[번역] 주관이 뚜렷하고 미니멀한 코딩 에이전트를 만들며 배운 것들
권
권택민
AI & ML-ops•2026.02.13
Mario Zechner - 2025-11-30
2025-11-30
대단한 건 아니지만, 제 것입니다.
- pi-tui
- 보존 모드 UI
- 차분 렌더링
- 계획 모드 없음
- 벤치마크
- 요약하며
지난 3년 동안 저는 코딩 보조를 위해 LLM을 사용해 왔습니다. 이 글을 읽고 계신 여러분도 아마 비슷한 진화 과정을 거쳤을 것입니다. ChatGPT에 코드를 복사해서 붙여넣는 것부터 시작해, (저에게는 한 번도 제대로 작동하지 않았던) Copilot 자동 완성, Cursor를 거쳐, 마침내 2025년 우리의 일상이 된 Claude Code, Codex, Amp, Droid, opencode와 같은 새로운 세대의 코딩 에이전트 하네스(harness)들까지 말이죠.
저는 대부분의 작업에 Claude Code를 선호했습니다. 1년 반 동안 Cursor를 사용한 후 지난 4월에 처음 시도해 본 도구였죠. 당시에는 훨씬 더 기본적이었는데, 단순하고 예측 가능한 도구를 좋아하는 저의 작업 방식에 완벽하게 맞았습니다. 하지만 지난 몇 달 동안 Claude Code는 제가 쓸 일도 없는 기능이 80%나 차 있는 우주선처럼 변해버렸습니다. 시스템 프롬프트와 도구들도 릴리스마다 변경되어 저의 워크플로우를 망가뜨리고 모델의 행동을 변화시킵니다. 저는 그게 정말 싫습니다. 게다가 화면도 깜빡거리고요.
저 또한 수년 동안 다양한 복잡도의 에이전트를 직접 만들어 왔습니다. 예를 들어, 저의 작은 브라우저 사용 에이전트인 Sitegeist는 본질적으로 브라우저 내부에서 작동하는 코딩 에이전트입니다. 그 모든 작업을 통해 저는 컨텍스트 엔지니어링(context engineering)이 무엇보다 중요하다는 것을 배웠습니다. 모델의 컨텍스트에 무엇이 들어가는지 정확하게 제어하는 것이, 특히 코드를 작성할 때 더 나은 결과물을 만들어냅니다. 기존의 하네스들은 UI에 표시조차 되지 않는 것들을 사용자 몰래 주입함으로써 이를 극도로 어렵게 하거나 불가능하게 만듭니다.
표시되는 것에 대해 말하자면, 저는 모델과의 상호작용의 모든 측면을 검사하고 싶습니다. 기본적으로 어떤 하네스도 이를 허용하지 않습니다. 또한 자동으로 후처리할 수 있는 깔끔하게 문서화된 세션 형식을 원하며, 에이전트 코어 위에 대안 UI를 쉽게 구축할 수 있는 방법도 원합니다. 기존 하네스들로도 일부 가능하긴 하지만, API에서 유기적 진화의 냄새가 납니다. 이러한 솔루션들은 개발 과정에서 짐을 쌓아왔고, 그것이 개발자 경험(DX)에 드러납니다. 누구를 탓하는 것은 아닙니다. 수많은 사람이 당신의 결과물을 사용하고 하위 호환성을 유지해야 한다면, 그것은 치러야 할 대가니까요.
저는 로컬과 DataCrunch 모두에서 셀프 호스팅도 시도해 보았습니다. opencode와 같은 일부 하네스는 셀프 호스팅 모델을 지원하지만, 대개 제대로 작동하지 않습니다. 주로 Vercel AI SDK와 같은 라이브러리에 의존하기 때문인데, 이 라이브러리는 어떤 이유에서인지 셀프 호스팅 모델과 잘 맞지 않으며, 특히 도구 호출(tool calling) 부분에서 그렇습니다.
그렇다면 Claude에게 소리나 지르는 이 노병은 무엇을 할까요? 그는 자신만의 코딩 에이전트 하네스를 작성하고, 구글 검색이 전혀 되지 않는 이름을 붙여서 사용자가 아예 없게 만들 것입니다. 즉, GitHub 이슈 트래커에 이슈가 올라올 일도 없다는 뜻이죠. 그게 얼마나 어렵겠어요?
이를 실현하기 위해 저는 다음을 구축해야 했습니다.
- pi-ai: Anthropic, OpenAI, Google, xAI, Groq, Cerebras, OpenRouter 및 모든 OpenAI 호환 엔드포인트를 지원하는 통합 LLM API입니다. 스트리밍, TypeBox 스키마를 사용한 도구 호출, 사고/추론(thinking/reasoning) 지원, 원활한 교차 제공자 컨텍스트 핸드오프, 토큰 및 비용 추적 기능을 갖추고 있습니다.
- pi-agent-core: 도구 실행, 검증 및 이벤트 스트리밍을 처리하는 에이전트 루프입니다.
- pi-tui: 차분 렌더링(differential rendering), (거의) 깜빡임 없는 업데이트를 위한 동기화된 출력을 지원하는 미니멀한 터미널 UI 프레임워크입니다. 자동 완성이 포함된 에디터와 마크다운 렌더링 같은 컴포넌트를 포함합니다.
- pi-coding-agent: 세션 관리, 커스텀 도구, 테마, 프로젝트 컨텍스트 파일 등을 통해 이 모든 것을 하나로 묶어주는 실제 CLI입니다.
