[번역] AI 에이전트를 위한 좋은 사양서(Spec) 작성법
I
Inkyu Oh
AI & ML-ops•2026.01.22
Addy Osmani - 2025년 3월 10일
요약: AI를 압도하지 않으면서도 가이드가 될 수 있을 만큼의 뉘앙스(구조, 스타일, 테스트, 경계 포함)를 담은 명확한 사양서를 목표로 하세요. 모든 것을 하나의 거대한 프롬프트에 담기보다는 큰 작업을 작은 작업으로 쪼개야 합니다. 먼저 읽기 전용 모드에서 계획을 세운 다음, 실행하고 지속적으로 반복하세요.
“AI 에이전트를 위한 좋은 사양서 작성에 대해 많이 들어봤지만, 아직 확실한 프레임워크를 찾지 못했습니다. RFC에 필적하는 사양서를 작성할 수도 있겠지만, 어느 시점이 되면 컨텍스트가 너무 커져서 모델이 무너져 버립니다.”
많은 개발자가 이러한 좌절감을 공유합니다. 단순히 방대한 사양서를 AI 에이전트에게 던지는 것은 작동하지 않습니다. 컨텍스트 창(Context window)의 제한과 모델의 "주의력 예산(Attention budget)"이 걸림돌이 되기 때문입니다. 핵심은 스마트한 사양서를 작성하는 것입니다. 즉, 에이전트를 명확하게 안내하고, 실용적인 컨텍스트 크기 내에 머물며, 프로젝트와 함께 진화하는 문서를 만드는 것입니다. 이 가이드는 Claude Code 및 Gemini CLI를 포함한 코딩 에이전트를 사용하며 얻은 베스트 프랙티스를 사양서 작성 프레임워크로 정리하여, 여러분의 AI 에이전트가 집중력을 유지하고 생산성을 높일 수 있도록 돕습니다.
훌륭한 AI 에이전트 사양서를 위한 다섯 가지 원칙을 살펴보겠습니다. 각 원칙은 굵게 표시된 핵심 요약으로 시작합니다.
1. 상위 수준의 비전으로 시작하고 AI가 세부 사항을 초안으로 잡게 하세요
프로젝트를 간결하고 상위 수준의 사양서로 시작한 다음, AI가 이를 상세한 계획으로 확장하게 하세요.
처음부터 과도하게 엔지니어링하는 대신, 명확한 목표 선언과 몇 가지 핵심 요구 사항으로 시작하세요. 이를 "제품 브리프(Product brief)"로 취급하고 에이전트가 이를 바탕으로 더 정교한 사양서를 생성하도록 하세요. 이는 AI의 상세화 능력을 활용하면서도 여러분이 방향성을 통제할 수 있게 해줍니다. 이 방식은 처음부터 반드시 충족해야 하는 매우 구체적인 기술적 요구 사항이 이미 있는 경우가 아니라면 매우 효과적입니다.
효과적인 이유: LLM 기반 에이전트는 견고한 상위 수준의 지시가 주어졌을 때 세부 사항을 채우는 데 탁월하지만, 경로를 이탈하지 않으려면 명확한 미션이 필요합니다. 짧은 개요나 목표 설명을 제공하고 AI에게 전체 사양서(예: spec.md)를 작성하도록 요청함으로써, 에이전트를 위한 지속적인 참조 자료를 만들 수 있습니다. 에이전트를 사용할 때는 사전에 계획하는 것이 더욱 중요합니다. 먼저 계획을 반복해서 다듬은 다음, 에이전트에게 넘겨 코드를 작성하게 할 수 있습니다. 사양서는 여러분과 AI가 함께 만드는 첫 번째 결과물이 됩니다.
실용적인 접근법: "당신은 AI 소프트웨어 엔지니어입니다. [프로젝트 X]에 대해 목표, 기능, 제약 조건 및 단계별 계획을 포함하는 상세 사양서 초안을 작성해 주세요"라는 프롬프트로 새로운 코딩 세션을 시작하세요. 초기 프롬프트는 상위 수준으로 유지하세요. 예를 들어 "사용자 계정, 데이터베이스, 단순한 UI를 갖춘 사용자 작업 추적(할 일 목록) 웹 앱을 구축해 줘"와 같이 말이죠. 에이전트는 개요, 기능 목록, 기술 스택 제안, 데이터 모델 등이 포함된 구조화된 사양서 초안으로 응답할 것입니다. 이 사양서는 여러분과 에이전트 모두가 참조할 수 있는 "단일 진실 공급원(Source of truth)"이 됩니다. GitHub의 AI 팀은 "사양서 중심 개발(Spec-driven development)"을 장려하며, 여기서 "사양서는 공유된 진실 공급원이자... 프로젝트와 함께 진화하는 살아있는 실행 가능한 결과물"이 됩니다. 코드를 작성하기 전에 AI의 사양서를 검토하고 다듬으세요. 여러분의 비전과 일치하는지 확인하고 환각(Hallucination)이나 빗나간 세부 사항을 수정하세요.
계획 우선 원칙을 강제하기 위해 계획 모드(Plan Mode) 사용: Claude Code와 같은 도구는 에이전트를 읽기 전용 작업으로 제한하는 계획 모드를 제공합니다. 에이전트는 코드베이스를 분석하고 상세한 계획을 세울 수 있지만, 여러분이 준비될 때까지 코드를 작성하지 않습니다. 이는 계획 단계에 이상적입니다. 계획 모드(Claude Code에서 Shift+Tab)로 시작하여 구축하려는 내용을 설명하고, 에이전트가 기존 코드를 탐색하면서 사양서 초안을 작성하게 하세요. 계획에 대해 질문을 던져 모호한 부분을 명확히 하도록 요청하세요. 아키텍처, 베스트 프랙티스, 보안 리스크 및 테스트 전략에 대해 계획을 검토하게 하세요. 목표는 오해의 소지가 없을 때까지 계획을 다듬는 것입니다. 그제야 계획 모드를 종료하고 에이전트가 실행하게 합니다. 이 워크플로우는 사양서가 견고해지기 전에 바로 코드 생성으로 뛰어드는 흔한 함정을 방지합니다.
사양서를 컨텍스트로 사용: 승인되면 이 사양서를 저장하고(예: SPEC.md) 필요에 따라 관련 섹션을 에이전트에게 제공하세요. 강력한 모델을 사용하는 많은 개발자가 정확히 이 방식을 사용합니다. 사양서 파일은 세션 간에 유지되어 프로젝트 작업이 재개될 때마다 AI의 중심을 잡아줍니다. 이는 대화 기록이 너무 길어지거나 에이전트를 재시작해야 할 때 발생할 수 있는 망각 현상을 완화합니다. 이는 팀에서 제품 요구 사항 문서(PRD)를 사용하는 방식과 유사합니다. 즉, 모든 구성원(인간 또는 AI)이 궤도를 유지하기 위해 참조할 수 있는 기준이 됩니다. 숙련된 이들은 한 엔지니어가 관찰한 것처럼 "좋은 문서를 먼저 작성하면 모델이 그 입력만으로도 일치하는 구현체를 구축할 수 있을 것"이라고 말합니다. 사양서가 바로 그 문서입니다.
목표 지향성 유지: AI 에이전트를 위한 상위 수준 사양서는 (적어도 초기에는) 아주 세세한 방법보다는 '무엇을'과 '왜'에 집중해야 합니다. 이를 사용자 스토리와 수용 기준(Acceptance criteria)처럼 생각하세요. 사용자는 누구인가? 그들에게 필요한 것은 무엇인가? 성공적인 모습은 어떤 것인가? (예: "사용자는 작업을 추가, 편집, 완료할 수 있어야 함. 데이터는 영구적으로 저장되어야 함. 앱은 반응형이고 보안이 유지되어야 함"). 이렇게 하면 AI의 상세 사양서가 단순한 기술적 할 일 목록이 아니라 사용자 요구와 결과에 기반을 두게 됩니다. GitHub Spec Kit 문서에서 언급하듯이, 구축하려는 내용과 이유에 대한 상위 수준의 설명을 제공하고, 코딩 에이전트가 사용자 경험과 성공 기준에 집중하여 상세 사양서를 생성하게 하세요. 이러한 거시적인 비전으로 시작하면 에이전트가 나중에 코딩에 들어갔을 때 나무만 보고 숲을 놓치는 일을 방지할 수 있습니다.
2. 전문적인 PRD(또는 SRS)처럼 사양서를 구조화하세요
AI 사양서를 느슨한 메모 뭉치가 아니라 명확한 섹션이 있는 구조화된 문서(PRD)로 취급하세요.
많은 개발자가 에이전트를 위한 사양서를 전통적인 제품 요구 사항 문서(PRD)나 시스템 설계 문서처럼 다룹니다. 즉, 포괄적이고 잘 정리되어 있으며 "문자 그대로 받아들이는" AI가 파싱하기 쉽게 만듭니다. 이러한 공식적인 접근 방식은 에이전트에게 따를 수 있는 청사진을 제공하고 모호성을 줄여줍니다.
6가지 핵심 영역: 2,500개 이상의 에이전트 설정 파일에 대한 GitHub의 분석 결과 명확한 패턴이 드러났습니다. 가장 효과적인 사양서는 6가지 영역을 다룹니다. 이를 완전성을 위한 체크리스트로 사용하세요.
