실행 시간 |
|---|---|---|---|
에이전트 (Playwright MCP) | 0% | ~12% | ~5–8분 |
에이전트 (Playwright CLI) | ~12% | ~20% | ~9–11분 |
생성된 Playwright 테스트 | ~8% | ~48% | ~3분 |
다음 섹션에서는 이러한 결과를 개별 지표별로 분석합니다.
신뢰성 (Reliability)
우리가 본 가장 명확한 패턴 중 하나는 플로우가 복잡해짐에 따라 신뢰성이 어떻게 변하는가였습니다.
에이전트 기반 Playwright 플로우 중에서 Playwright MCP가 더 신뢰할 수 있는 구성이었으며, 단순한 시나리오에서는 거의 0%에 가까운 실패율을 일관되게 달성했고 복잡한 플로우에서도 012% 이내를 유지했습니다. 반면, Playwright CLI는 더 높은 실패율(약 1220%)을 보였으며, 많은 실패가 모델의 추론보다는 인증 처리, 탐색 타이밍, 세션 불안정성과 같은 실행 문제로 인해 발생했습니다.
생성된 Playwright 테스트는 단순한 플로우에서는 상당히 잘 수행되었으나(~8% 실패율), 더 복잡한 워크플로우에서는 성능이 크게 저하되었습니다(48%). 이 테스트들이 완전히 틀린 것은 아니었습니다. 일반적으로 플로우의 7080%까지 진행되다가 마지막 상호작용이나 단언에서 중단되었기 때문입니다. 실패는 주로 UI 상태의 가변성과 추상화 불일치로 인해 발생했습니다. 이 테스트들은 느슨하게 정의된 자연어 플로우에서 생성되었고 기존의 페이지 오브젝트(Page Object) 추상화를 재사용했는데, 이것이 때때로 더 복잡한 시나리오에서 정밀한 요소 타겟팅을 방해했습니다.
전반적으로 복잡성이 증가함에 따라 신뢰성 격차가 벌어졌으며, 이는 MCP와 같은 에이전트 네이티브 실행 모델이 플로우가 어려워질수록 더 안정적인 동작을 제공함을 시사합니다. 한 가지 유력한 이유는 각 모델이 상태를 처리하는 방식입니다. MCP는 앱의 실시간적이고 안정적인 뷰를 유지하는 반면, CLI는 매 단계마다 스냅샷으로부터 상태를 재구축합니다. 플로우가 길어질수록 UI가 해석되거나 타이밍이 맞춰지는 방식에서의 작은 불일치가 누적되어 실패로 이어질 수 있습니다. 또 다른 요인은 세션 내 컨텍스트입니다. MCP 기반 실행에서 에이전트는 동일한 플로우의 이전 단계에서 성공한 상호작용을 재사용하는 것으로 보이는 반면, CLI는 매 단계마다 처음부터 시작하는 것처럼 느껴질 수 있습니다. 이를 명시적으로 측정하지는 않았지만, 이 또한 격차에 기여했을 수 있습니다.
속도 (Speed)
속도 면에서는 생성된 테스트가 일관되게 가장 빨랐습니다.
접근 방식 | 평균 소요 시간 |
|---|---|
생성된 Playwright 테스트 | ~3분 |
에이전트 (Playwright MCP) | ~5–8분 |
에이전트 (Playwright CLI) | ~9–11분 |
생성된 테스트의 경우, 실행 시간은 테스트 생성과 실행을 모두 포함합니다. 각 테스트는 한 번 생성되어 다섯 번 실행되었으며, 위의 수치는 실행당 평균 소요 시간을 반영합니다. 실제로 순수 실행 시간은 훨씬 빨랐습니다(스레드 답장 약 32초, 검색 탐색 약 45초). 테스트가 반복적으로 실행되는 CI 환경에서는 일회성 생성 비용이 무시할 수 있는 수준이 되어, 결정론적 테스트가 더 효율적으로 확장될 수 있습니다.
에이전트 기반 워크플로우는 매 실행마다 이 비용을 지불합니다. 각 단계는 일반적으로 다음을 포함합니다.