이 모든 과정에서의 저의 철학은 "필요하지 않다면 만들지 않는다"였습니다. 그리고 저는 필요한 게 별로 없습니다.
pi-ai 및 pi-agent-core
이 패키지의 구체적인 API 사양으로 여러분을 지루하게 하지는 않겠습니다. README.md에서 모두 읽어보실 수 있습니다. 대신, 통합 LLM API를 만들면서 겪었던 문제들과 이를 어떻게 해결했는지 기록하고 싶습니다. 제 솔루션이 최고라고 주장하는 것은 아니지만, 다양한 에이전트 및 비에이전트 LLM 프로젝트에서 꽤 잘 작동해 왔습니다.
세상에는 오직 네 개의... API가 있습니다
거의 모든 LLM 제공자와 통신하기 위해 알아야 할 API는 사실 네 개뿐입니다. OpenAI의 Completions API, 그들의 새로운 Responses API, Anthropic의 Messages API, 그리고 Google의 Generative AI API입니다.
기능 면에서 모두 꽤 비슷하므로 그 위에 추상화 계층을 만드는 것은 그리 어려운 일이 아닙니다. 물론 신경 써야 할 제공자별 특이사항은 존재합니다. 특히 거의 모든 제공자가 사용하는 Completions API가 그렇습니다. 각 제공자마다 이 API가 무엇을 해야 하는지에 대한 이해가 다릅니다. 예를 들어, OpenAI는 Completions API에서 추론 트레이스(reasoning traces)를 지원하지 않지만, 다른 제공자들은 자신들의 Completions API 버전에서 이를 지원합니다. 이는 llama.cpp, Ollama, vLLM, LM Studio와 같은 추론 엔진에서도 마찬가지입니다.
- Cerebras, xAI, Mistral, Chutes는
store필드를 싫어합니다.
- Mistral과 Chutes는
max_completion_tokens대신max_tokens를 사용합니다.
- Cerebras, xAI, Mistral, Chutes는 시스템 프롬프트를 위한
developer역할을 지원하지 않습니다.
- Grok 모델은
reasoning_effort를 싫어합니다.
- 제공자마다 추론 내용을 반환하는 필드가 다릅니다 (
reasoning_contentvsreasoning).
수많은 제공자에서 모든 기능이 실제로 작동하도록 하기 위해, pi-ai는 이미지 입력, 추론 트레이스, 도구 호출 및 LLM API에서 기대하는 기타 기능들을 다루는 광범위한 테스트 스위트를 갖추고 있습니다. 테스트는 지원되는 모든 제공자와 인기 있는 모델에 대해 실행됩니다. 비록 노력을 많이 기울였지만, 이것이 새로운 모델과 제공자가 즉시 완벽하게 작동할 것임을 보장하지는 않습니다.
또 다른 큰 차이점은 제공자가 토큰과 캐시 읽기/쓰기를 보고하는 방식입니다. Anthropic이 가장 합리적인 접근 방식을 취하고 있지만, 일반적으로는 무법지대입니다. 어떤 곳은 SSE 스트림 시작 부분에 토큰 수를 보고하고, 어떤 곳은 끝에만 보고하여 요청이 중단될 경우 정확한 비용 추적을 불가능하게 만듭니다. 설상가상으로, 나중에 그들의 결제 API와 연동하여 어떤 사용자가 얼마나 많은 토큰을 소비했는지 파악할 수 있는 고유 ID를 제공할 수도 없습니다. 따라서 pi-ai는 최선을 다해 토큰 및 캐시 추적을 수행합니다. 개인적인 용도로는 충분하지만, 서비스를 통해 토큰을 소비하는 최종 사용자가 있는 경우 정확한 과금을 하기에는 부족합니다.
특별히 Google에게 한마디 하자면, 그들은 오늘날까지도 도구 호출 스트리밍을 지원하지 않는 것 같은데, 이는 정말 Google답습니다.
pi-ai는 브라우저에서도 작동하므로 웹 기반 인터페이스를 구축하는 데 유용합니다. 일부 제공자, 특히 Anthropic과 xAI는 CORS를 지원하여 이를 매우 쉽게 만들어줍니다.
컨텍스트 핸드오프
제공자 간의 컨텍스트 핸드오프(Context handoff)는 pi-ai가 처음부터 설계 단계에서 고려한 기능입니다. 각 제공자마다 도구 호출과 사고 트레이스를 추적하는 방식이 다르기 때문에, 이는 최선의 노력(best-effort)일 수밖에 없습니다. 예를 들어, 세션 중간에 Anthropic에서 OpenAI로 전환하면, Anthropic의 사고 트레이스는 어시스턴트 메시지 내부의 콘텐츠 블록으로 변환되며
<thinking></thinking> 태그로 구분됩니다. Anthropic과 OpenAI가 반환하는 사고 트레이스가 실제로 배후에서 일어나는 일을 그대로 나타내는 것은 아니기 때문에, 이것이 항상 합리적이지는 않을 수 있습니다.또한 이러한 제공자들은 이벤트 스트림에 서명된 블롭(signed blobs)을 삽입하며, 동일한 메시지를 포함하는 후속 요청에서 이를 다시 재생(replay)해야 합니다. 이는 제공자 내에서 모델을 전환할 때도 적용됩니다. 이로 인해 백그라운드에서 추상화 및 변환 파이프라인이 번거로워집니다.