1. 명령어(Commands): 실행 가능한 명령어를 초기에 배치하세요. 단순한 도구 이름이 아니라 플래그가 포함된 전체 명령어를 넣으세요:
npm test, pytest -v, npm run build. 에이전트는 이를 지속적으로 참조할 것입니다.2. 테스트(Testing): 테스트 실행 방법, 사용하는 프레임워크, 테스트 파일 위치, 커버리지 기대치 등을 명시하세요.
3. 프로젝트 구조(Project structure): 소스 코드, 테스트, 문서가 어디에 위치하는지 명시하세요. "애플리케이션 코드는
src/, 유닛 테스트는 tests/, 문서는 docs/"와 같이 명확하게 작성하세요.4. 코드 스타일(Code style): 스타일을 설명하는 세 단락보다 스타일을 보여주는 실제 코드 스니펫 하나가 더 낫습니다. 명명 규칙, 포맷팅 규칙, 좋은 출력 예시를 포함하세요.
5. Git 워크플로우(Git workflow): 브랜치 명명 규칙, 커밋 메시지 형식, PR 요구 사항을 명시하세요. 명확히 기술하면 에이전트가 이를 따를 수 있습니다.
6. 경계(Boundaries): 에이전트가 절대 건드리지 말아야 할 것들(비밀번호/키, 벤더 디렉토리, 프로덕션 설정, 특정 폴더)을 명시하세요. "비밀번호/키를 절대 커밋하지 말 것"은 GitHub 연구에서 가장 흔하고 유용했던 제약 조건이었습니다.
스택을 구체적으로 명시하세요: "React 프로젝트"라고 하지 말고 "React 18, TypeScript, Vite, Tailwind CSS"라고 말하세요. 버전과 주요 종속성을 포함하세요. 모호한 사양서는 모호한 코드를 만듭니다.
일관된 형식을 사용하세요: 명확성이 생명입니다. 많은 개발자가 섹션을 구분하기 위해 Markdown 헤더나 XML 스타일의 태그를 사양서에 사용합니다. AI 모델은 자유 형식의 산문보다 잘 구조화된 텍스트를 더 잘 처리하기 때문입니다. 예를 들어 사양서를 다음과 같이 구조화할 수 있습니다.
# 프로젝트 사양서: 우리 팀의 작업 앱## 목표- 소규모 팀이 작업을 관리할 수 있는 웹 앱 구축...## 기술 스택- React 18+, TypeScript, Vite, Tailwind CSS- Node.js/Express 백엔드, PostgreSQL, Prisma ORM## 명령어- 빌드: `npm run build` (TypeScript 컴파일, dist/로 출력)- 테스트: `npm test` (Jest 실행, 커밋 전 반드시 통과해야 함)- 린트: `npm run lint --fix` (ESLint 오류 자동 수정)## 프로젝트 구조- `src/` – 애플리케이션 소스 코드- `tests/` – 유닛 및 통합 테스트- `docs/` – 문서## 경계- ✅ 항상 할 것: 커밋 전 테스트 실행, 명명 규칙 준수- ⚠️ 먼저 물어볼 것: 데이터베이스 스키마 변경, 종속성 추가- 🚫 절대 하지 말 것: 비밀번호/키 커밋, node_modules/ 수정, CI 설정 수정이러한 수준의 조직화는 여러분이 명확하게 생각하도록 도울 뿐만 아니라, AI가 정보를 찾는 데도 도움이 됩니다. Anthropic 엔지니어들은 바로 이러한 이유로 프롬프트를 별도의 섹션으로 구성(예: <background>, <instructions>, <tools>, <output_format> 등)할 것을 권장합니다. 이는 모델에게 어떤 정보가 무엇인지에 대한 강력한 단서를 제공합니다. 그리고 "최소한(Minimal)이라는 것이 반드시 짧아야 함을 의미하지는 않는다"는 점을 기억하세요. 중요하다면 사양서에 세부 사항을 적는 것을 주저하지 마되, 집중력을 유지하세요.
사양서를 툴체인에 통합하세요: 사양서를 버전 관리 및 CI/CD와 연결된 "실행 가능한 결과물"로 취급하세요. GitHub Spec Kit은 사양서를 엔지니어링 프로세스의 중심으로 만드는 4단계 게이트 워크플로우를 사용합니다. 사양서를 작성하고 치워두는 대신, 사양서가 구현, 체크리스트, 작업 분할을 주도하게 합니다. 여러분의 주요 역할은 조종하는 것이며, 코딩 에이전트가 대부분의 작성을 수행합니다. 각 단계에는 특정 작업이 있으며, 현재 작업이 완전히 검증될 때까지 다음 단계로 넘어가지 않습니다.
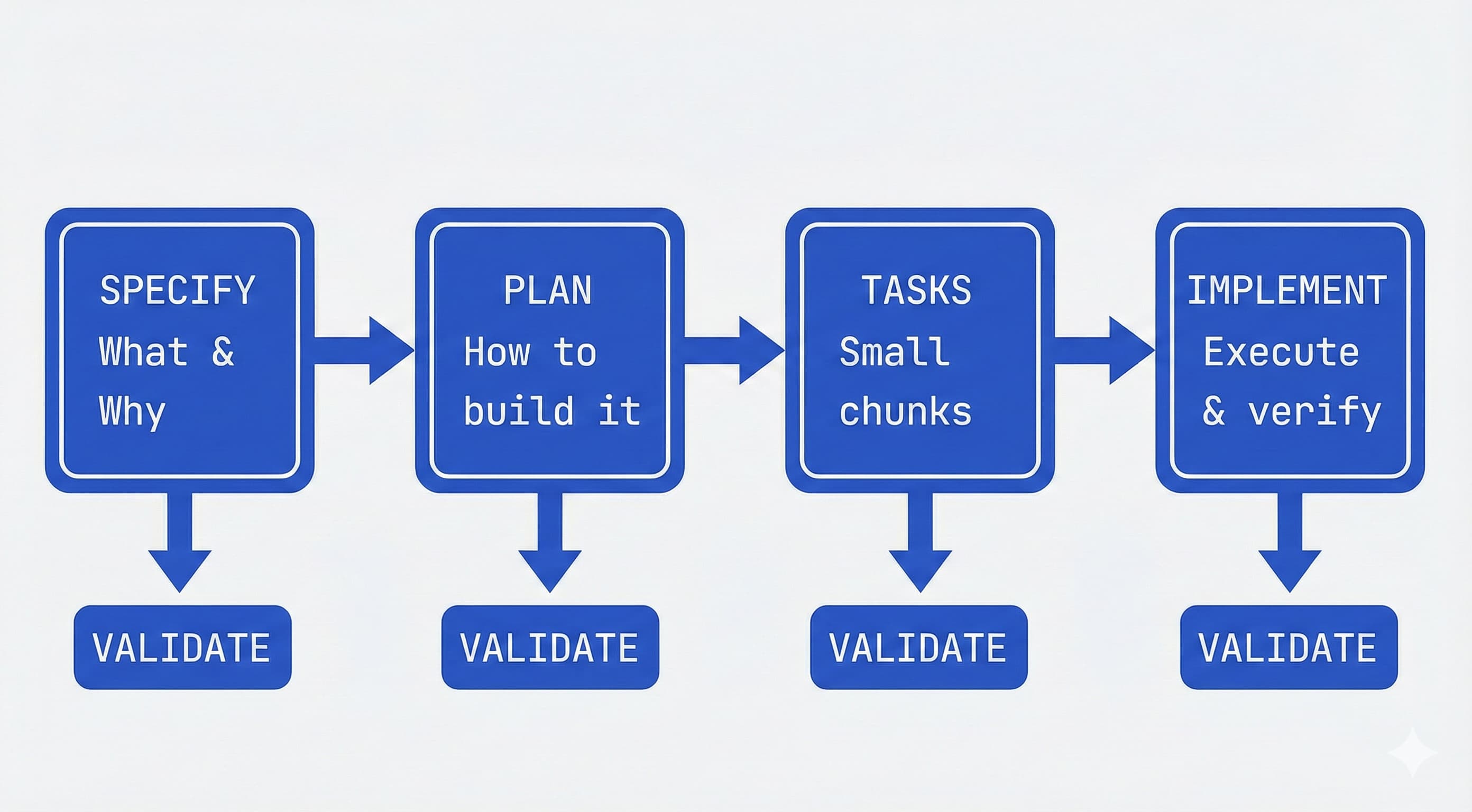
1. 명시(Specify): 구축하려는 내용과 이유에 대한 상위 수준의 설명을 제공하면 코딩 에이전트가 상세 사양서를 생성합니다. 이는 기술 스택이나 앱 디자인에 관한 것이 아니라, 사용자 여정, 경험, 그리고 성공이 무엇인지에 관한 것입니다. 누가 이것을 사용할 것인가? 어떤 문제를 해결하는가? 사용자는 어떻게 상호작용하는가? 이를 만들고자 하는 사용자 경험을 매핑하는 것으로 생각하고, 코딩 에이전트가 세부 사항을 채우도록 하세요. 이는 더 많은 것을 배우면서 진화하는 살아있는 결과물이 됩니다.
