[번역] 시그널(Signals) vs 쿼리 기반 컴파일러(Query-Based Compilers)
I
Inkyu Oh
SW Engineering•2026.01.22
Marvin Hagemeister - 2026년 1월 4일
📖 요약: LSP의 부상과 함께 쿼리 기반 컴파일러가 새로운 아키텍처로 등장했습니다. 이 아키텍처는 제가 처음에 예상했던 것보다 시그널(Signals)과 훨씬 더 비슷하면서도 동시에 다릅니다.
지난 겨울 휴가 동안 호기심을 이기지 못하고, LSP와 긴밀한 에디터 통합이 이루어지는 요즘 시대에 현대적인 컴파일러들이 어떻게 상호작용성(interactivity)을 달성하는지에 대해 많은 시간을 할애해 읽어보았습니다. 그리고 현대적인 컴파일러들이 UI 렌더링에서의 시그널과 동일한 개념을 바탕으로 구축되어 있으며, 몇 가지 흥미롭고 차별화된 설계 선택을 하고 있다는 사실을 알게 되었습니다.
과거: 파이프라인 아키텍처(Pipeline Architecture)
컴파일러에 대한 고전적인 가르침은 코드가 최종 바이너리가 될 때까지 거치는 선형적인 단계의 시퀀스로 컴파일러를 설명합니다. 언어가 상당히 단순하다고 가정하면(JavaScript는 터무니없이 복잡하며 단순함과는 거리가 멉니다), 이런 방식으로 컴파일러를 작성하는 것은 꽤 직관적입니다.
소스 텍스트 -> AST -> IR -> 어셈블리 -> 링커 -> 바이너리먼저, 소스 코드는 입력 텍스트를 구조화된 객체/구조체로 변환하는 추상 구문 트리(Abstract Syntax Tree, 이하 AST)로 변환됩니다. 이곳은 구문 오류, 문법 오류 및 이와 유사한 것들이 포착되는 지점입니다.
예를 들어, 다음과 같은 JavaScript 소스 코드는...
const a = 42;...이런 AST와 유사한 형태로 변환됩니다.
{ "type": "VariableDeclaration", "kind": "const", "declarations": [ { "type": "VariableDeclarator", "id": { "type": "Identifier", "name": "a" }, "init": { "type": "NumericLiteral", "value": 42 } } ]}그 후 AST는 최종 바이너리가 나올 때까지 몇 단계를 더 거치게 됩니다.
이 단계들의 실제 세부 사항은 이 블로그 포스트에서 중요하지 않으며, 여기서 설명한 내용은 매우 단순화된 것입니다. 하지만 중요한 점은 컴파일러가 코드를 실행하기 전까지 보통 수많은 단계를 거쳐 코드를 실행한다는 것입니다. 이 모든 과정에는 시간이 걸립니다. 매 키 입력마다 실행하기에는 너무 많은 시간이 소요되죠.
개발자가 글자 하나를 입력하여 파일 하나를 변경할 때, 배후에서는 엄청난 양의 작업이 일어납니다. 이상적으로는 가능한 한 적은 작업만 수행하고 싶을 것입니다. 물론 모든 단계에 캐시를 추가하고 이를 무효화(invalidate)할 적절한 휴리스틱을 고안할 수도 있겠지만, 이는 금방 유지보수하기 어려워집니다. 좋지 않은 상황이죠.
컴파일러에서의 핵심적인 변화는 컴파일러를 단순한 변환 파이프라인으로 생각하지 않고, 쿼리(query)를 실행할 수 있는 대상으로 생각하는 것입니다. 사용자가 에디터에서 타이핑할 때, LSP는 에디터에게 "이 파일의 특정 커서 위치에서 제안할 수 있는 것이 무엇인가?"라고 묻습니다. 식별자 위에서 "정의로 이동(Go to Definition)"을 클릭하면, 컴파일러에게 점프 대상(있는 경우)을 반환하도록 쿼리하는 것입니다.