다행히 pi-ai에서는 제공자 간 컨텍스트 핸드오프와 컨텍스트 직렬화/역직렬화가 꽤 잘 작동합니다.
import { getModel, complete, Context } from '@mariozechner/pi-ai';// Claude로 시작const claude = getModel('anthropic', 'claude-sonnet-4-5');const context: Context = { messages: []};context.messages.push({ role: 'user', content: '25 * 18은 뭐야?' });const claudeResponse = await complete(claude, context, { thinkingEnabled: true});context.messages.push(claudeResponse);// GPT로 전환 - Claude의 사고 과정을 <thinking> 태그가 붙은 텍스트로 보게 됨const gpt = getModel('openai', 'gpt-5.1-codex');context.messages.push({ role: 'user', content: '그게 맞아?' });const gptResponse = await complete(gpt, context);context.messages.push(gptResponse);// Gemini로 전환const gemini = getModel('google', 'gemini-2.5-flash');context.messages.push({ role: 'user', content: '질문이 뭐였지?' });const geminiResponse = await complete(gemini, context);// 컨텍스트를 JSON으로 직렬화 (저장, 전송 등을 위해)const serialized = JSON.stringify(context);// 나중에: 역직렬화하여 어떤 모델로든 계속 진행const restored: Context = JSON.parse(serialized);restored.messages.push({ role: 'user', content: '우리 대화를 요약해줘' });const continuation = await complete(claude, restored);우리는 멀티 모델의 시대에 살고 있습니다
모델에 대해 말하자면, 저는
getModel 호출 시 모델을 지정하는 타입 안전(typesafe)한 방식을 원했습니다. 이를 위해 TypeScript 타입으로 변환할 수 있는 모델 레지스트리가 필요했습니다. 저는 OpenRouter와 models.dev(opencode 팀이 만든 것인데, 정말 유용합니다. 감사합니다)의 데이터를 파싱하여 models.generated.ts를 생성합니다. 여기에는 토큰 비용과 이미지 입력, 사고 지원 여부와 같은 기능 정보가 포함됩니다.그리고 레지스트리에 없는 모델을 추가해야 할 경우를 대비해, 새로운 모델을 쉽게 만들 수 있는 타입 시스템을 원했습니다. 이는 셀프 호스팅 모델을 사용하거나, 아직 models.dev나 OpenRouter에 올라오지 않은 최신 릴리스를 사용하거나, 좀 더 생소한 LLM 제공자를 시도해 볼 때 특히 유용합니다.
import { Model, stream } from '@mariozechner/pi-ai';const ollamaModel: Model<'openai-completions'> = { id: 'llama-3.1-8b', name: 'Llama 3.1 8B (Ollama)', api: 'openai-completions', provider: 'ollama', baseUrl: 'http://localhost:11434/v1', reasoning: false, input: ['text'], cost: { input: 0, output: 0, cacheRead: 0, cacheWrite: 0 }, contextWindow: 128000, maxTokens: 32000};const response = await stream(ollamaModel, context, { apiKey: 'dummy' // Ollama는 실제 키가 필요 없음});많은 통합 LLM API들이 요청을 중단(abort)하는 방법을 제공하는 것을 완전히 무시합니다. LLM을 어떤 종류의 프로덕션 시스템에 통합하려 한다면 이는 도저히 받아들일 수 없는 일입니다. 또한 많은 통합 API들이 부분적인 결과를 반환하지 않는데, 이는 좀 황당합니다. pi-ai는 도구 호출을 포함한 전체 파이프라인에서 중단을 지원하도록 처음부터 설계되었습니다. 작동 방식은 다음과 같습니다.
import { getModel, stream } from '@mariozechner/pi-ai';const model = getModel('openai', 'gpt-5.1-codex');const controller = new AbortController();// 2초 후 중단setTimeout(() => controller.abort(), 2000);const s = stream(model, { messages: [{ role: 'user', content: '긴 이야기를 써줘' }]}, { signal: controller.signal});for await (const event of s) { if (event.type === 'text_delta') { process.stdout.write(event.delta); } else if (event.type === 'error') { console.log(`${event.reason === 'aborted' ? '중단됨' : '오류'}:`, event.error.errorMessage); }}// 결과 가져오기 (중단된 경우 부분적일 수 있음)const response = await s.result();if (response.stopReason === 'aborted') { console.log('부분 콘텐츠:', response.content);}구조화된 분할 도구 결과
다른 통합 LLM API에서 보지 못한 또 다른 추상화는 도구 결과를 LLM에 전달되는 부분과 UI 표시에 사용되는 부분으로 나누는 것입니다. LLM 부분은 일반적으로 텍스트나 JSON일 뿐이며, UI에 표시하고 싶은 모든 정보를 반드시 포함하고 있지는 않습니다. 또한 텍스트로 된 도구 출력을 파싱하여 UI 표시를 위해 다시 구조화하는 것은 정말 고역입니다. pi-ai의 도구 구현은 LLM을 위한 콘텐츠 블록과 UI 렌더링을 위한 별도의 콘텐츠 블록을 모두 반환할 수 있게 해줍니다. 도구는 또한 각 제공자의 네이티브 형식으로 첨부되는 이미지와 같은 첨부 파일을 반환할 수도 있습니다. 도구 인자는 TypeBox 스키마와 AJV를 사용하여 자동으로 검증되며, 검증 실패 시 상세한 오류 메시지를 제공합니다.