2. 계획(Plan): 이제 기술적인 단계입니다. 원하는 스택, 아키텍처, 제약 조건을 제공하면 코딩 에이전트가 포괄적인 기술 계획을 생성합니다. 회사가 특정 기술을 표준화했다면 여기서 언급하세요. 레거시 시스템과 통합하거나 규정 준수 요구 사항이 있다면 모두 여기에 포함됩니다. 여러 계획 변형을 요청하여 접근 방식을 비교할 수도 있습니다. 내부 문서를 제공하면 에이전트가 아키텍처 패턴을 계획에 직접 통합할 수 있습니다.
3. 작업(Tasks): 코딩 에이전트는 사양서와 계획을 가져와 실제 작업, 즉 각각 퍼즐의 특정 조각을 해결하는 작고 검토 가능한 덩어리로 나눕니다. 각 작업은 독립적으로 구현하고 테스트할 수 있는 것이어야 하며, 마치 AI 에이전트를 위한 테스트 주도 개발(TDD)과 같습니다. "인증 구축" 대신 "이메일 형식을 검증하는 사용자 등록 엔드포인트 생성"과 같은 구체적인 작업을 얻게 됩니다.
4. 구현(Implement): 코딩 에이전트가 작업을 하나씩(또는 병렬로) 처리합니다. 수천 줄의 코드 덤프를 검토하는 대신, 특정 문제를 해결하는 집중된 변경 사항을 검토하게 됩니다. 에이전트는 무엇을 구축할지(사양), 어떻게 구축할지(계획), 무엇을 작업할지(작업)를 알고 있습니다. 결정적으로, 여러분의 역할은 각 단계에서 검증하는 것입니다. 사양서가 원하는 바를 담고 있는가? 계획이 제약 조건을 고려하고 있는가? AI가 놓친 예외 케이스는 없는가? 이 프로세스는 여러분이 다음 단계로 넘어가기 전에 비판하고, 격차를 발견하고, 경로를 수정할 수 있는 체크포인트를 구축합니다.
이러한 게이트 워크플로우는 Willison이 말하는 "사상누각 코드(House of cards code)", 즉 정밀 조사 시 무너지는 취약한 AI 출력물을 방지합니다. Anthropic의 Skills 시스템도 유사한 패턴을 제공하여, 에이전트가 호출하는 재사용 가능한 Markdown 기반 동작을 정의할 수 있게 합니다. 사양서를 이러한 워크플로우에 내장함으로써, 사양서가 검증될 때까지 에이전트가 진행할 수 없도록 보장하고, 변경 사항이 작업 분할 및 테스트에 자동으로 전파되도록 합니다.
전문화된 페르소나를 위해 agents.md 고려: GitHub Copilot과 같은 도구의 경우, 전문화된 에이전트 페르소나를 정의하는 agents.md 파일을 만들 수 있습니다. 기술 문서를 위한 @docs-agent, QA를 위한 @test-agent, 코드 리뷰를 위한 @security-agent 등이 그 예입니다. 각 파일은 해당 페르소나의 동작, 명령어, 경계에 대한 집중된 사양서 역할을 합니다. 이는 하나의 범용 어시스턴트보다 작업별로 다른 에이전트를 원할 때 특히 유용합니다.
에이전트 경험(AX)을 위한 설계: 개발자 경험(DX)을 위해 API를 설계하는 것처럼, "에이전트 경험"을 위한 사양서 설계를 고려하세요. 이는 깨끗하고 파싱 가능한 형식을 의미합니다. 에이전트가 소비할 API를 위한 OpenAPI 스키마, LLM 소비를 위해 문서를 요약한 llms.txt 파일, 명시적인 타입 정의 등이 포함됩니다. Agentic AI Foundation(AAIF)은 도구 통합을 위해 MCP(Model Context Protocol)와 같은 프로토콜을 표준화하고 있습니다. 이러한 패턴을 따르는 사양서는 에이전트가 더 쉽게 소비하고 안정적으로 실행할 수 있습니다.
PRD vs SRS 마인드셋: 기존의 문서화 관행을 차용하는 것이 도움이 됩니다. AI 에이전트 사양서의 경우 종종 이 둘을 하나의 문서로 혼합하지만(위에서 설명한 대로), 두 관점을 모두 다루는 것이 좋습니다. PRD처럼 작성하면 사용자 중심의 컨텍스트("각 기능 뒤에 숨겨진 이유")를 포함하게 되어 AI가 엉뚱한 것을 최적화하지 않도록 보장합니다. SRS처럼 확장하면 AI가 실제로 정확한 코드를 생성하는 데 필요한 세부 사항(사용할 데이터베이스나 API 등)을 확정할 수 있습니다. 개발자들은 이러한 추가적인 사전 노력이 나중에 에이전트와의 의사소통 오류를 획기적으로 줄여준다는 것을 발견했습니다.
사양서를 "살아있는 문서"로 유지하세요: 작성하고 잊어버리지 마세요. 여러분과 에이전트가 결정을 내리거나 새로운 정보를 발견함에 따라 사양서를 업데이트하세요. AI가 데이터 모델을 변경해야 했거나 기능을 축소하기로 했다면, 사양서에 이를 반영하여 사양서가 항상 진실의 근거로 남게 하세요. 이를 버전 관리되는 문서로 생각하세요. 사양서 중심 워크플로우에서 사양서는 구현, 테스트, 작업 분할을 주도하며, 사양서가 검증될 때까지 코딩으로 넘어가지 않습니다. 이러한 습관은 특히 여러분이나 에이전트가 잠시 떠났다가 나중에 돌아왔을 때 프로젝트의 일관성을 유지해 줍니다. 사양서는 단지 AI만을 위한 것이 아닙니다. 개발자인 여러분이 감독을 유지하고 AI의 작업이 실제 요구 사항을 충족하는지 확인하는 데 도움이 됩니다.
3. 작업을 하나의 큰 프롬프트가 아닌 모듈식 프롬프트와 컨텍스트로 나누세요
분할 정복: 모든 것을 한꺼번에 담은 거대한 프롬프트 대신, AI에게 한 번에 하나의 집중된 작업을 제공하세요.
숙련된 AI 엔지니어들은 모든 프로젝트 내용(모든 요구 사항, 모든 코드, 모든 지침)을 단일 프롬프트나 에이전트 메시지에 밀어 넣으려는 시도가 혼란의 지름길이라는 것을 배웠습니다. 토큰 제한에 걸릴 위험이 있을 뿐만 아니라, 너무 많은 지시 사항으로 인해 모델이 그 중 어느 것도 제대로 따르지 못하게 되는 "지침의 저주(Curse of instructions)"로 인해 집중력을 잃을 위험도 있습니다. 해결책은 사양서와 워크플로우를 모듈식으로 설계하여, 한 번에 한 조각씩 처리하고 해당 조각에 필요한 컨텍스트만 끌어오는 것입니다.