- UI 상태 관찰
- 다음 작업에 대한 추론
- 작업 실행 및 결과 검증
적응성 (Adaptability)
우리가 발견한 또 다른 패턴은 에이전트가 UI를 탐색하는 방식이 얼마나 다른가였습니다.
실행 중 약 20%만이 정확히 동일한 작업 순서를 따랐습니다. 대부분의 실행에서 에이전트는 동일한 목표에 도달하기 위해 서로 다른 유효한 UI 경로를 찾아냈습니다.
예를 들어, 동일한 최종 상태에 도달하더라도 에이전트는 다음과 같이 행동할 수 있습니다.
- 다른 순서로 메뉴 열기
- 약간 다른 UI 요소 선택
- 대체 탐색 플로우 사용
이를 측정하기 위해 우리는 실행 간의 작업 시그니처(Action signature)를 비교했습니다. 작업 시그니처는 에이전트가 수행한 도구 호출 및 UI 작업(예: API 호출, 브라우저 클릭, 폼 상호작용)의 순서가 지정된 목록입니다. 비교 전에 작업 시그니처를 정규화했습니다. 매개변수, 대기/스냅샷 작업 및 동등한 도구 변체(예: fill vs type)를 축소하여 작업 시퀀스의 의미 있는 차이만 계산되도록 했습니다.
최종 결과가 올바른 경우에도 대부분의 작업 시퀀스가 달랐습니다. 이는 접근 방식 간의 핵심적인 차이점을 강조합니다. 전통적인 E2E 테스트는 UI를 통한 단일한 결정론적 여정을 강제하는 반면, 에이전트는 인터페이스를 탐색하고 목표 상태에 여전히 도달할 수 있는지 검증합니다.
비용과 발생 원인 (Cost and Where It Comes From)
실험에서 비용이 두드러졌습니다. 에이전트 기반 실행은 일반적으로 실행당 15~30달러였으며, 이는 훨씬 저렴한 전통적인 테스트 실행과 대조됩니다.
비용이 어디에서 발생하는지 이해하기 위해, 동일한 검색 탐색 플로우를 실행하여 다양한 실행 모델의 토큰 사용량을 분석했습니다.
접근 방식 | 토큰 수 |
|---|---|
MCP (Opus 4.6) | ~3.8M |
MCP (Sonnet 4.5) | ~3.5M |
MCP (Haiku 4.5) | ~5.7M |
CLI (Opus 4.6) | ~6M |
Code Gen (Opus 4.6) | ~7M |
가장 먼저 눈에 띈 점은 어떤 모델이 구동하느냐보다 에이전트가 어떻게 실행되느냐가 더 중요하다는 것이었습니다. 우리 실행에서 Haiku가 Sonnet이나 Opus보다 더 많은 토큰을 사용하긴 했지만, 모든 MCP 기반 접근 방식은 동일한 플로우에 대해 CLI 및 Code Gen 방식보다 전반적으로 적은 토큰을 사용했습니다.
그 이유를 이해하기 위해 Claude Code가 에이전트 세션을 실행하는 방식을 살펴보았습니다. 기본 API는 상태가 없으며(Stateless), 매 턴마다 전체 시스템 프롬프트와 대화 기록 전체를 다시 보냅니다. 즉, 비용은 무시할 수 있는 수준인 모델 출력에 의해 결정되는 것이 아니라, 컨텍스트가 얼마나 빨리 누적되는지와 에이전트가 플로우를 완료하는 데 몇 턴을 소비하는지에 의해 결정됩니다.
접근 방식 | 턴(Turn) 수 |
|---|---|
MCP (Opus 4.6) | ~40 |
MCP (Sonnet 4.5) | ~40 |
MCP (Haiku 4.5) | ~60 |
CLI (Opus 4.6) | ~85 |
Code Gen (Opus 4.6) | ~70 |
평균적으로 CLI는 MCP의 약 40~60턴에 비해 85턴이 걸렸는데, 이는 각 브라우저 상호작용이 작업, 대기, 스냅샷, 읽기 및 요소 조회와 같은 여러 명령으로 나뉘었기 때문입니다. MCP는 상호작용과 상태 반환을 단일 왕복으로 결합했습니다. 추가되는 매 턴마다 전체 시스템 프롬프트 비용을 지불하고 이전의 모든 대화 컨텍스트를 다시 보냅니다.