본질적으로, 질문들은 컴파일러를 대상으로 실행하는 일련의 쿼리들이며, 컴파일러는 오직 이러한 질문에 가능한 한 빨리 답변하는 데만 집중하고 나머지는 무시해야 합니다.
이러한 멘탈 모델(mental model)의 전환이 현대적인 컴파일러를 훨씬 더 상호작용적으로 만듭니다. 그렇다면 내부적으로는 어떻게 작동하며, 이것이 시그널과 무슨 상관이 있을까요?
쿼리, 입력 그리고 데이터베이스
쿼리 기반 컴파일러에는 세 가지 핵심 구성 요소가 있습니다: 쿼리(Queries), 입력(Inputs), 그리고 "데이터베이스(Database)". 핵심 아이디어는 말 그대로 모든 것이 쿼리와 입력으로 구성된다는 것입니다. 쿼리가 실행되지 않는 한 아무것도 자동으로 실행되지 않습니다.
최상위에는 "최종 바이너리를 달라"는 하나의 큰 쿼리가 있고, 이 쿼리는 다시 "IR을 달라", "AST를 달라" 등 여러 다른 쿼리를 실행합니다. 끝까지 파고 내려가면 결국 모두 쿼리입니다.
하지만 다음과 같은 추가적인 쿼리들도 있습니다: "파일 X의 커서 위치 Y에 있는 식별자의 타입은 무엇인가". 이러한 쿼리는 현재 파일을 AST로 파싱하도록 트리거하는 또 다른 쿼리를 실행합니다. 이를 통해 커서 위치의 식별자를 가져오는 또 다른 쿼리를 실행할 수 있습니다. 그 후 식별자를 정의로 해석(resolve)하는 또 다른 쿼리를 실행합니다. 만약 정의가 다른 파일에 있다면, 해당 파일을 파싱하도록 요청하는 식이죠.
이 아키텍처의 아름다움은 완전히 무관한 파일을 처리하는 데 시간을 낭비하지 않는다는 점입니다. 특정 쿼리에 응답하는 데 필요한 것만 처리합니다. 소스 파일이 실행 중인 쿼리와 전혀 관련이 없다면 절대 처리되지 않습니다.
캐시, 캐시 그리고 더 많은 캐시
속도를 더욱 높이기 위해, 쿼리는 순수(pure)해야 하므로 쉽게 캐싱될 수 있습니다. 쿼리는 부수 효과(side effect)가 없어야 합니다. 즉, 쿼리를 언제든 다시 실행해도 정확히 동일한 결과를 얻을 수 있다는 뜻입니다. 이러한 특성은 캐싱에 완벽합니다.
쿼리는 자동으로 캐싱될 수 있으며, 캐시가 너무 많은 메모리를 소비하면 그냥 비워버리면 됩니다. 다음에 쿼리가 호출될 때 캐시 항목이 없음을 확인하고 단순히 로직을 다시 실행한 뒤 결과를 다시 캐싱할 것입니다. 결과가 다시 캐싱될 때까지 한 번 정도는 조금 느리게 실행될 수 있겠지만, 결코 잘못된 결과를 반환하지는 않습니다.
하지만 캐시가 정확하려면 한 가지 중요한 세부 사항이 필요합니다. 해시된 캐시 키에 전달된 인자(arg)도 포함되어야 한다는 점입니다. 이는
쿼리 A가 여러 곳에서 서로 다른 인자로 호출될 때, 각 인자마다 고유한 캐시된 반환 값을 가진 쿼리 인스턴스가 생성됨을 의미합니다.쿼리의 형태
쿼리는 일반적으로 두 개의 인자를 가진 함수로 정의됩니다.
