AI를 언제 신뢰해야 할까? 매직 8볼 사고방식
I
Inkyu Oh
AI & ML-ops•2025.11.19
Nielsen Norman Group 블로그 포스트 번역
2024년 8월 16일
요약: genAI 도구를 과도하게 신뢰하기는 쉽습니다. 검증할 수 있거나 사실이라고 인식할 수 있는 정보만 사용하세요.
개요
생성형 인공지능(genAI)은 UX 실무자들에게 실질적인 응용 가능성을 제공합니다. 연구 계획, 부서 간 커뮤니케이션, 아이디어 도출 및 기타 작업을 가속화할 수 있습니다. GenAI는 또한 음성 전사와 같은 노동 집약적 활동을 간소화했습니다. 그러나 genAI의 모든 사용과 구현에는 어두운 그림자가 드리워져 있습니다 — 우리가 이를 신뢰할 수 있을까요?
목차
환각 현상
GenAI 도구는 간단한 작업을 수행할 때도 일관되게 실수를 합니다. 이러한 실수의 결과는 무해한 것부터 재앙적인 것까지 다양합니다. Stanford의 Varun Magesh와 동료들의 연구에 따르면, AI 기반 법률 도구는 시간의 17%에서 33% 사이에 부정확하고 거짓된 정보를 보고합니다. Salesforce genAI 대시보드에 따르면, 주요 채팅 도구의 부정확성 비율은 최선의 경우에도 13.5%에서 19% 사이입니다. GenAI 출력에서 비롯된 이러한 실수들은 종종 "환각 현상"이라고 불립니다.
GenAI 환각 현상의 주목할 만한 사례들:
- Google의 AI Overviews 기능은 피자를 구운 후 치즈가 미끄러지는 것을 방지하기 위해 피자에 무독성 접착제 1/4컵을 재료로 사용하도록 권장했습니다.
- 국립 섭식장애 협회는 사용자에게 섭식 장애 습관을 권장하는 챗봇을 구현했습니다.
- The Verge의 Alex Cranz에 따르면, Meta의 AI 이미지 생성 도구는 여성으로 정체성을 가진 저자의 사진을 만들도록 요청받았을 때 수염을 가진 남성처럼 보이는 사람들의 사진을 계속 생성했습니다.
환각 현상으로 인한 실수는 대규모 언어 모델(LLM, 대부분의 genAI 도구 뒤에 있는 기술)이 작동하는 방식에서 비롯됩니다. LLM은 확률 모델로 구축된 예측 엔진입니다. 이들은 이전에 나온 단어들을 살펴보고 이전에 본 데이터를 기반으로 다음에 올 가능성이 가장 높은 단어를 선택함으로써 작동합니다.
예를 들어, 다음 문장을 완성하도록 요청받는다면, 아마도 꽤 잘 할 수 있을 것입니다:
"The quick brown fox jumps over the lazy …"
영어를 사용한다면, 아마도 "dog"이라는 단어로 답할 것입니다. 왜냐하면 이것이 이 문장의 끝에 올 가능성이 가장 높은 단어이기 때문입니다. 이 문장은 유명하게도 영어 알파벳의 모든 글자를 사용합니다. 그러나 이 문장의 끝에 올 것으로 예상한 단어가 "dog"이 아니라 "cat"일 가능성은 작습니다.
LLM은 인터넷의 모든 구석에서 나온 학습 데이터에 노출되어 있기 때문에(저작권이 있든 없든), 인류 역사 전반에 걸쳐 사람들이 작성한 문장의 광범위한 예제에서 음절 간의 연관성을 학습하여 사용자의 요청에 유연하게 대응할 수 있는 인상적인 능력을 갖게 됩니다. 그러나 이러한 모델은 진실, 세계, 또는 생성하는 단어의 의미에 대한 내재된 이해가 없습니다. 대신 이들은 부드러운 단어 모음을 생성하도록 구축되어 있으며, 예측의 정확성을 전달하거나 검증할 인센티브가 거의 없습니다.
"환각 현상"이라는 용어는 종종 LLM이 만드는 실수를 설명하는 데 사용되지만, Ars Technica의 Benj Edwards가 제안하는 대로, 이러한 실수를 "창의적 공백 채우기" 또는 "거짓 기억"이라고 설명하는 것이 더 정확할 수 있습니다.