import { Type, AgentTool } from '@mariozechner/pi-ai';const weatherSchema = Type.Object({ city: Type.String({ minLength: 1 }),});const weatherTool: AgentTool<typeof weatherSchema, { temp: number }> = { name: 'get_weather', description: '도시의 현재 날씨를 가져옵니다', parameters: weatherSchema, execute: async (toolCallId, args) => { const temp = Math.round(Math.random() * 30); return { // LLM을 위한 텍스트 output: `${args.city}의 온도: ${temp}°C`, // UI를 위한 구조화된 데이터 details: { temp } }; }};// 도구는 이미지도 반환할 수 있음const chartTool: AgentTool = { name: 'generate_chart', description: '데이터로부터 차트를 생성합니다', parameters: Type.Object({ data: Type.Array(Type.Number()) }), execute: async (toolCallId, args) => { const chartImage = await generateChartImage(args.data); return { content: [ { type: 'text', text: `${args.data.length}개의 데이터 포인트로 차트를 생성했습니다` }, { type: 'image', data: chartImage.toString('base64'), mimeType: 'image/png' } ] }; }};아직 부족한 점은 도구 결과 스트리밍입니다. bash 도구에서 ANSI 시퀀스가 들어오는 대로 표시하고 싶다고 상상해 보세요. 현재는 불가능하지만, 결국 패키지에 반영될 간단한 수정 사항입니다.
도구 호출 스트리밍 중 부분 JSON 파싱은 좋은 UX를 위해 필수적입니다. LLM이 도구 호출 인자를 스트리밍할 때, pi-ai는 이를 점진적으로 파싱하여 호출이 완료되기 전에 UI에서 부분적인 결과를 보여줄 수 있게 합니다. 예를 들어, 에이전트가 파일을 다시 작성할 때 스트리밍되는 diff를 표시할 수 있습니다.
미니멀한 에이전트 스캐폴드
마지막으로, pi-ai는 전체 오케스트레이션을 처리하는 에이전트 루프(agent loop)를 제공합니다. 사용자 메시지 처리, 도구 호출 실행, 결과를 LLM에 다시 전달, 그리고 모델이 도구 호출 없이 응답을 생성할 때까지 반복하는 과정을 관리합니다. 루프는 콜백을 통한 메시지 큐잉도 지원합니다. 각 턴이 끝난 후 큐에 대기 중인 메시지가 있는지 묻고, 다음 어시스턴트 응답 전에 이를 주입합니다. 루프는 모든 과정에 대해 이벤트를 발생시키므로 반응형 UI를 쉽게 구축할 수 있습니다.
에이전트 루프는 다른 통합 LLM API에서 볼 수 있는 최대 단계(max steps) 설정 같은 조절 장치를 제공하지 않습니다. 그런 기능이 필요한 유스케이스를 찾지 못했기에 굳이 추가할 이유가 없었습니다. 루프는 에이전트가 끝났다고 말할 때까지 그냥 반복합니다. 하지만 루프 위에서 pi-agent-core는 실제로 유용한 것들을 갖춘
Agent 클래스를 제공합니다. 상태 관리, 단순화된 이벤트 구독, 두 가지 모드(하나씩 또는 한꺼번에)의 메시지 큐잉, 첨부 파일 처리(이미지, 문서), 그리고 에이전트를 직접 실행하거나 프록시를 통해 실행할 수 있게 해주는 전송(transport) 추상화 등이 포함됩니다.pi-ai에 만족하냐고요? 대부분 그렇습니다. 다른 통합 API와 마찬가지로, 누수되는 추상화(leaky abstractions) 때문에 완벽할 수는 없습니다. 하지만 이미 7개의 서로 다른 프로덕션 프로젝트에서 사용되었고 저에게 매우 큰 도움이 되었습니다.
왜 Vercel AI SDK를 사용하는 대신 이걸 만들었을까요? Armin의 블로그 포스트가 제 경험을 그대로 반영하고 있습니다. 제공자 SDK를 직접 활용하여 구축하면 모든 제어권을 가질 수 있고, 훨씬 작은 표면적으로 제가 원하는 대로 정확하게 API를 설계할 수 있습니다. Armin의 블로그에서 직접 구축해야 하는 이유에 대한 더 심도 있는 논의를 읽어보실 수 있습니다. 꼭 읽어보세요.
pi-tui
저는 DOS 시대에 자랐기 때문에 터미널 사용자 인터페이스(TUI)에 익숙합니다. Doom의 화려한 설정 프로그램부터 Borland 제품들까지, TUI는 90년대 말까지 저와 함께했습니다. 그리고 마침내 GUI 운영체제로 전환했을 때 얼마나 기뻤는지 모릅니다. TUI는 대부분 이식성이 좋고 스트리밍하기 쉽지만, 정보 밀도 면에서는 형편없습니다. 그럼에도 불구하고, pi를 위한 터미널 사용자 인터페이스부터 시작하는 것이 가장 합리적이라고 생각했습니다. 나중에 필요하다고 느껴지면 GUI를 덧붙이면 되니까요.
그렇다면 왜 나만의 TUI 프레임워크를 만들었을까요? Ink, Blessed, OpenTUI 같은 대안들을 살펴보았습니다. 모두 나름의 장점이 있겠지만, 저는 TUI를 React 앱처럼 작성하고 싶지는 않았습니다. Blessed는 대부분 관리되지 않는 것 같고, OpenTUI는 명시적으로 프로덕션 준비가 되지 않았다고 합니다. 또한 Node.js 위에서 나만의 TUI 프레임워크를 작성하는 것은 재미있는 도전처럼 보였습니다.