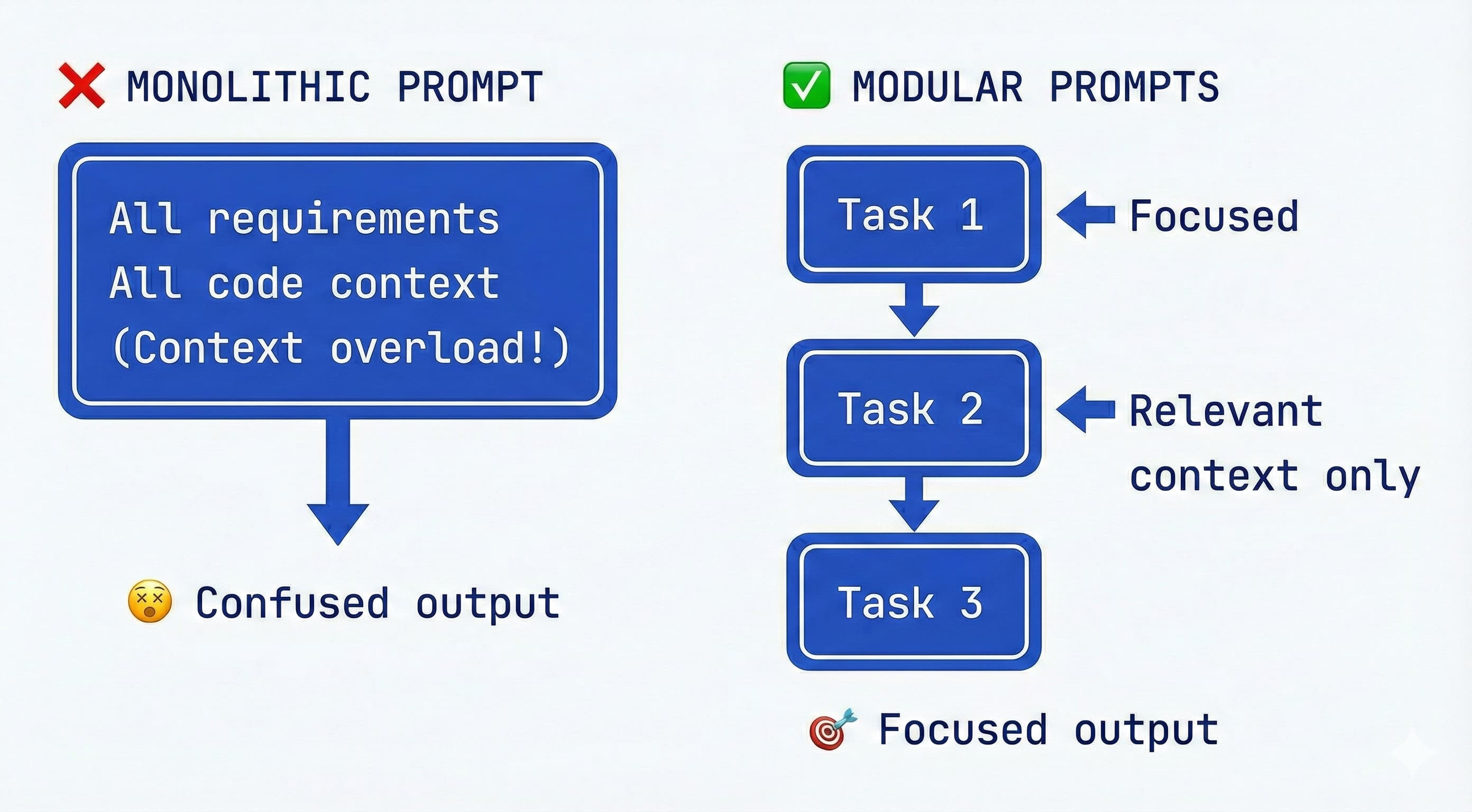
과도한 컨텍스트/지침의 저주: 연구에 따르면 프롬프트에 더 많은 지침이나 데이터를 쌓을수록 각 지침을 준수하는 모델의 성능이 현저히 떨어집니다. 한 연구는 이를 "지침의 저주"라고 명명하며, GPT-4와 Claude조차 많은 요구 사항을 동시에 충족시켜야 할 때 어려움을 겪는다는 것을 보여주었습니다. 실질적으로 10개의 상세한 규칙을 불렛 포인트로 제시하면, AI는 처음 몇 개는 따르겠지만 다른 것들은 간과하기 시작할 수 있습니다. 더 나은 전략은 반복적인 집중입니다. 업계 가이드라인은 복잡한 요구 사항을 순차적이고 단순한 지침으로 분해하는 것을 베스트 프랙티스로 제안합니다. AI가 한 번에 하나의 하위 문제에 집중하게 하고, 그것을 완료한 다음 다음으로 넘어가세요. 이렇게 하면 품질을 높게 유지하고 오류를 관리 가능한 수준으로 유지할 수 있습니다.
사양서를 단계나 구성 요소로 나누세요: 사양서 문서가 매우 길거나 많은 범위를 다룬다면, 이를 여러 부분으로 나누는 것을 고려하세요(물리적으로 별개의 파일이든 명확히 구분된 섹션이든 상관없습니다). 예를 들어 "백엔드 API 사양" 섹션과 "프런트엔드 UI 사양" 섹션을 별도로 둘 수 있습니다. 백엔드 작업을 할 때 프런트엔드 사양을 항상 AI에게 줄 필요는 없으며 그 반대도 마찬가지입니다. 멀티 에이전트 설정을 사용하는 많은 개발자는 각 부분에 대해 별도의 에이전트나 하위 프로세스를 만들기도 합니다. 예를 들어 하나는 데이터베이스/스키마를 담당하고, 다른 하나는 API 로직을, 또 다른 하나는 프런트엔드를 담당하며 각자 사양서의 관련 슬라이스만 가집니다. 단일 에이전트를 사용하더라도 해당 작업에 필요한 사양서 섹션만 프롬프트에 복사하여 이 방식을 모방할 수 있습니다. DigitalOcean AI 가이드에서 경고하듯이, 인증 작업과 데이터베이스 스키마 변경을 한꺼번에 섞지 마세요. 각 프롬프트의 범위를 현재 목표에 맞게 좁게 유지하세요.
대규모 사양서를 위한 확장된 목차/요약: 한 가지 영리한 기술은 에이전트가 사양서에 대한 요약이 포함된 확장된 목차를 작성하게 하는 것입니다. 이는 본질적으로 각 섹션을 몇 개의 핵심 포인트나 키워드로 압축하고 세부 사항을 찾을 수 있는 위치를 참조하는 "사양서 요약"입니다. 예를 들어 전체 사양서에 500단어 분량의 "보안 요구 사항" 섹션이 있다면, 에이전트가 이를 다음과 같이 요약하게 할 수 있습니다: "보안: HTTPS 사용, API 키 보호, 입력 유효성 검사 구현(전체 사양서 §4.2 참조)". 계획 단계에서 계층적 요약을 만들면, 세부 사항은 필요할 때까지 오프로드된 상태로 유지하면서 프롬프트에 계속 머물 수 있는 조감도를 얻을 수 있습니다. 이 확장된 목차는 인덱스 역할을 합니다. 에이전트는 이를 참고하여 "아, 내가 살펴봐야 할 보안 섹션이 있구나"라고 판단할 수 있고, 여러분은 요청 시 해당 섹션을 제공할 수 있습니다. 이는 인간 개발자가 개요를 훑어본 다음 특정 작업을 할 때 사양서의 관련 페이지를 펼치는 것과 비슷합니다.
이를 구현하려면 사양서를 작성한 후 에이전트에게 다음과 같이 프롬프트하세요: "위의 사양서를 각 섹션의 핵심 포인트와 참조 태그가 포함된 매우 간결한 개요로 요약해 줘." 결과는 한두 문장의 요약이 포함된 섹션 목록이 될 것입니다. 이 요약은 시스템이나 어시스턴트 메시지에 보관되어 너무 많은 토큰을 소비하지 않으면서 에이전트의 집중을 유도할 수 있습니다. 이러한 계층적 요약 접근 방식은 LLM이 고수준 구조에 집중함으로써 장기적인 컨텍스트를 유지하는 데 도움이 되는 것으로 알려져 있습니다. 에이전트는 사양서의 "멘탈 맵"을 가지고 다니게 됩니다.
사양서의 각 부분에 하위 에이전트나 "기술(Skills)" 활용: 또 다른 고급 접근 방식은 여러 전문 에이전트(Anthropic이 하위 에이전트라고 부르거나 여러분이 "기술"이라고 부를 수 있는 것)를 사용하는 것입니다. 각 하위 에이전트는 특정 전문 분야에 맞게 설정되고 해당 분야와 관련된 사양서 부분만 제공받습니다. 예를 들어 데이터 모델 섹션만 아는 데이터베이스 설계 하위 에이전트와 API 엔드포인트 사양만 아는 API 코더 하위 에이전트를 둘 수 있습니다. 메인 에이전트(또는 오케스트레이터)는 작업을 적절한 하위 에이전트에게 자동으로 라우팅할 수 있습니다. 이점은 각 에이전트가 처리해야 할 컨텍스트 창이 더 작고 역할이 더 집중되어 정확도를 높이고 독립적인 작업의 병렬 처리를 가능하게 한다는 것입니다. Anthropic의 Claude Code는 자체 시스템 프롬프트와 도구를 가진 하위 에이전트를 정의할 수 있게 하여 이를 지원합니다. "각 하위 에이전트는 특정 목적과 전문 분야를 가지며, 메인 대화와 분리된 자체 컨텍스트 창을 사용하고, 동작을 안내하는 맞춤형 시스템 프롬프트를 가집니다"라고 그들의 문서는 설명합니다. 하위 에이전트의 도메인과 일치하는 작업이 발생하면 Claude는 해당 작업을 위임하고, 하위 에이전트는 독립적으로 결과를 반환합니다.
처리량 향상을 위한 병렬 에이전트: 여러 에이전트를 동시에 실행하는 것은 개발자 생산성을 위한 "차세대 핵심 요소"로 떠오르고 있습니다. 한 에이전트가 끝나기를 기다렸다가 다른 작업을 시작하는 대신, 겹치지 않는 작업을 위해 병렬 에이전트를 가동할 수 있습니다. Willison은 이를 "병렬 코딩 에이전트 수용"이라고 설명하며 "정신적으로는 피곤하지만 놀라울 정도로 효과적"이라고 언급했습니다. 핵심은 에이전트들이 서로의 영역을 침범하지 않도록 작업 범위를 정하는 것입니다. 한 에이전트가 기능을 코딩하는 동안 다른 에이전트는 테스트를 작성하거나, 별개의 구성 요소들이 동시에 구축되도록 하는 식입니다. LangGraph나 OpenAI Swarm과 같은 오케스트레이션 프레임워크는 이러한 에이전트들을 조정하는 데 도움을 줄 수 있으며, 벡터 데이터베이스(Chroma 등)를 통한 공유 메모리는 중복 프롬프트 없이 공통 컨텍스트에 접근할 수 있게 해줍니다.