명확히, AI 모델의 진실을 측정할 수 없다는 것은 문제입니다. 기술 임원진과 개발자 모두 AI 환각 현상 문제가 곧 해결될 것이라는 확신이 거의 없습니다. 이러한 모델은 극도로 강력하지만, 확률적이고 생성적이며 예측적인 구조로 인해 환각 현상에 취약합니다. 개선된 모델이 출시되면서 환각 현상 비율이 감소했지만, 환각 현상 문제에 대해 제안된 모든 해결책은 부족했습니다.
따라서 genAI 제품의 사용자가 각 출력의 정확성과 타당성을 평가하고 판단할 책임이 있습니다. 그렇지 않으면 사용자가 "올바른 답처럼 보이는" 거짓 기억 정보에 따라 행동할 수 있습니다. 사용 맥락에 따라 환각 현상의 결과는 무의미할 수도 있고 영향력 있을 수도 있습니다. 인간이 비판적으로 AI 생성 정보를 받아들일 때, 그것이 매직 8볼 사고방식입니다.
매직 8볼 사고방식이란?
Rosenfeld Advancing Research Conference에서의 최근 강연에서, Meta의 전직 전략 UX 연구원이자 AI 기반 고객 인사이트 제품인 Altis의 창립자인 Savina Hawkins는 genAI 출력을 액면 그대로 받아들이고 이를 신뢰하며 이에 따라 행동하는 것을 의미하는 "매직 8볼 사고방식"이라는 용어를 만들었습니다.
매직 8볼 사고방식은 AI 생성 인사이트를 비판적으로 검토하지 않고 받아들이는 경향으로, 이를 학습 데이터와 모델 가중치를 기반으로 한 확률적 출력이 아닌 진실로 취급하는 것입니다.
매직 8볼은 초대형 큐볼처럼 스타일링된 플라스틱 공으로, 각 면에 다양한 진술이 있는 떠다니는 20면 주사위를 포함하고 있으며, 종종 조언을 구하거나 운세를 예측하는 데 사용됩니다.
간단히 말해, 매직 8볼 사고방식은 사용자가 genAI 제품에서 받은 답변을 검증하는 것을 멈추고 대신 답변을 신뢰할 때 발생합니다.
GenAI 제품 사용자는 다음의 경우에 가장 가능성 높게 매직 8볼 사고방식에 빠집니다:
- 개인적 전문 지식(그리고 진실을 인식할 수 있는 능력) 범위 밖의 작업이나 주제에 AI를 사용할 때
- genAI 시스템과의 상호작용 중에 자신의 지능이나 능력에 적극적으로 참여하지 못할 때
- genAI의 능력이 현실적인 것보다 더 높다고 가정할 때
- genAI 제품에서 좋고 현실적인 답변을 받은 후 안주할 때
사용자들은 여러 이유로 AI 도구에 대해 과도한 신뢰를 가지는 경향이 있으며, 그 중 하나가 ELIZA 효과입니다. NN/g가 최근에 수행한 일기 연구는 사용자들이 AI 도구에 대해 높은 수준의 신뢰를 가지고 있음을 확인합니다.
매직 8볼 사고방식을 어떻게 피할 수 있을까?
생성형 AI 도구는 지루한 작업을 줄이고 기술 격차를 메우는 데 훌륭하지만, 이러한 도구에 대한 신뢰를 과도하게 확장하거나 능력을 과대평가하지 않도록 주의하세요. 사용자는 자신의 지식과 기술을 사용하여 AI의 출력을 확인할 수 있는 범위 내에서만 genAI와 상호작용해야 합니다.
사용자가 정확성을 위해 결과를 어떻게 확인할 수 있을까요? 이것은 어려운 질문입니다. 검증할 수 있거나 사실이라고 인식할 수 있는 정보만 사용하세요. 광범위한 전문 지식의 범위 내에 머물러 있으세요. genAI에 너무 많이 의존하거나 주어진 응답의 타당성을 확인할 수 없다고 느낀다면, 매직 8볼 사고방식으로 빠져들 수 있습니다 — 블랙박스를 조금 너무 많이 신뢰하고 있을 수 있습니다.