그 컨텍스트를 채우는 것은 무엇일까요? MCP 및 CLI 접근 방식의 경우 브라우저 스냅샷이 주요 페이로드입니다. Playwright MCP는 브라우저 상호작용 응답의 일부로 접근성 트리(Accessibility tree) 스냅샷을 반환하며, 이는 이후 모든 턴의 대화 윈도우(Window)에 누적됩니다. Code Gen의 경우, 누적된 컨텍스트는 각 재시도 주기마다 전체 오류 추적, 단언 실패 및 DOM 상태를 포함하는 테스트 러너 출력에서 발생합니다.
우리의 분석에 따르면, 비용의 대부분은 이전에 확인된 콘텐츠의 재전송이었습니다. 턴당 새로운 정보를 나타내는 토큰은 아주 적은 부분이었습니다. 비용에 영향을 미치는 가장 큰 요인은 모델의 추론이나 출력 생성이 아니라 턴 수와 컨텍스트 증가율입니다.
이 단계에서 우리는 주로 신뢰성과 동작에 집중했기 때문에 토큰 사용량은 최적화되지 않았습니다. 비용을 줄일 수 있는 기회로는 프롬프트 캐싱, 컨텍스트 압축 및 스냅샷 빈도 감소 등이 있습니다.
비용 문제로 인해 에이전트 기반 테스트는 현재 빈번한 CI 실행보다는 타겟팅된 디버깅이나 탐색적 테스트에 더 적합할 수 있지만, 향후 모델과 도구의 발전으로 비용은 개선될 수 있습니다.
인프라의 중요성 (MCP vs CLI)
또 다른 중요한 시사점은 모델 자체뿐만 아니라 실행 환경이 신뢰성에 얼마나 큰 영향을 미치는지였습니다.
접근 방식 | 실패율 |
|---|---|
에이전트 (Playwright MCP) | 0–12% |
에이전트 (Playwright CLI) | 12–20% |
CLI 기반 실행에서의 대부분의 실패는 인증 및 탐색 문제(로그인 오류, 타임아웃 및 세션 불안정성)에서 발생했으며, 이는 많은 실패가 에이전트의 추론보다는 실행 계층에 의해 발생했음을 시사합니다.
Playwright MCP는 구조화된 브라우저 프리미티브(Primitives)와 에이전트의 도구 호출 워크플로우와의 긴밀한 통합을 제공하는 반면, CLI 기반 실행은 에이전트와 브라우저 사이에 추가적인 계층을 도입합니다.
병렬화 측면에서도 차이가 있었습니다. MCP 실행은 동시에 실행하기 쉬웠지만, CLI 기반 실행은 우리 설정에서 병렬화하기 어려웠고 대부분 순차적으로 실행되었습니다.
이러한 결과는 신뢰성, 속도 및 비용이 모델뿐만 아니라 실행 환경이 얼마나 안정적이고 잘 설계되었는지에 달려 있음을 보여줍니다.
실행 능력의 경계 (Execution Capability Boundaries)
우리의 실험은 단일 세션 UI 워크플로우에 집중했습니다. 교차 워크스페이스 플로우나 여러 브라우저 윈도우를 여는 워크플로우와 같은 더 복잡한 시나리오는 에이전트 자체만큼이나 실행 모델의 선택이 중요한 또 다른 과제를 제기합니다.
MCP와 CLI 기반 접근 방식 모두 이러한 워크플로우를 지원할 수 있지만 트레이드오프가 다릅니다. MCP는 긴 플로우에 따라 관찰 루프가 커지면서 비용 문제가 발생할 수 있고, CLI 기반 접근 방식은 우리 실험에서 관찰된 높은 토큰 사용량 외에도 여러 브라우저 세션을 관리할 때 추가적인 조정 복잡성이 발생할 수 있습니다. 여기서는 이러한 시나리오를 탐구하지 않았지만, 에이전트 기반 테스트를 평가하는 팀에게는 중요한 고려 사항입니다.
4. 테스트 피라미드에서 에이전트 기반 테스트의 위치
그렇다면 에이전트 기반 테스트는 실제로 어디에 적합할까요?