단일 에이전트 vs 멀티 에이전트: 언제 무엇을 사용할 것인가
측면 | 단일 에이전트 | 병렬/멀티 에이전트 |
|---|---|---|
장점 | 설정이 간단함; 오버헤드 낮음; 디버깅 및 추적이 쉬움 | 처리량 높음; 복잡한 상호 의존성 처리 가능; 도메인별 전문가 활용 |
과제 | 대규모 프로젝트에서 컨텍스트 과부하; 느린 반복; 단일 실패 지점 | 조정 오버헤드; 잠재적 충돌; 공유 메모리(예: 벡터 DB) 필요 |
적합한 용도 | 격리된 모듈; 소중규모 프로젝트; 초기 프로토타이핑 | 대규모 코드베이스; 코딩+테스트+리뷰 분업; 독립적 기능들 |
팁 | 사양서 요약 사용; 작업당 컨텍스트 갱신; 자주 새로운 세션 시작 | 초기에는 2-3개 에이전트로 제한; 도구 공유를 위해 MCP 사용; 명확한 경계 정의 |
실제로 하위 에이전트나 기술별 프롬프트를 사용하는 모습은 다음과 같을 수 있습니다. 여러 사양서 파일(또는 프롬프트 템플릿)을 유지하고(예: SPEC_backend.md, SPEC_frontend.md), AI에게 "백엔드 작업은 SPEC_backend를 참조하고, 프런트엔드 작업은 SPEC_frontend를 참조해"라고 말하는 것입니다. 또는 Cursor/Claude와 같은 도구에서 각 작업을 위해 실제로 하위 에이전트를 가동합니다. 이는 확실히 단일 에이전트 루프보다 설정이 복잡하지만, 인간 개발자가 하는 방식을 모방한 것입니다. 우리는 대규모 사양서를 관련 덩어리로 정신적으로 구획화합니다(50페이지 분량의 사양서 전체를 머릿속에 담아두지 않고, 당장 필요한 부분만 떠올리며 전체 아키텍처에 대한 일반적인 감각만 유지합니다). 언급했듯이 과제는 상호 의존성을 관리하는 것입니다. 하위 에이전트들은 여전히 조정이 필요합니다(프런트엔드는 백엔드 사양의 API 계약을 알아야 하는 등). 중앙 개요(또는 "아키텍트" 에이전트)는 하위 사양들을 참조하고 일관성을 보장함으로써 도움을 줄 수 있습니다.
각 프롬프트를 하나의 작업/섹션에 집중시키세요: 화려한 멀티 에이전트 설정이 없더라도 수동으로 모듈성을 강제할 수 있습니다. 예를 들어 사양서가 작성된 후 다음 단계는 "1단계: 데이터베이스 스키마 구현"이 될 수 있습니다. 에이전트에게 사양서의 데이터베이스 섹션과 기술 스택 같은 전역 제약 조건만 제공합니다. 에이전트는 그 작업을 수행합니다. 그런 다음 2단계 "이제 인증 기능을 구현해 줘"를 위해 사양서의 인증 섹션과 필요한 경우 스키마의 관련 부분을 제공합니다. 각 주요 작업마다 컨텍스트를 갱신함으로써 모델이 주의를 분산시킬 수 있는 오래되거나 무관한 정보를 가지고 있지 않도록 보장합니다. 한 가이드에서 제안하듯이, "새롭게 시작하세요: 주요 기능 간 전환 시 컨텍스트를 지우기 위해 새 세션을 시작하세요". 매번 사양서의 제약 조건 섹션에서 중요한 전역 규칙을 상기시킬 수는 있지만, 필요하지 않은 사양서 전체를 밀어 넣지는 마세요.
인라인 지시어와 코드 TODO 사용: 또 다른 모듈화 트릭은 코드나 사양서를 대화의 활성 부분으로 사용하는 것입니다. 예를 들어 수행해야 할 작업을 설명하는 // TODO 주석으로 코드를 스캐폴딩하고, 에이전트가 이를 하나씩 채우도록 하세요. 각 TODO는 본질적으로 작은 작업을 위한 미니 사양서 역할을 합니다. 이는 AI가 레이저처럼 집중하게 만들며("이 사양서 스니펫에 따라 이 특정 함수를 구현해 줘"), 여러분은 긴밀한 루프에서 반복할 수 있습니다. 이는 전체 체크리스트를 한꺼번에 주는 대신 AI에게 완료해야 할 체크리스트 항목 하나를 주는 것과 비슷합니다.
결론: 작고 집중된 컨텍스트가 하나의 거대한 프롬프트보다 낫습니다. 이는 품질을 향상시키고 AI가 한꺼번에 너무 많은 정보에 "압도"되는 것을 방지합니다. 베스트 프랙티스 모음에서 요약하듯이, 모델에게 "하나의 작업 집중"과 "관련 정보만" 제공하고 모든 것을 어디에나 쏟아붓는 것을 피하세요. 작업을 모듈로 구조화하고 사양서 요약이나 하위 사양 에이전트와 같은 전략을 사용하면, 컨텍스트 크기 제한과 AI의 단기 기억 한계를 극복할 수 있습니다. 잘 먹인 AI는 잘 만든 함수와 같다는 점을 기억하세요. 당면한 작업에 필요한 입력만 제공하세요.
4. 자체 점검, 제약 조건 및 인간의 전문 지식을 내장하세요
사양서를 에이전트를 위한 단순한 할 일 목록이 아니라 품질 관리를 위한 가이드로 만들고, 여러분 자신의 전문 지식을 주입하는 것을 두려워하지 마세요.
AI 에이전트를 위한 좋은 사양서는 AI가 잘못될 수 있는 부분을 예측하고 가드레일을 설정합니다. 또한 AI가 진공 상태에서 작동하지 않도록 여러분이 알고 있는 것(도메인 지식, 예외 케이스, "함정")을 활용합니다. 사양서를 AI를 위한 코치이자 심판으로 생각하세요. 올바른 접근 방식을 장려하고 반칙을 지적해야 합니다.
3단계 경계 사용: 2,500개 이상의 에이전트 파일에 대한 GitHub 분석에 따르면, 가장 효과적인 사양서는 단순한 금지 목록 대신 3단계 경계 시스템을 사용합니다. 이는 에이전트에게 언제 진행하고, 언제 멈추고, 언제 중단해야 하는지에 대한 더 명확한 지침을 제공합니다.

✅ 항상 할 것(Always do): 에이전트가 묻지 않고 수행해야 하는 작업. "커밋 전 항상 테스트 실행", "스타일 가이드의 명명 규칙 항상 준수", "모니터링 서비스에 항상 오류 기록".
⚠️ 먼저 물어볼 것(Ask first): 인간의 승인이 필요한 작업. "데이터베이스 스키마를 수정하기 전에 물어볼 것", "새로운 종속성을 추가하기 전에 물어볼 것", "CI/CD 설정을 변경하기 전에 물어볼 것". 이 단계는 괜찮을 수도 있지만 인간의 확인이 필요한 영향력이 큰 변경 사항을 잡아냅니다.
🚫 절대 하지 말 것(Never do): 엄격한 중단 사항. "비밀번호/키나 API 키를 절대 커밋하지 말 것", "node_modules/나 vendor/를 절대 수정하지 말 것", "명시적 승인 없이 실패한 테스트를 절대 제거하지 말 것". "비밀번호/키를 절대 커밋하지 말 것"은 GitHub 연구에서 가장 흔하고 유용했던 제약 조건이었습니다.
이 3단계 접근 방식은 단순한 규칙 목록보다 더 세밀합니다. 어떤 행동은 항상 안전하고, 어떤 행동은 감독이 필요하며, 어떤 행동은 단호히 금지된다는 점을 인정합니다. 에이전트는 "항상 할 것" 항목에 대해서는 자신 있게 진행하고, "먼저 물어볼 것" 항목은 검토를 위해 플래그를 세우며, "절대 하지 말 것" 항목에서는 엄격히 멈출 수 있습니다.
자체 검증 장려: 한 가지 강력한 패턴은 에이전트가 사양서에 따라 자신의 작업을 자동으로 검증하게 하는 것입니다. 도구가 허용한다면 코드를 생성한 후 에이전트가 실행할 수 있는 유닛 테스트나 린팅과 같은 체크 기능을 통합할 수 있습니다. 하지만 사양서/프롬프트 수준에서도 AI에게 이중 점검을 지시할 수 있습니다. 예: "구현 후 결과를 사양서와 비교하고 모든 요구 사항이 충족되었는지 확인해 줘. 해결되지 않은 사양서 항목이 있다면 목록을 작성해 줘." 이는 LLM이 사양서와 관련하여 자신의 출력물을 되돌아보게 하여 누락된 부분을 잡게 합니다. 이는 프로세스에 내장된 일종의 자체 감사 형태입니다.
예를 들어 프롬프트 끝에 다음과 같이 추가할 수 있습니다: "(함수를 작성한 후 위의 요구 사항 목록을 검토하고 각 항목이 충족되었는지 확인하고, 누락된 항목이 있으면 표시해 줘)". 그러면 모델은 (이상적으로는) 코드를 출력한 후 각 요구 사항을 충족했는지 나타내는 짧은 체크리스트를 출력할 것입니다. 이는 여러분이 테스트를 실행하기도 전에 무언가를 잊어버릴 가능성을 줄여줍니다. 완벽하지는 않지만 도움이 됩니다.