두 종류의 TUI
터미널 사용자 인터페이스를 작성하는 것 자체가 고도의 기술은 아닙니다. 그저 어떤 방식을 선택하느냐의 문제입니다. 기본적으로 두 가지 방법이 있습니다. 하나는 터미널 뷰포트(실제로 볼 수 있는 터미널 내용의 일부)의 소유권을 가져와 픽셀 버퍼처럼 취급하는 것입니다. 픽셀 대신 배경색, 전경색, 그리고 이탤릭이나 굵게 같은 스타일을 가진 문자가 들어있는 셀(cell)을 사용합니다. 저는 이를 전체 화면(full screen) TUI라고 부릅니다. Amp와 opencode가 이 방식을 사용합니다.
단점은 스크롤백 버퍼(scrollback buffer)를 잃게 된다는 것입니다. 즉, 커스텀 검색을 직접 구현해야 합니다. 또한 스크롤 기능도 잃게 되어 뷰포트 내에서의 스크롤을 직접 시뮬레이션해야 합니다. 구현이 어렵지는 않지만, 터미널 에뮬레이터가 이미 제공하는 모든 기능을 다시 구현해야 함을 의미합니다. 특히 마우스 스크롤은 이런 TUI에서 항상 어색하게 느껴집니다.
두 번째 접근 방식은 일반적인 CLI 프로그램처럼 터미널에 내용을 쓰고 스크롤백 버퍼에 추가하되, 가끔 "렌더링 커서"를 가시 뷰포트 내에서 조금 위로 옮겨 애니메이션 스피너나 텍스트 입력 필드 같은 것들을 다시 그리는 것입니다. 정확히 그렇게 간단하지는 않지만 개념은 그렇습니다. Claude Code, Codex, Droid가 이 방식을 사용합니다.
코딩 에이전트는 기본적으로 채팅 인터페이스라는 좋은 특성을 가지고 있습니다. 사용자가 프롬프트를 작성하면 에이전트의 답변과 도구 호출 및 결과가 뒤따릅니다. 모든 것이 깔끔하게 선형적이어서 "네이티브" 터미널 에뮬레이터와 작업하기에 적합합니다. 스크롤백 버퍼 내에서의 자연스러운 스크롤과 검색 같은 내장 기능을 그대로 사용할 수 있습니다. 또한 TUI가 할 수 있는 일을 어느 정도 제한하는데, 저는 제약 조건이 불필요한 군더더기 없이 제 할 일만 하는 미니멀한 프로그램을 만든다는 점에서 이를 매력적으로 느낍니다. 이것이 제가 pi-tui를 위해 선택한 방향입니다.
보존 모드 UI
GUI 프로그래밍을 해보셨다면 보존 모드(retained mode)와 즉시 모드(immediate mode)에 대해 들어보셨을 것입니다. 보존 모드 UI에서는 프레임이 바뀌어도 유지되는 컴포넌트 트리를 구축합니다. 각 컴포넌트는 자신을 렌더링하는 방법을 알고 있으며, 변경 사항이 없으면 출력을 캐싱할 수 있습니다. 즉시 모드 UI에서는 매 프레임마다 모든 것을 처음부터 다시 그립니다(실제로는 즉시 모드 UI도 캐싱을 합니다. 그렇지 않으면 성능이 버티지 못하니까요).
pi-tui는 단순한 보존 모드 방식을 사용합니다.
Component는 render(width) 메서드(뷰포트 가로 폭에 맞게 줄 바꿈된 문자열 배열을 반환하며, 색상과 스타일을 위한 ANSI 이스케이프 코드를 포함함)와 키보드 입력을 위한 선택적인 handleInput(data) 메서드를 가진 객체일 뿐입니다. Container는 수직으로 배치된 컴포넌트 목록을 보유하고 이들의 모든 렌더링된 라인을 수집합니다. TUI 클래스 자체가 모든 것을 조율하는 컨테이너입니다.TUI가 화면을 업데이트해야 할 때, 각 컴포넌트에 렌더링을 요청합니다. 컴포넌트는 출력을 캐싱할 수 있습니다. 완전히 스트리밍된 어시스턴트 메시지는 매번 마크다운을 파싱하고 ANSI 시퀀스를 다시 렌더링할 필요가 없습니다. 그냥 캐싱된 라인들을 반환하면 됩니다. 컨테이너는 모든 자식 컴포넌트로부터 라인들을 수집합니다. TUI는 이 모든 라인을 모아서 이전 컴포넌트 트리에서 렌더링했던 라인들과 비교합니다. 일종의 백버퍼(backbuffer)를 유지하며 스크롤백 버퍼에 무엇이 쓰였는지 기억하는 것이죠.
그런 다음 제가 차분 렌더링(differential rendering)이라고 부르는 방법을 사용하여 변경된 부분만 다시 그립니다. 저는 이름 짓는 재주가 없어서, 아마 공식적인 명칭이 따로 있을 것입니다.
차분 렌더링
정확히 어떤 부분이 다시 그려지는지 보여주는 단순화된 데모입니다.
$ pi
╭─────────────────────────────────╮
│ > _ │
╰─────────────────────────────────╯
▶ 클릭하여 시작 | 다시 그려진 라인: 0/10
알고리즘은 간단합니다.
- 첫 렌더링: 모든 라인을 터미널에 출력합니다.
- 너비 변경: 화면을 완전히 지우고 모든 것을 다시 렌더링합니다(소프트 랩핑이 변경되므로).