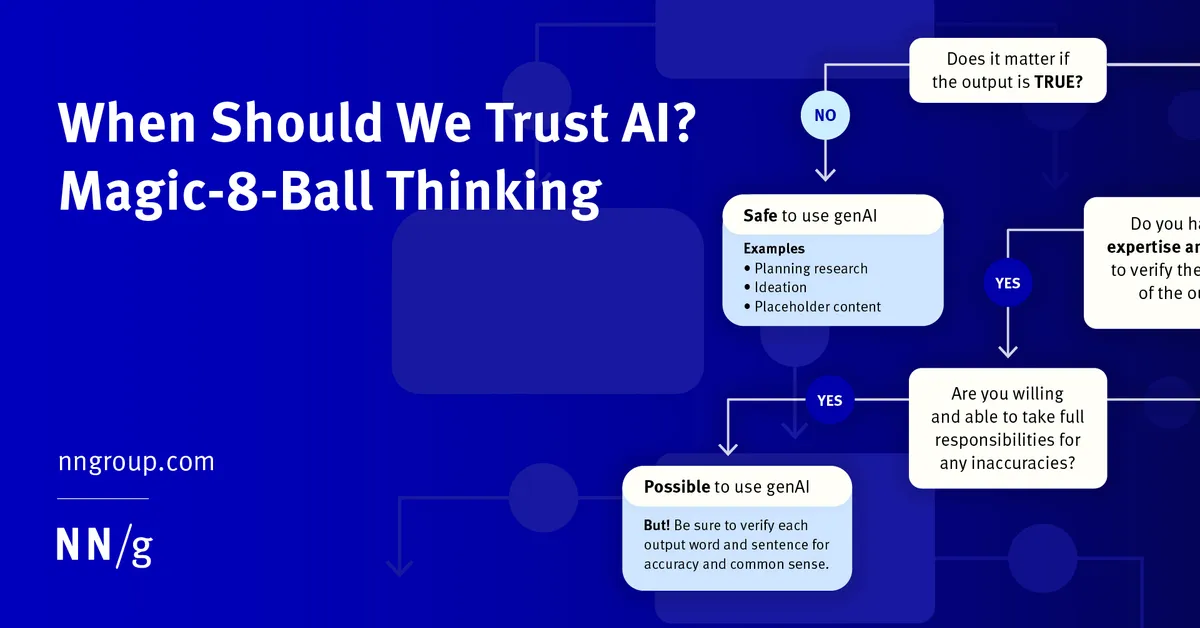
그러나 genAI에 대한 신뢰 수준이 덜 중요한 상황이 있습니다. 출력이 진실인지 여부가 중요하지 않다면 LLM의 출력을 확인할 필요가 없습니다. 예시로는 마케팅 또는 UX 카피, 플레이스홀더 텍스트, 또는 문서의 초안과 같은 "올바르게 보이는 텍스트" 생성이 포함됩니다. Lennart Meincke, Ethan Mollick, 그리고 Christian Terwiesch는 genAI의 아이디어 도출에서의 유용한 역할을 입증했으며, LLM의 대량의 아이디어 출력 능력을 활용하고 영리한 프롬프팅으로 제약을 두었습니다. 이러한 응용 프로그램은 유용성이 사실 정확성에 달려 있지 않기 때문에 매직 8볼 효과를 피할 수 있습니다.

특정 작업에 생성형 인공지능을 사용할지 결정하기 위해 출력이 사실인지 여부가 중요한지, 그리고 도구의 출력을 검증할 전문 지식이 있는지 자문해보세요. (Aleksandr Tiulkanov의 LinkedIn 포스트를 바탕으로 함)
사용자는 전문 지식, 시간, 그리고 LLM의 출력을 확인하고 검증할 능력이 있다면 진실성이 필요한 중요한 작업에 LLM을 사용할 수 있습니다. 사용자는 또한 부정확성에 대한 모든 책임을 질 수 있는 위치에 있어야 합니다. 예시:
- 전문가 연구원이 예정된 사용성 연구를 위한 인터뷰 질문을 생성합니다. 연구원은 출력을 검증하고 오류를 수정하기 위해 이를 수정하거나 편집할 수 있습니다.
- 정량적 UX 연구원이 LLM을 사용하여 통계 분석을 위한 코드를 작성합니다. 연구원은 정확한 구문을 알지 못할 수 있지만 출력 코드의 불가피한 오류를 포착할 수 있으며 AI가 올바른 통계 테스트를 선택했는지 인식할 수 있습니다.