주관적 체크를 위한 LLM-as-a-Judge: 코드 스타일, 가독성, 아키텍처 패턴 준수와 같이 자동으로 테스트하기 어려운 기준의 경우 "판사로서의 LLM(LLM-as-a-Judge)" 사용을 고려하세요. 이는 두 번째 에이전트(또는 별도의 프롬프트)가 첫 번째 에이전트의 출력물을 사양서의 품질 가이드라인과 대조하여 검토하게 하는 것을 의미합니다. Anthropic 등은 이것이 주관적 평가에 효과적이라는 것을 발견했습니다. 다음과 같이 프롬프트할 수 있습니다: "이 코드가 우리 스타일 가이드를 준수하는지 검토해 줘. 위반 사항이 있으면 플래그를 세워 줘." 판사 에이전트는 통합되거나 수정을 유도하는 피드백을 반환합니다. 이는 구문 체크를 넘어 의미론적 평가 레이어를 추가합니다.
적합성 테스트(Conformance testing): Willison은 적합성 스위트(Conformance suites), 즉 모든 구현체가 통과해야 하는 언어 독립적인 테스트(종종 YAML 기반) 구축을 옹호합니다. 이는 계약 역할을 합니다. API를 구축하는 경우 적합성 스위트는 예상되는 입력/출력을 명시하며, 에이전트의 코드는 모든 케이스를 만족해야 합니다. 이는 사양서에서 직접 파생되고 구현 전반에 걸쳐 재사용될 수 있기 때문에 임시 유닛 테스트보다 더 엄격합니다. 사양서의 성공 섹션에 적합성 기준을 포함하세요(예: "conformance/api-tests.yaml의 모든 케이스를 통과해야 함").
사양서에서 테스트 활용: 가능하다면 사양서와 프롬프트 흐름에 테스트 계획이나 실제 테스트를 포함하세요. 전통적인 개발에서 우리는 요구 사항을 명확히 하기 위해 TDD를 사용하거나 테스트 케이스를 작성합니다. AI에서도 똑같이 할 수 있습니다. 예를 들어 사양서의 성공 기준에 "이 샘플 입력은 이러한 출력을 생성해야 함..." 또는 "다음 유닛 테스트가 통과해야 함"이라고 명시할 수 있습니다. 에이전트는 머릿속으로 해당 케이스를 실행해 보거나, 능력이 있다면 실제로 실행하도록 프롬프트될 수 있습니다. Simon Willison은 견고한 테스트 스위트를 갖추는 것이 에이전트에게 슈퍼파워를 주는 것과 같다고 언급했습니다. 테스트가 실패할 때 에이전트가 신속하게 검증하고 반복할 수 있기 때문입니다. AI 코딩 컨텍스트에서 테스트를 위한 의사코드나 예상 결과를 사양서에 조금 작성해 두는 것은 에이전트의 구현을 안내할 수 있습니다. 또한 하위 에이전트 설정에서 사양서의 기준을 가져와 "코드 에이전트"의 출력물을 지속적으로 검증하는 전용 "테스트 에이전트"를 사용할 수도 있습니다.
도메인 지식 활용: 사양서에는 숙련된 개발자나 컨텍스트를 가진 사람만이 알 수 있는 통찰력이 반영되어야 합니다. 예를 들어 이커머스 에이전트를 구축하고 있고 "제품"과 "카테고리"가 다대다(Many-to-many) 관계라는 것을 알고 있다면 이를 명확히 명시하세요(AI가 추론할 것이라고 가정하지 마세요. 추론하지 못할 수도 있습니다). 특정 라이브러리가 까다로운 것으로 유명하다면 피해야 할 함정을 언급하세요. 본질적으로 여러분의 멘토링을 사양서에 쏟아부으세요. 사양서에는 "라이브러리 X를 사용하는 경우 버전 Y의 메모리 누수 문제를 주의할 것(해결 방법 Z 적용)"과 같은 조언이 포함될 수 있습니다. 이러한 수준의 세부 사항은 AI가 흔한 함정을 피하도록 조종하기 때문에 평범한 AI 출력물을 진정으로 견고한 솔루션으로 바꿔줍니다.
또한 선호도나 스타일 가이드라인(예: "React에서 클래스 컴포넌트보다 함수형 컴포넌트 사용")이 있다면 사양서에 인코딩하세요. 그러면 AI가 여러분의 스타일을 모방할 것입니다. 많은 엔지니어는 사양서에 작은 예시를 포함하기도 합니다. 예: "모든 API 응답은 JSON이어야 함. 예: 오류의 경우 {“error”: “message”}." 빠른 예시를 제공함으로써 AI를 여러분이 원하는 정확한 형식에 고정시킬 수 있습니다.
단순한 작업에는 미니멀리즘을: 철저한 사양서를 옹호하지만, 전문 지식의 일부는 언제 단순하게 유지해야 할지 아는 것입니다. 상대적으로 단순하고 격리된 작업의 경우, 지나친 사양서는 도움보다 혼란을 줄 수 있습니다. 에이전트에게 간단한 작업(예: "페이지 중앙에 div 배치")을 요청하는 경우, "솔루션을 간결하게 유지하고 불필요한 마크업이나 스타일을 추가하지 마세요"라고만 말할 수도 있습니다. 여기에는 전체 PRD가 필요하지 않습니다. 반대로 복잡한 작업(예: "토큰 갱신 및 오류 처리가 포함된 OAuth 흐름 구현")의 경우에는 상세 사양서를 꺼내야 할 때입니다. 좋은 규칙: 작업 복잡도에 따라 사양서의 세부 수준을 조정하세요. 어려운 문제를 과소 사양화하지 말고(에이전트가 허우적대거나 경로를 이탈할 것입니다), 사소한 문제를 과도 사양화하지 마세요(에이전트가 꼬이거나 불필요한 지침에 컨텍스트를 낭비할 수 있습니다).
필요한 경우 AI의 "페르소나" 유지: 때때로 사양서의 일부는 에이전트가 어떻게 행동하거나 응답해야 하는지를 정의하는 것입니다. 특히 에이전트가 사용자와 상호작용하는 경우 더욱 그렇습니다. 예를 들어 고객 지원 에이전트를 구축하는 경우 사양서에 "친절하고 전문적인 톤을 사용하세요", "답을 모르는 경우 추측하기보다 명확한 설명을 요청하거나 나중에 확인해 주겠다고 제안하세요"와 같은 가이드라인을 포함할 수 있습니다. 이러한 종류의 규칙(종종 시스템 프롬프트에 포함됨)은 AI의 출력이 기대치와 일치하도록 도와줍니다. 이는 본질적으로 AI 행동을 위한 사양 항목입니다. 이를 일관되게 유지하고 긴 세션에서 모델이 스타일을 잃어버릴 수 있으므로 필요한 경우 상기시켜 주세요.
여러분은 루프 안의 결정권자로 남습니다: 사양서는 에이전트에게 힘을 실어주지만, 최종적인 품질 필터는 여러분입니다. 에이전트가 기술적으로는 사양을 충족하지만 느낌이 좋지 않은 결과물을 내놓는다면 여러분의 판단을 믿으세요. 사양서를 다듬거나 결과물을 직접 조정하세요. AI 에이전트의 장점은 기분 나빠하지 않는다는 것입니다. 에이전트가 빗나간 디자인을 내놓으면 "사실 그건 내 의도가 아니었어. 사양서를 명확히 하고 다시 해보자"라고 말할 수 있습니다. 사양서는 변경할 수 없는 일회성 계약이 아니라 AI와 협력하는 살아있는 결과물입니다.
Simon Willison은 AI 에이전트와 작업하는 것을 "매우 기묘한 형태의 관리"라고 유머러스하게 비유했으며, 심지어 "코딩 에이전트로부터 좋은 결과를 얻는 것은 인간 인턴을 관리하는 것과 불편할 정도로 비슷하게 느껴진다"고 했습니다. 명확한 지침(사양서)을 제공하고, 필요한 컨텍스트(사양서 및 관련 데이터)를 갖추었는지 확인하고, 실행 가능한 피드백을 주어야 합니다. 사양서가 무대를 설정하지만, 실행 중 모니터링과 피드백이 핵심입니다. AI가 "기회만 주어지면 반드시 속임수를 쓸 기묘한 디지털 인턴"이라면, 여러분이 작성하는 사양서와 제약 조건은 그 속임수를 방지하고 작업을 유지하게 하는 방법입니다.
여기서 얻는 보상은 다음과 같습니다. 좋은 사양서는 AI에게 무엇을 구축할지 알려줄 뿐만 아니라, AI가 스스로 수정하고 안전한 경계 내에 머물도록 돕습니다. 검증 단계, 제약 조건, 그리고 여러분의 고생해서 얻은 지식을 녹여냄으로써 에이전트의 결과물이 첫 시도에 정확할(또는 적어도 훨씬 더 정확에 가까울) 확률을 획기적으로 높일 수 있습니다. 이는 반복 횟수와 "도대체 왜 저런 짓을 했지?" 하는 순간들을 줄여줍니다.