- 일반 업데이트: 화면에 있는 내용과 다른 첫 번째 라인을 찾아 커서를 해당 라인으로 이동시킨 후, 거기서부터 끝까지 다시 렌더링합니다.
한 가지 주의할 점이 있습니다. 변경된 첫 번째 라인이 가시 뷰포트보다 위에 있다면(사용자가 위로 스크롤한 경우), 전체를 지우고 다시 렌더링해야 합니다. 터미널은 뷰포트 위의 스크롤백 버퍼에 쓰는 것을 허용하지 않기 때문입니다.
업데이트 중 깜빡임을 방지하기 위해, pi-tui는 모든 렌더링을 동기화된 출력 이스케이프 시퀀스(
CSI ?2026h 및 CSI ?2026l)로 감쌉니다. 이는 터미널에 모든 출력을 버퍼링했다가 원자적으로(atomically) 표시하라고 지시하는 것입니다. 대부분의 현대적인 터미널은 이를 지원합니다.얼마나 잘 작동하고 깜빡임은 어느 정도일까요? Ghostty나 iTerm2 같은 성능 좋은 터미널에서는 훌륭하게 작동하며 깜빡임을 전혀 볼 수 없습니다. VS Code의 내장 터미널 같은 덜 운 좋은 터미널 구현에서는 시간대, 디스플레이 크기, 윈도우 크기 등에 따라 약간의 깜빡임이 발생할 수 있습니다. 제가 Claude Code에 매우 익숙해져 있다는 점을 고려하면, 이를 최적화하는 데 더 이상의 시간을 쓰지는 않았습니다. VS Code에서 발생하는 약간의 깜빡임에는 만족합니다. 그렇지 않으면 오히려 내 집 같지 않을 것 같거든요. 그리고 여전히 Claude Code보다는 덜 깜빡입니다.
이 방식이 얼마나 낭비일까요? 우리는 이전에 렌더링된 라인들을 스크롤백 버퍼 전체만큼 저장하고, TUI가 렌더링을 요청받을 때마다 라인들을 다시 렌더링합니다. 위에서 설명한 캐싱 덕분에 다시 렌더링하는 것이 큰 문제는 아닙니다. 여전히 많은 라인을 서로 비교해야 하긴 합니다. 현실적으로 25년 이내에 만들어진 컴퓨터라면 성능이나 메모리 사용량(매우 큰 세션의 경우 수백 킬로바이트 정도) 측면에서 큰 문제가 되지 않습니다. V8 엔진 덕분이죠. 그 대가로 제가 얻는 것은 빠르게 반복 개발할 수 있는 아주 단순한 프로그래밍 모델입니다.
pi-coding-agent
코딩 에이전트 하네스에서 기대할 만한 기능들을 일일이 설명할 필요는 없을 것 같습니다. pi는 다른 도구들에서 익숙한 대부분의 편의 기능을 갖추고 있습니다.
- Windows, Linux, macOS(또는 Node.js 런타임과 터미널이 있는 모든 환경)에서 실행 가능
- 세션 중간 모델 전환을 포함한 멀티 제공자 지원
- 계속하기(continue), 재개하기(resume), 브랜칭(branching)을 포함한 세션 관리
- 전역에서 프로젝트별 설정까지 계층적으로 로드되는 프로젝트 컨텍스트 파일(AGENTS.md)
- 일반적인 작업을 위한 슬래시 명령(Slash commands)
- 인자 지원이 포함된 마크다운 템플릿 형태의 커스텀 슬래시 명령
- Claude Pro/Max 구독을 위한 OAuth 인증
- JSON을 통한 커스텀 모델 및 제공자 설정
- 라이브 리로드를 지원하는 커스터마이징 가능한 테마
- 퍼지 파일 검색, 경로 완성, 드래그 앤 드롭, 멀티라인 붙여넣기를 지원하는 에디터
- 에이전트 작업 중 메시지 큐잉
- 비전 지원 모델을 위한 이미지 지원
- 세션의 HTML 내보내기
- JSON 스트리밍 및 RPC 모드를 통한 헤드리스(headless) 운영
- 전체 비용 및 토큰 추적
최소한의 시스템 프롬프트
시스템 프롬프트는 다음과 같습니다.
당신은 전문 코딩 어시스턴트입니다. 파일을 읽고, 명령을 실행하고, 코드를 편집하고, 새 파일을 작성하여 사용자의 코딩 작업을 돕습니다.사용 가능한 도구:- read: 파일 내용 읽기- bash: bash 명령 실행- edit: 파일에 대한 외과적 편집 수행- write: 파일 생성 또는 덮어쓰기가이드라인:- ls, grep, find와 같은 파일 작업에는 bash를 사용하세요.- 편집하기 전에 read를 사용하여 파일을 검토하세요.- 정밀한 변경에는 edit를 사용하세요 (이전 텍스트가 정확히 일치해야 함).- 새 파일이나 전체 재작성에만 write를 사용하세요.- 수행한 작업을 요약할 때, 텍스트를 직접 출력하세요. 수행한 내용을 표시하기 위해 cat이나 bash를 사용하지 마세요.- 응답은 간결하게 하세요.- 파일 작업 시 파일 경로를 명확하게 표시하세요.문서:- 당신의 자체 문서(커스텀 모델 설정 및 테마 생성 포함)는 다음 위치에 있습니다: /path/to/README.md- 사용자가 기능, 설정 또는 구성에 대해 묻거나, 특히 커스텀 모델/제공자 추가 또는 커스텀 테마 생성을 요청할 때 이 문서를 읽으세요.이게 전부입니다. 하단에 주입되는 유일한 것은 사용자의 AGENTS.md 파일입니다. 모든 세션에 적용되는 전역 파일과 프로젝트 디렉토리에 저장된 프로젝트별 파일 모두 해당됩니다. 여기서 pi를 원하는 대로 커스터마이징할 수 있습니다. 원한다면 전체 시스템 프롬프트를 교체할 수도 있습니다. 예를 들어, Claude Code의 시스템 프롬프트, Codex의 시스템 프롬프트, 또는 opencode의 모델별 프롬프트(Claude용은 그들이 복사한 원본 Claude Code 프롬프트를 축소한 버전입니다)와 비교해 보세요.