- 데이터베이스
- 인자 (때때로 '입력'이라고 불려 혼동을 주기도 함)
TypeScript로 표현하면 다음과 같습니다.
type Query<T, R> = (db: Database, arg: T) => R;db 파라미터는 모든 쿼리가 존재하는 곳이고, arg 파라미터는 쿼리를 호출할 때 사용하는 값입니다. 쿼리 내부에서 다른 쿼리를 호출하려면 db.call_other_query(someArg)를 수행합니다. 이를 더 깔끔하게 만들고 데이터베이스에 대해 덜 신경 쓰게 하기 위해, 대부분의 구현체는 매크로나 데코레이터 형태의 문법적 설탕(syntactic sugar)을 추가합니다.class MyDatabase extends Database { getTypeAtCursor(file: string, offset: number): Type { const id = this.getIdentifierAtCursor(file, offset); const type = this.getTypeFromId(id); return type; }}입력: 진실의 원천
디스크에서 파일이 변경되면, 컴파일러에게 해당 파일을 무효화하여 캐시 항목을 삭제하고 다음번에 쿼리가 요청할 때 파일을 다시 처리하도록 알려야 합니다. 이는
입력(Inputs)을 통해 수행됩니다. 입력은 값을 쓸 수 있는 상태 저장 객체입니다. 보통 이들도 데이터베이스에 존재합니다.watch(directory, ev => { if (ev.type === "change") { const content = readTextFile(ev.path); db.updateFile(name, content); }});쿼리에서 입력을 읽을 때는 보통 메서드를 호출하거나 특수한 프로퍼티에 접근합니다.
class MyDatabase extends Database { files = new Map<string, FileInput>() // 세터(Setter) 헬퍼 updateFile(name: string, content: string) { const input = this.files.get(name) ?? new Input<string>() input.write(content) this.files.set(name, input) } parseFile(file: string): AST | null { const fileInput = this.files.get(file) if (fileInput === null) return null; // 입력 읽기 const code = fileInput.read() return parse(code) }}변경할 것인가 말 것인가
시그널과 비교했을 때 여기서의 핵심적인 차이점은, 입력에 값을 썼다고 해서 아무 일도 즉시 일어나지 않는다는 것입니다. 쿼리가 자동으로 재실행되거나 하는 일은 없습니다. 일반적으로 일종의 "라이브" 구독 형태인 UI 프로그래밍의 시그널과 달리, 쿼리는 라이브가 아닙니다.
시그널 시스템에서는 소스 시그널이 변경되면 이를 더티(dirty)로 표시하고, 모든 활성 구독을 따라가며 구독이 트리거된 지점에 도달할 때까지 모든 파생/계산된 시그널을 더티로 표시합니다. 트리거되는 부분은 보통
이펙트(Effect)라고 불립니다. 변경 사항은 시스템을 통해 밀려 나가고(push), 이펙트에 도달하면 재실행되어 새로운 값을 가져옵니다(pull). 물론 라이브러리마다 다양한 최적화 전략을 사용하지만, 이는 이 글의 범위를 벗어납니다. 기억해야 할 중요한 점은 쓰기 작업에 있어 본질적으로 푸시-풀(push-pull) 시스템이라는 것입니다.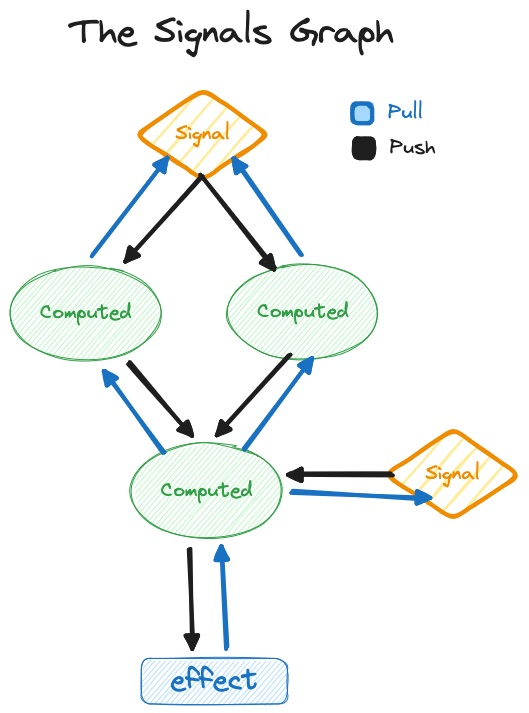
푸시-풀 아키텍처는 UI 렌더링에 완벽합니다. 변경 사항은 종종 즉시 표시되어야 하며, 전체 화면이 동기화된 상태임을 보장해야 합니다. 렌더링된 모든 시그널은 항상 자신이 속한 동일한 리비전(revision)의 값을 보여주어야 합니다. 화면의 윗부분은 새로운 값을 보여주는데 아랫부분은 여전히 오래된 값을 렌더링하는 상황은 결코 일어나서는 안 됩니다. 이를 흔히 "글리치(glitch)"라고 부릅니다. 시스템을 통해 변경 사항을 푸시하는 것은 이러한 일이 발생하지 않도록 보장하는 우아한 방법입니다. 기본적으로 더 빠른 실행과 글리치 없는 결과를 보장하는 대신 더 많은 메모리를 사용하는 방식입니다.