AI를 작업의 완전한 대체물로 사용하지 마세요. 대신 이를 작업 속도를 높이고 번거로운 작업을 처리할 수 있지만 항상 출력을 확인해야 하는 보조자로 취급하세요.
이러한 모델은 항상 실수를 하기 때문에 당신의 전문 지식은 여전히 가치가 있습니다. UX 전문가는 좋은 정성적 판단을 내릴 책임이 있으며 그러한 기술을 개발했습니다. 이미 전문가라면 AI를 훨씬 더 효과적으로 사용할 수 있고 효율적이고 능숙하게 출력의 오류를 확인할 수 있습니다.
AI 도구가 생성하는 모든 것을 검증해야 한다는 요구 사항은 이러한 도구의 유용성을 제한합니다. 왜냐하면 이러한 도구를 사용하는 데 필요한 시간과 노력을 증가시키기 때문입니다. 또한 유용한 AI 지원이 어떤 모습인지에 대한 기준을 높입니다. genAI의 이점이 그 기능에 투자된 노력을 정당화할 만큼 높아야 합니다.
전문적 사용을 위해 도구를 채택할 때, 자신에게 물어봐야 합니다: 이것이 시간을 절약하나요? 이것이 가치가 있나요? 가상의 임원 보조자가 당신을 대신하여 보낸 모든 이메일을 검토해야 한다면, 직접 그 이메일을 작성하는 것이 더 나을 수 있습니다. AI도 마찬가지입니다.
매직 8볼 사고방식을 피하는 연습을 할 수 있는 상황의 예시들:
- genAI 도구로 책상 연구를 수행할 때, 검색과 함께 출처, 참고자료, 또는 URL을 요청하세요. 제공된 출처를 클릭하여 검증하세요. genAI 도구는 종종 주제와 무관한 출처를 인용하기 때문입니다.
- GenAI 도구는 정성적 데이터 분석을 가속화할 수 있습니다. genAI 도구에 정성적 인사이트를 원본 데이터에 다시 연결하도록 요청하여 매직 8볼 사고방식을 피하세요.
- 프로그래밍 및 정량적 분석 작업은 genAI로 크게 가속화될 수 있지만, genAI 도구가 만드는 모든 코드, 통계, 또는 시각화 선택을 검증해야 합니다.
- genAI 도구로 생성된 글을 먼저 검토하지 않고 직접 보내거나, 게시하거나, 공유하지 마세요.
AI 기능을 구축할 때 디자이너가 매직 8볼 사고방식을 고려해야 할까?
의도적이든 의도하지 않았든 사용자를 AI 환각 현상에 노출시키면 사용자가 실망하고 혼란스러워할 가능성이 생깁니다. 최악의 상황에서는 이러한 감정이 전체 제품에 대한 참여 감소 또는 포기로 악화될 수 있습니다. AI 환각 현상 비율이 여전히 지속적인 문제가 될 정도로 높은 동안, AI 통합을 위해 설계하는 전문가들은 사용자가 출력을 확인하거나 출력이 어디서 나왔는지 추적할 수 있도록 돕는 기능을 추가할 수 있습니다.
genAI 기능을 제품에 구현할 때, 사용자 연구를 수행하여 구현 맥락에서 사용자가 매직 8볼 사고방식에 빠질 가능성을 파악하세요. 제품의 AI 구현이 텍스트 기반 콘텐츠 생성을 포함한다면, 매직 8볼 사고방식을 방지하는 기능을 추가하는 것을 고려하세요.
이러한 기능의 예시:
- genAI 출력에 응답 생성에 사용된 정보 출처에 대한 참고자료를 추가합니다(예: 인라인 인용, 출력 상단 또는 하단의 정보 카드, 또는 출처 보기 버튼 형태로).
- 지적 재산권 도용과 관련하여 비난받을 만한 행동에도 불구하고, Perplexity는 핵심 제품에서 출처로 응답에 주석을 다는 좋은 시연을 제공합니다.
- 정성적 연구 플랫폼인 Dovetail은 genAI를 사용하여 비디오 녹화본의 전사본을 요약합니다. 사용자가 출력을 확인할 수 있는 능력을 개선하기 위해 Dovetail은 요약 내에 각 녹화본의 타임스탬프 섹션에 대한 링크를 제공합니다.