미친 짓이라고 생각하실 수도 있습니다. 십중팔구 모델들은 자신들의 네이티브 코딩 하네스에 대해 어느 정도 훈련을 받았을 것입니다. 따라서 네이티브 시스템 프롬프트나 opencode처럼 그와 유사한 것을 사용하는 것이 가장 이상적일 것입니다. 하지만 나중에 벤치마크 섹션에서 확인하겠지만, 그리고 제가 지난 몇 주 동안 pi를 독점적으로 사용하며 경험적으로 알아낸 바에 따르면, 모든 프런티어 모델들은 이미 충분히 RL(강화 학습) 훈련을 받았기 때문에 코딩 에이전트가 무엇인지 본질적으로 이해하고 있습니다. 10,000 토큰에 달하는 시스템 프롬프트는 필요하지 않은 것으로 보입니다. Amp 또한 네이티브 시스템 프롬프트의 일부를 복사하긴 했지만, 자신들만의 프롬프트로도 충분히 잘 해내고 있는 것 같습니다.
최소한의 도구 세트
도구 정의는 다음과 같습니다.
read 파일의 내용을 읽습니다. 텍스트 파일과 이미지(jpg, png, gif, webp)를 지원합니다. 이미지는 첨부 파일로 전송됩니다. 텍스트 파일의 경우 기본적으로 처음 2000행을 읽습니다. 큰 파일의 경우 offset/limit을 사용하세요. - path: 읽을 파일 경로 (상대 또는 절대 경로) - offset: 읽기 시작할 행 번호 (1부터 시작) - limit: 읽을 최대 행 수write 파일에 내용을 씁니다. 파일이 없으면 생성하고, 있으면 덮어씁니다. 상위 디렉토리를 자동으로 생성합니다. - path: 쓸 파일 경로 (상대 또는 절대 경로) - content: 파일에 쓸 내용edit 정확한 텍스트를 교체하여 파일을 편집합니다. oldText는 (공백 포함) 정확히 일치해야 합니다. 정밀하고 외과적인 편집에 사용하세요. - path: 편집할 파일 경로 (상대 또는 절대 경로) - oldText: 찾아 교체할 정확한 텍스트 (정확히 일치해야 함) - newText: 이전 텍스트를 교체할 새 텍스트bash 현재 작업 디렉토리에서 bash 명령을 실행합니다. stdout과 stderr을 반환합니다. 선택적으로 초 단위의 타임아웃을 제공할 수 있습니다. - command: 실행할 bash 명령 - timeout: 초 단위 타임아웃 (선택 사항, 기본 타임아웃 없음)에이전트가 파일을 수정하거나 임의의 명령을 실행하는 것을 제한하고 싶을 때를 위한 추가적인 읽기 전용 도구(grep, find, ls)도 있습니다. 기본적으로 이들은 비활성화되어 있으며, 에이전트는 위의 네 가지 도구만 가집니다.
결과적으로 이 네 가지 도구만 있으면 효과적인 코딩 에이전트를 만드는 데 충분합니다. 모델들은 bash 사용법을 알고 있으며, 유사한 입력 스펙을 가진 read, write, edit 도구들에 대해 훈련받았습니다. 이를 Claude Code의 도구 정의나 opencode의 도구 정의(구조, 예시, git 커밋 흐름 등이 Claude Code에서 파생된 것이 분명함)와 비교해 보세요. 특히 Codex의 도구 정의는 pi만큼이나 미니멀합니다.
pi의 시스템 프롬프트와 도구 정의를 합쳐도 1000 토큰이 되지 않습니다.
기본 설정은 YOLO
pi는 완전한 YOLO 모드로 실행되며 사용자가 자신이 무엇을 하는지 알고 있다고 가정합니다. 파일 시스템에 대한 무제한 접근 권한을 가지며 권한 확인이나 안전 장치 없이 모든 명령을 실행할 수 있습니다. 파일 작업이나 명령 실행 시 권한 요청 팝업이 뜨지 않습니다. 악성 콘텐츠 여부를 확인하기 위해 Haiku가 bash 명령을 미리 검사하지도 않습니다. 전체 파일 시스템 접근이 가능하며, 사용자의 권한으로 모든 명령을 실행할 수 있습니다.
다른 코딩 에이전트들의 보안 조치들을 살펴보면, 대부분 보안 연극(security theater)에 불과합니다. 에이전트가 코드를 작성하고 실행할 수 있게 되는 순간, 이미 게임은 끝난 것이나 다름없습니다. 데이터 유출을 방지할 수 있는 유일한 방법은 에이전트가 실행되는 환경의 모든 네트워크 접근을 차단하는 것인데, 이는 에이전트를 거의 쓸모없게 만듭니다. 도메인 허용 목록(allow-listing)을 사용하는 대안도 있지만, 이 또한 다른 수단을 통해 우회될 수 있습니다.