쿼리 기반 컴파일러는 다르게 작동하며, 수요 중심(demand driven)입니다. 재실행되도록 요청해야 합니다. 모든 것이 동일한 틱(tick) 내에 일어나는 것이 그리 중요하지 않습니다. 자동 완성 제안을 위한 쿼리가 먼저 반환되고, 타입 오류를 위한 쿼리가 몇 밀리초 후에 반환되어도 전혀 문제가 없습니다. 프레임당 화면의 동기화를 유지할 필요가 없기 때문입니다. 물론 정확성은 보장되어야 합니다. 하지만 타이밍에 대한 보장은 조금 더 여유롭습니다.
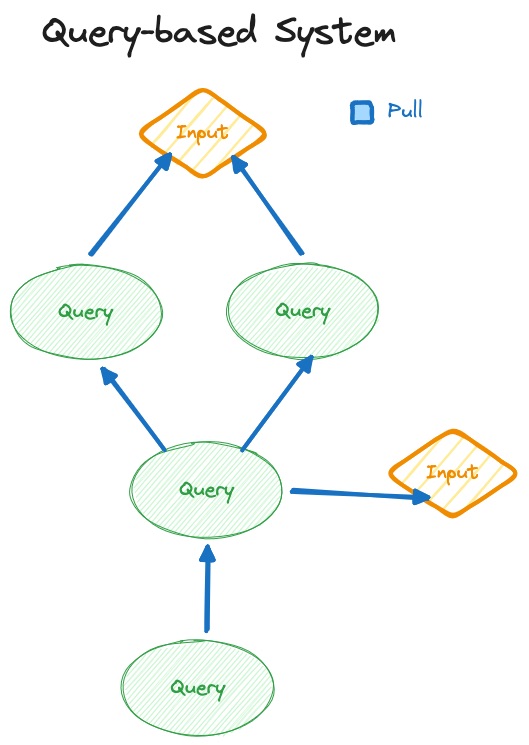
항상 시스템을 통해 변경 사항을 푸시하는 것은 너무 비용이 많이 듭니다. 쿼리 기반 컴파일러는 프로젝트 규모에 따라 쉽게 10만 개 이상의 노드를 가질 수 있기 때문입니다. 그 정도 규모에서는 메모리가 실제 성능 문제로 직결됩니다. 메모리 소비를 줄이기 위해, 시그널이 양방향으로 의존성을 추적하는 것과 달리 쿼리 기반 시스템에서는 의존성을 한 방향으로만 추적합니다.
비법 소스: 리비전(Revisions)
그럼에도 불구하고 시그널과 마찬가지로 쿼리 기반 시스템에서도 정확성은 필수 요구 사항입니다. 그렇다면 쿼리가 서로 다른 시간에 끝날 때 결과가 항상 정확하다는 것을 어떻게 보장할까요? 핵심 통찰은 궁극적으로 쿼리가 입력에 대한 순수 함수라는 점입니다. 동일한 입력이 주어지면 동일한 결과가 나와야 합니다. 따라서 결과는 정확합니다.