- 사용자가 genAI 응답의 맥락 내에서 제품 내 전통적인 웹 또는 문헌 검색을 수행할 수 있도록 합니다.
- Google의 Gemini 채팅 제품은 응답 이중 확인 버튼을 포함하고 있으며, 이는 genAI의 출력을 평가하고 Gemini의 출력의 다양한 구성 요소에 대해 별도의 Google 검색을 확장할 드롭다운 옵션을 제공합니다.
참고자료
Tiulkanov, Aleksandr. 2023. A simple algorithm to decide whether to use ChatGPT, based on my recent article. LinkedIn. From https://www.linkedin.com/posts/tyulkanov_a-simple-algorithm-to-decide-whether-to-use-activity-7021766139605078016-x8Q9/ Anon. Neda on Instagram. Retrieved June 3, 2024 from https://www.instagram.com/p/Cs4BiC9AhDe/
Alex H. Cranz. 2024. We have to stop ignoring AI's hallucination problem. May 2024. The Verge. Retrieved June 3, 2024, from https://www.theverge.com/2024/5/15/24154808/ai-chatgpt-google-gemini-microsoft-copilot-hallucination-wrong
Benj Edwards. April 2023. Why AI chatbots are the ultimate BS machines—and how people hope to fix them. Ars Technica. Retrieved August 2, 2024 from https://arstechnica.com/information-technology/2023/04/why-ai-chatbots-are-the-ultimate-bs-machines-and-how-people-hope-to-fix-them/
Nico Grant. 2024. Google rolls back the AI search feature after Flubs and Flaws. June 2024. The New York Times. Retrieved June 3, 2024 from https://www.nytimes.com/2024/06/01/technology/google-ai-overviews-rollback.html
Hawkins, S. March 2024. Harnessing AI in UXR: Practical Strategies for Positive Impact. In Advancing Research 2024. Rosenfeld Media. Retrieved from https://rosenfeldmedia.com/advancing-research/2024/sessions/harnessing-ai-in-uxr-practical-strategies-for-positive-impact/
Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. October 2023. Halueval: A large-scale hallucination evaluation benchmark for large language models.. Retrieved June 21, 2024, from https://arxiv.org/abs/2305.11747
Varun Magesh, Faiz Surani, Matthew Dahl, Mirac Suzgun, Christopher D. Manning, and Daniel E. Ho. 2024. Hallucination-free? Assessing the reliability of leading AI Legal Research Tools. (May 2024). Retrieved June 21, 2024, from https://arxiv.org/abs/2405.20362
Dhruve Mehhrotra, Time Marchman, June 2024. Perplexity Is a Bullshit Machine. Wired. Retreived August 2, 2023 from https://www.wired.com/story/perplexity-is-a-bullshit-machine/
Lennart Meincke, Ethan Mollick, and Christrian Terwiesch, Februrary 2024. Prompting Diverse Ideas: Increasing AI Idea Variance. The Wharton School Research Paper. From https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4708466
Nilay Patel, May 2024. Google CEO Sundar Pichai on AI, search, and the future of the internet. The Verge. Retrieved August 2, 2024 from https://www.theverge.com/24158374/google-ceo-sundar-pichai-ai-search-gemini-future-of-the-internet-web-openai-decoder-interview
Salesforce AI Research. Generative AI benchmark for CRM. Retrieved June 21, 2024, from https://www.salesforceairesearch.com/crm-benchmark
Wikipedia. Hallucination (artificial intelligence). Retrieved August 2, 2024 from https://en.wikipedia.org/wiki/Hallucination_(artificial_intelligence)#Mitigation_methods
0
13
댓글
?
아직 댓글이 없습니다.
첫 번째 댓글을 작성해보세요!
Inkyu Oh님의 다른 글
더보기
번역
실제로 작동하는 간단한 검색 엔진 만들기
Inkyu Oh • Back-End
1
0
22
LLM에서의 인지적 프롬프팅
Inkyu Oh • AI & ML-ops
0
0
4

번역
React 19.2
Inkyu Oh • Front-End
0
1
63

Wasm은 WebAssembly의 약자가 아니다
Inkyu Oh • Front-End
1
0
64