기존의 접근 방식을 대체하기보다는 그 위에 새로운 기능을 추가합니다.
결정론적 E2E 테스트
CI에서 빠르고 반복 가능한 회귀 테스트(Regression check)에 가장 적합합니다.
- 사람이 작성하거나 AI가 생성한 테스트
- 빠르고 반복 가능하며 CI 친화적임
- 낮은 운영 비용
- UI를 통한 특정 여정을 강제함
에이전트 기반 테스트 (Agentic Testing)
에이전트 기반 워크플로우는 결정론적 테스트와 다르게 작동합니다. 미리 정의된 스크립트를 실행하는 대신, 에이전트는 목표를 가지고 작동합니다. UI를 관찰하고, 현재 상태를 추론하며, 원하는 결과에 도달하는 방법을 결정합니다.
- 복잡한 UI 동작 탐색
- 불안정한(Flaky) 워크플로우 디버깅
- 프로덕션 버그 재현
에이전트 계층이 포함된 테스트 피라미드
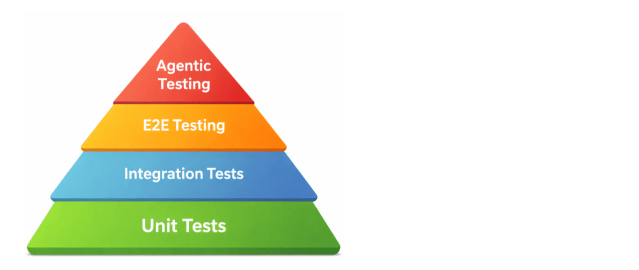
단위 테스트, 통합 테스트, E2E 테스트, 에이전트 기반 테스트의 네 가지 계층으로 구성된 테스트 피라미드
시스템 관점에서 에이전트 기반 테스트는 여전히 E2E 테스트와 동일한 수준에서 작동하며 UI를 통해 실제 사용자 워크플로우를 검증합니다. 차이점은 해당 워크플로우가 실행되는 방식에 있습니다.
이러한 이유로 미래의 가장 효과적인 테스트 전략은 두 가지를 결합하는 것이 될 것입니다. 결정론적 테스트는 CI를 위한 안정적인 기반을 제공하고, 에이전트 기반 테스트는 탐색, 디버깅 및 복잡한 동작 검증을 위해 테스트 피라미드 상단에 별도의 계층을 추가합니다.
5. 감사의 말
Claude Code와 같은 도구뿐만 아니라 이러한 실험을 가능하게 한 지표 인프라를 구축하고 지원해 준 DevXP AI 팀에 깊은 감사를 드립니다. 그 토대 덕분에 수백 건의 실행을 수행하고 분석하며 반복하는 것이 훨씬 쉬웠습니다.
토큰 카운터를 확실히 바쁘게 만들고 잠시 동안 내부 토큰 사용량 리더보드에 이름을 올릴 수 있을 정도의 규모로 실험을 지원해 준 매니저 Dave Harrington과 Vani Anantha에게 특별한 감사를 전합니다.
또한 초기 아이디어부터 검증 및 피드백에 이르기까지 과정 전반에 걸쳐 도움을 준 Frontend Test Frameworks 팀에게도 감사를 표하고 싶습니다. 사려 깊은 의견과 지원을 아끼지 않은 Lucy Cheng, Natalie Stormann, Roopa Thanisraj, Ilaria Varriale, Crescencio Zul에게 특별한 감사를 전합니다.
실제 문제를 해결하고, 개발자의 삶을 더 편리하게 만들거나, 멋진 도구를 만드는 데 관심이 있으신가요? 테스트의 경계를 넓히는 일이든, 에이전트 기반 시스템을 구축하고 개발자 워크플로우를 재고하는 일이든, 이런 종류의 업무가 흥미롭다면 우리는 채용 중입니다.
0
3
댓글
?
아직 댓글이 없습니다.
첫 번째 댓글을 작성해보세요!
Inkyu Oh님의 다른 글
더보기
번역
JavaScript를 활용한 의도적인 렌더링 차단
Inkyu Oh • Front-End
0
0
5

번역
accept 속성이 파일 업로드 UX를 저하시키는 이유
Inkyu Oh • UI/UX
0
0
4