시스템 내부에는 입력이 변경될 때마다 증가하는 전역 리비전 카운터가 있습니다. 각 노드에는 캐시된 값의 상태를 확인하는 데 사용할 수 있는
changed_at 및 verified_at 필드가 있습니다.interface Node<T> { changed_at: Revision; verified_at: Revision; value: T; dependencies: Node<any>[];}이를 통해 노드의 캐시된 결과를 재사용할 수 있는지 여부를 알 수 있습니다. 다만, 의존성을 한 방향으로만 추적하기 때문에
verified_at이 현재 리비전과 같아 조기에 중단(bail out)할 수 있는 경우가 아니라면, 리프(leaf) 노드까지 쿼리의 모든 의존성에 대해 항상 더티 체크를 수행해야 합니다. 리프 노드에 도달했을 때 전역 리비전 카운터가 증가했음에도 불구하고 전혀 변경되지 않았음을 확인하면, 부모 노드들의 모든 verified_at 속성을 현재 전역 리비전으로 설정하기만 하면 됩니다. 만약 입력이나 쿼리 결과가 변경되었다면 changed_at과 verified_at 필드를 모두 업데이트합니다. 하지만 의존성이 변경되었음에도 불구하고 어떤 쿼리가 여전히 동일한 결과를 반환한다면, 역시 중단하고 스택을 되감으면서 verified_at 포인터만 업데이트합니다.스레딩(Threading)은 어떨까요?
이것은 쿼리 기반 시스템의 킬러 기능 중 하나입니다. 컴파일할 프로그래밍 언어에 따라 파일 파싱과 같은 작업을 공격적으로 병렬화할 수 있습니다. 각 쿼리가 한 번에 하나의 스레드에 의해서만 실행되도록 보장한다면 많은 작업을 병렬화할 수 있습니다. 쿼리는 매우 세밀한 경향이 있으므로 종종 스레드를 종료하고 최신 리비전으로 다시 생성할 수도 있습니다. 이 부분은 저도 더 깊이 파고들어야 할 영역이지만, 이러한 시스템에서 작업을 재시작하는 것이 가능하다는 점 자체가 흥미롭습니다.
어떤 것이 더 나은가요?
상황에 따라 다릅니다. 시그널은 UI 렌더링에 더 좋고, 쿼리 기반 시스템은 컴파일러에 더 적합합니다. 모든 것은 사용 사례에 달려 있습니다. 어느 쪽이든, 서로 다른 시스템들이 증분(incremental) 시스템을 구현하기 위해 배후에서 유사한 구성 요소와 개념에 도달했다는 점이 흥미롭습니다.
우리의 JavaScript 도구들이 처음부터 증분식으로 구축되었다면 어떤 모습이었을지 궁금합니다. Vite 같은 도구가 쿼리 기반 시스템으로 구축되었다면 어땠을까요? 본질적으로 개발 서버는 서버에서 푸시되는 HMR 업데이트를 제외하면 우리가 끊임없이 데이터를 쿼리하는 살아있는 존재라는 점에서 비슷합니다. 어쩌면 시그널과 쿼리 아키텍처를 혼합하는 것이 정답일지도 모르겠습니다.
0
13
댓글
?
아직 댓글이 없습니다.
첫 번째 댓글을 작성해보세요!
Inkyu Oh님의 다른 글
더보기
번역
useEffectEvent의 즐거움
Inkyu Oh • Front-End
0
0
39

번역
TypeScript 성능 문제 해결: 사례 연구
Inkyu Oh • Front-End
0
0
14
번역
객체 배열(SoA 패턴)이 인터리브 배열을 이기는 이유: JavaScript 성능의 심연
Inkyu Oh • Front-End
0
0
9

번역
AI 에이전트를 위한 좋은 스펙 작성법
Inkyu Oh • AI & ML-ops
0
0
570