5. 사양서를 테스트하고, 반복하고, 진화시키세요 (그리고 적절한 도구를 사용하세요)
사양서 작성과 에이전트 구축을 반복적인 루프로 생각하세요. 일찍 테스트하고, 피드백을 수집하고, 사양서를 다듬고, 도구를 활용하여 체크를 자동화하세요.
초기 사양서는 끝이 아니라 시작입니다. 최상의 결과는 에이전트의 작업을 사양서에 비추어 지속적으로 검증하고 그에 따라 조정할 때 나옵니다. 또한 현대의 AI 개발자들은 이 프로세스를 지원하기 위해 다양한 도구(CI 파이프라인부터 컨텍스트 관리 유틸리티까지)를 사용합니다.
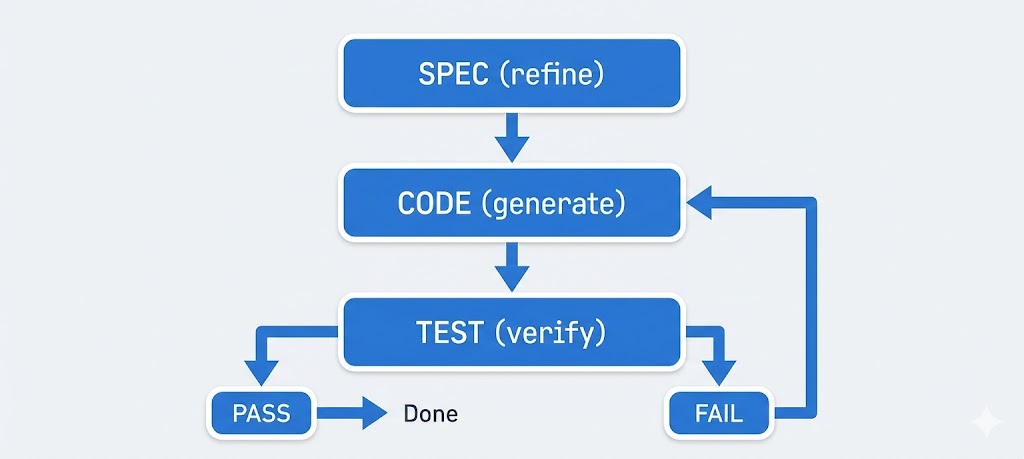
지속적인 테스트: 에이전트가 사양을 충족했는지 확인하기 위해 끝까지 기다리지 마세요. 각 주요 마일스톤이나 각 함수가 끝난 후 테스트를 실행하거나 최소한 빠른 수동 체크를 하세요. 실패한 부분이 있다면 진행하기 전에 사양서나 프롬프트를 업데이트하세요. 예를 들어 사양서에 "비밀번호는 bcrypt로 해싱해야 함"이라고 되어 있는데 에이전트의 코드가 평문으로 저장하고 있다면, 멈추고 수정하세요(그리고 사양서나 프롬프트의 규칙을 상기시키세요). 자동화된 테스트는 여기서 빛을 발합니다. 테스트를 제공했거나(또는 진행하면서 작성했다면) 에이전트가 이를 실행하게 하세요. 많은 코딩 에이전트 설정에서 작업을 마친 후 에이전트가
npm test 등을 실행하게 할 수 있습니다. 결과(실패)는 다음 프롬프트로 피드백되어 에이전트에게 "너의 출력물이 X, Y, Z에서 사양을 충족하지 못했으니 수정해 줘"라고 효과적으로 말해줍니다. 이러한 에이전트 루프(코드 -> 테스트 -> 수정 -> 반복)는 매우 강력하며 Claude Code나 Copilot Labs와 같은 도구들이 더 큰 작업을 처리하기 위해 진화하는 방식입니다. 항상 "완료"가 무엇을 의미하는지(테스트나 기준을 통해) 정의하고 이를 확인하세요.사양서 자체를 반복해서 다듬으세요: 사양서가 불완전하거나 불명확했다는 것을 발견하면(AI가 무언가를 오해했거나 요구 사항을 놓쳤다는 것을 깨달았을 때), 사양서 문서를 업데이트하세요. 그런 다음 에이전트를 새로운 사양서와 명시적으로 동기화하세요: "사양서를 다음과 같이 업데이트했어... 업데이트된 사양서에 따라 계획을 조정하거나 코드를 리팩토링해 줘." 이렇게 하면 사양서가 단일 진실 공급원으로 남게 됩니다. 이는 일반적인 개발에서 변경되는 요구 사항을 처리하는 방식과 비슷하지만, 이 경우에는 여러분이 AI 에이전트의 제품 관리자이기도 합니다. 가능하다면 버전 기록을 유지하여(커밋 메시지나 노트를 통해서라도) 무엇이 왜 바뀌었는지 알 수 있게 하세요.
컨텍스트 관리 및 메모리 도구 활용: AI 에이전트의 컨텍스트와 지식을 관리하는 데 도움이 되는 도구 생태계가 성장하고 있습니다. 예를 들어 검색 증강 생성(RAG)은 에이전트가 지식 베이스(벡터 데이터베이스 등)에서 관련 데이터 덩어리를 즉석에서 끌어올 수 있는 패턴입니다. 사양서가 방대하다면 항상 전체를 제공하는 대신 사양서 섹션을 임베딩하고 에이전트가 필요할 때 가장 관련 있는 부분을 검색하게 할 수 있습니다. 현재 작업에 따라 모델에 적절한 컨텍스트를 자동으로 제공하는 MCP(Model Context Protocol)를 구현하는 프레임워크도 있습니다. 한 예로 Context7(context7.com)이 있는데, 작업 중인 내용에 따라 문서에서 관련 컨텍스트 스니펫을 자동으로 가져올 수 있습니다. 실제로 이는 에이전트가 여러분이 "결제 처리" 작업을 하고 있음을 감지하고 사양서나 문서의 "결제" 섹션을 프롬프트로 끌어오는 것을 의미할 수 있습니다. 이러한 도구를 활용하거나 간단한 버전(사양서 문서 내의 단순 검색 등)을 설정하는 것을 고려해 보세요.
신중하게 병렬화하세요: 일부 개발자는 서로 다른 작업에 대해 여러 에이전트 인스턴스를 병렬로 실행합니다(앞서 하위 에이전트에서 언급한 대로). 이는 개발 속도를 높일 수 있습니다. 예를 들어 한 에이전트는 코드를 생성하고 다른 에이전트는 동시에 테스트를 작성하거나, 두 기능이 동시에 구축되도록 하는 식입니다. 이 경로를 택한다면 충돌을 피하기 위해 작업이 진정으로 독립적이거나 명확히 분리되어 있는지 확인하세요(사양서에 의존성을 기록해야 합니다). 예를 들어 두 에이전트가 동시에 같은 파일에 쓰게 하지 마세요. 한 가지 워크플로우는 에이전트가 코드를 생성하고 다른 에이전트가 병렬로 검토하게 하거나, 나중에 통합될 별도의 구성 요소를 구축하게 하는 것입니다. 이는 고급 사용법이며 관리하기에 정신적으로 힘들 수 있습니다(Willison이 인정했듯이 여러 에이전트를 실행하는 것은 놀라울 정도로 효과적이지만 정신적으로 피곤합니다!). 관리 가능한 수준을 유지하기 위해 처음에는 최대 2-3개의 에이전트로 시작하세요.
버전 관리 및 사양서 잠금: Git이나 선택한 버전 관리 도구를 사용하여 에이전트가 수행하는 작업을 추적하세요. 좋은 버전 관리 습관은 AI 지원을 받을 때 더욱 중요합니다. 사양서 파일 자체를 저장소에 커밋하세요. 이는 기록을 보존할 뿐만 아니라 에이전트가
git diff나 blame을 사용하여 변경 사항을 이해하는 데도 도움이 됩니다(LLM은 diff를 읽는 데 꽤 능숙합니다). 일부 고급 에이전트 설정은 에이전트가 VCS 기록을 쿼리하여 무언가가 언제 도입되었는지 확인할 수 있게 해줍니다. 놀랍게도 모델은 "Git 사용에 있어 맹렬할 정도로 유능할" 수 있습니다. 사양서를 저장소에 보관함으로써 여러분과 AI 모두 진화 과정을 추적할 수 있습니다. 사양서 중심 개발을 git 워크플로우에 통합하는 도구(앞서 언급한 GitHub Spec Kit 등)도 있습니다. 예를 들어 업데이트된 사양서에 따라 머지를 제한하거나 사양 항목에서 체크리스트를 생성하는 식입니다. 성공을 위해 반드시 그런 도구가 필요한 것은 아니지만, 핵심은 사양서를 코드처럼 취급하고 부지런히 유지 관리하라는 것입니다.비용 및 속도 고려 사항: 대규모 모델과 긴 컨텍스트를 사용하는 것은 느리고 비용이 많이 들 수 있습니다. 실용적인 팁은 모델 선택과 배칭(Batching)을 스마트하게 하는 것입니다. 초기 초안이나 반복 작업에는 더 저렴하고 빠른 모델을 사용하고, 최종 출력이나 복잡한 추론에는 가장 유능한(그리고 비싼) 모델을 아껴두세요. 일부 개발자는 계획과 중요한 단계에는 GPT-4나 Claude를 사용하지만, 단순한 확장이나 리팩토링은 로컬 모델이나 더 작은 API 모델로 오프로드합니다. 여러 에이전트를 사용하는 경우 모든 에이전트가 최고 등급일 필요는 없습니다. 테스트 실행 에이전트나 린터 에이전트는 더 작은 모델일 수 있습니다. 또한 컨텍스트 크기를 조절하세요. 5,000 토큰으로 충분하다면 20,000 토큰을 넣지 마세요. 논의했듯이 토큰이 많아질수록 수확 체감의 법칙이 적용될 수 있습니다.
모든 것을 모니터링하고 기록하세요: 복잡한 에이전트 워크플로우에서는 에이전트의 행동과 출력을 로깅하는 것이 필수적입니다. 로그를 확인하여 에이전트가 이탈하거나 오류를 겪고 있는지 확인하세요. 많은 프레임워크는 추적 로그를 제공하거나 에이전트의 사고 사슬(Chain-of-thought)을 출력할 수 있게 합니다(특히 단계별로 생각하도록 프롬프트한 경우). 이러한 로그를 검토하면 사양서나 지침이 어디서 오해되었는지 파악할 수 있습니다. 이는 프로그램을 디버깅하는 것과 다르지 않습니다. 다만 "프로그램"이 대화/프롬프트 체인일 뿐입니다. 이상한 일이 발생하면 사양서/지침으로 돌아가 모호함이 있었는지 확인하세요.
학습하고 개선하세요: 마지막으로, 각 프로젝트를 사양서 작성 기술을 다듬는 학습 기회로 삼으세요. 특정 문구가 AI를 지속적으로 혼란스럽게 한다거나, 사양서 섹션을 특정 방식으로 구성했을 때 준수율이 더 높다는 것을 발견할 수도 있습니다. 그러한 교훈을 다음 사양서에 반영하세요. AI 에이전트 분야는 빠르게 진화하고 있으므로 새로운 베스트 프랙티스(및 도구)가 끊임없이 등장합니다. 블로그(Simon Willison, Andrej Karpathy 등)를 통해 최신 정보를 유지하고 실험을 주저하지 마세요.
AI 에이전트를 위한 사양서는 "한 번 쓰고 끝"이 아닙니다. 지시하고, 검증하고, 다듬는 지속적인 사이클의 일부입니다. 이러한 부지런함에 대한 보상은 상당합니다. 문제를 조기에 발견하고 에이전트의 방향을 유지함으로써 나중에 비용이 많이 드는 재작성이나 실패를 피할 수 있습니다. 한 AI 엔지니어가 농담조로 말했듯이, 이러한 관행을 사용하는 것은 "인턴 군단"을 거느리는 것과 같지만, 그들을 잘 관리해야 합니다. 지속적으로 유지 관리되는 좋은 사양서가 바로 여러분의 관리 도구입니다.
흔한 함정 피하기
마무리하기 전에, 의도가 좋은 사양서 중심 워크플로우조차 망칠 수 있는 안티 패턴들을 짚어볼 가치가 있습니다. 2,500개 이상의 에이전트 파일에 대한 GitHub 연구는 극명한 차이를 보여주었습니다: "대부분의 에이전트 파일은 너무 모호하기 때문에 실패합니다." 피해야 할 실수는 다음과 같습니다.
모호한 프롬프트: "멋진 거 하나 만들어 줘" 또는 "더 잘 작동하게 해 줘"는 에이전트가 의지할 근거를 전혀 주지 못합니다. Baptiste Studer가 말했듯이 "모호한 프롬프트는 잘못된 결과를 의미합니다." 입력, 출력, 제약 조건에 대해 구체적으로 작성하세요. "당신은 도움이 되는 코딩 어시스턴트입니다"는 작동하지 않습니다. "당신은 React 컴포넌트에 대한 테스트를 작성하고, 이 예시들을 따르며, 소스 코드를 절대 수정하지 않는 테스트 엔지니어입니다"는 작동합니다.
요약 없는 너무 긴 컨텍스트: 50페이지 분량의 문서를 프롬프트에 쏟아붓고 모델이 알아서 파악하기를 바라는 것은 거의 작동하지 않습니다. (원칙 3에서 논의한 대로) 계층적 요약이나 RAG를 사용하여 관련 있는 내용만 노출하세요. 컨텍스트 길이는 컨텍스트 품질을 대체할 수 없습니다.
인간 검토 건너뛰기: Willison은 개인적인 규칙이 있습니다: "다른 사람에게 설명할 수 없는 코드는 커밋하지 않는다." 에이전트가 테스트를 통과하는 결과물을 냈다고 해서 그것이 반드시 정확하거나, 안전하거나, 유지 관리 가능하다는 뜻은 아닙니다. 항상 중요한 코드 경로를 검토하세요. "사상누각" 비유가 여기서도 적용됩니다. AI가 생성한 코드는 견고해 보일 수 있지만 테스트하지 않은 예외 케이스에서 무너질 수 있습니다.
바이브 코딩(Vibe coding)과 프로덕션 엔지니어링 혼동: AI를 이용한 신속한 프로토타이핑("바이브 코딩")은 탐색이나 일회성 프로젝트에는 좋습니다. 하지만 엄격한 사양서, 테스트, 검토 없이 그 코드를 프로덕션에 배포하는 것은 문제를 자초하는 일입니다. 저는 "바이브 코딩"과 "AI 지원 엔지니어링"을 구분합니다. 후자는 이 가이드에서 설명하는 규율이 필요합니다. 여러분이 어떤 모드에 있는지 인지하세요.
"치명적인 삼중주" 무시: Willison은 AI 에이전트를 위험하게 만드는 세 가지 속성을 경고합니다: 속도(여러분이 검토할 수 있는 것보다 빠르게 작업함), 비결정성(같은 입력에도 다른 출력), 비용(검증 시 요령을 피우도록 유도함). 여러분의 사양서와 검토 프로세스는 이 세 가지를 모두 고려해야 합니다. 속도가 여러분의 검증 능력을 앞지르게 하지 마세요.
6가지 핵심 영역 누락: 사양서가 명령어, 테스트, 프로젝트 구조, 코드 스타일, git 워크플로우, 경계를 다루지 않는다면 에이전트에게 필요한 무언가를 놓치고 있을 가능성이 큽니다. 에이전트에게 넘기기 전에 섹션 2의 6가지 영역 체크리스트를 사용하여 상태 점검을 하세요.
결론
AI 코딩 에이전트를 위한 효과적인 사양서를 작성하려면 견고한 소프트웨어 엔지니어링 원칙과 LLM의 특성에 대한 적응이 결합되어야 합니다. 목적의 명확성에서 시작하여 AI가 계획을 확장하도록 하세요. 사양서를 6가지 핵심 영역을 다루는 진지한 설계 문서처럼 구조화하고, 이를 툴체인에 통합하여 단순한 산문이 아닌 실행 가능한 결과물로 만드세요. 퍼즐 조각을 한 번에 하나씩 제공하여 에이전트의 집중력을 유지하세요(그리고 대규모 사양서를 처리하기 위해 요약 목차, 하위 에이전트 또는 병렬 오케스트레이션과 같은 영리한 전술을 고려하세요). 3단계 경계(항상 할 것/먼저 물어볼 것/절대 하지 말 것), 자체 점검, 적합성 테스트를 포함하여 함정을 예측하세요. 본질적으로 AI에게 실패하지 않는 법을 가르치는 것입니다. 그리고 전체 프로세스를 반복적인 것으로 취급하세요. 테스트와 피드백을 사용하여 사양서와 코드를 지속적으로 다듬으세요.
이 가이드라인을 따르면 여러분의 AI 에이전트가 대규모 컨텍스트 아래에서 "무너지거나" 엉뚱한 방향으로 헤매는 일이 훨씬 줄어들 것입니다.
즐거운 사양서 작성이 되길 바랍니다!
이 포스트는 Gemini를 사용하여 포맷팅되었으며, 이미지는 Nano Banana Pro를 사용하여 생성되었습니다.
0
2
댓글
?
아직 댓글이 없습니다.
첫 번째 댓글을 작성해보세요!
![[번역] GraphQL 에러 처리 가이드](https://bucket.rosetta.page/images/cmhvyjhbb00009kn3jj49qrbw/번역-graphql-에러-처리-가이드-o79JX-50aa0650-7701-4559-9f29-6f0a9341d9fd.webp)
![[번역] 인생 디버깅](https://bucket.rosetta.page/images/cmhvyjhbb00009kn3jj49qrbw/번역-하루-만에-인생-전체를-바로잡는-법-5KqoB-9882e2dd-40af-402c-a9bc-2187dc6467ed.webp)
![[번역] The Next Two Years of Software Engineering](https://bucket.rosetta.page/images/cmhvyjhbb00009kn3jj49qrbw/번역-소프트웨어-엔지니어링의-변곡점-2026년까지의-다섯-가지-핵심-질문-272du-6f54c58c-15fb-4a96-9935-0ff26cb5c620.webp)

![[번역] javascript의 try-catch가 성능에 영향을 주나요?](https://bucket.rosetta.page/images/system-topics/front-end-d1ced617-ebcc-4468-b8cc-64bf65af1eba.webp)