Simon Willison은 이 문제에 대해 광범위하게 글을 썼습니다. 그의 "이중 LLM(dual LLM)" 패턴은 혼동된 대리인 공격(confused deputy attacks)과 데이터 유출 문제를 해결하려 시도하지만, 그조차도 "이 솔루션은 꽤 별로"이며 엄청난 구현 복잡성을 초래한다고 인정합니다. 핵심 문제는 여전합니다. LLM이 비공개 데이터를 읽고 네트워크 요청을 보낼 수 있는 도구에 접근할 수 있다면, 당신은 공격 벡터와 두더지 잡기 게임을 하고 있는 것입니다.
이 세 가지 능력(데이터 읽기, 코드 실행, 네트워크 접근)의 딜레마를 해결할 수 없기에, pi는 그냥 포기했습니다. 어차피 생산적인 일을 하기 위해 모두가 YOLO 모드로 실행하고 있는데, 그냥 기본이자 유일한 옵션으로 만드는 게 어떨까요?
기본적으로 pi에는 웹 검색이나 fetch 도구가 없습니다. 하지만
curl을 사용하거나 디스크에서 파일을 읽을 수 있으며, 이 두 가지 모두 프롬프트 주입(prompt injection) 공격의 충분한 표면적을 제공합니다. 파일이나 명령 출력의 악성 콘텐츠가 행동에 영향을 줄 수 있습니다. 전체 접근 권한이 불안하다면 컨테이너 내부에서 pi를 실행하거나, (가짜) 가드레일이 필요한 경우 다른 도구를 사용하세요.내장된 할 일 목록 없음
pi는 내장된 할 일(to-do) 목록을 지원하지 않으며 앞으로도 지원하지 않을 것입니다. 제 경험상 할 일 목록은 모델에게 도움을 주기보다 혼란을 주는 경우가 더 많습니다. 모델이 추적하고 업데이트해야 할 상태를 추가함으로써, 일이 잘못될 가능성만 더 높입니다.
작업 추적이 필요하다면 파일에 기록하여 외부 상태로 만드세요.
# TODO.md- [x] 사용자 인증 구현- [x] 데이터베이스 마이그레이션 추가- [ ] API 문서 작성- [ ] 속도 제한(rate limiting) 추가에이전트는 필요에 따라 이 파일을 읽고 업데이트할 수 있습니다. 체크박스를 사용하면 완료된 작업과 남은 작업을 추적할 수 있습니다. 단순하고, 눈에 보이며, 당신의 제어 하에 있습니다.
계획 모드 없음
pi에는 내장된 계획(plan) 모드가 없으며 앞으로도 없을 것입니다. 파일을 수정하거나 명령을 실행하지 않고 에이전트에게 문제에 대해 함께 생각해보라고 말하는 것만으로도 대개 충분합니다.
세션 간에 지속되는 계획이 필요하다면 파일에 작성하세요.
# PLAN.md## 목표OAuth를 지원하도록 인증 시스템 리팩토링## 접근 방식1. OAuth 2.0 흐름 조사2. 토큰 저장 스키마 설계3. 인증 서버 엔드포인트 구현4. 클라이언트 측 로그인 흐름 업데이트5. 테스트 추가## 현재 단계3단계 작업 중 - 인증 엔드포인트에이전트는 작업하면서 계획을 읽고, 업데이트하고, 참조할 수 있습니다. 세션 내에서만 존재하는 일시적인 계획 모드와 달리, 파일 기반 계획은 세션 간에 공유될 수 있으며 코드와 함께 버전 관리가 가능합니다.
재밌게도 Claude Code에는 이제 계획 모드가 생겼는데, 이는 본질적으로 읽기 전용 분석이며 결국 마크다운 파일을 디스크에 작성하게 됩니다. 그리고 수많은 명령 실행을 승인하지 않고는 계획 모드를 사실상 사용할 수 없는데, 그 승인 없이는 계획 자체가 불가능하기 때문입니다.
pi와의 차이점은 제가 모든 것에 대해 완전한 관찰 가능성(observability)을 갖는다는 것입니다. 에이전트가 실제로 어떤 소스를 보았고 어떤 것을 완전히 놓쳤는지 확인할 수 있습니다. Claude Code에서는 오케스트레이션을 담당하는 Claude 인스턴스가 대개 서브 에이전트를 생성하며, 당신은 그 서브 에이전트가 무엇을 하는지 전혀 알 수 없습니다. 저는 마크다운 파일을 즉시 볼 수 있습니다. 에이전트와 협력하여 편집할 수도 있습니다. 요컨대, 저는 계획을 위해 관찰 가능성이 필요하지만 Claude Code의 계획 모드에서는 그것을 얻을 수 없습니다.
계획 중에 에이전트를 반드시 제한해야 한다면 CLI를 통해 접근 가능한 도구를 지정할 수 있습니다.
pi --tools read,grep,find,ls이렇게 하면 에이전트가 아무것도 수정하거나 bash 명령을 실행할 수 없는 탐색 및 계획용 읽기 전용 모드가 됩니다. 하지만 아마 만족스럽지는 않을 것입니다.
MCP 지원 없음
pi는 MCP를 지원하지 않으며 앞으로도 지원하지 않을 것입니다. 이에 대해 광범위하게 글을 쓴 적이 있지만, 요약하자면 MCP 서버는 대부분의 유스케이스에 과하며 상당한 컨텍스트 오버헤드를 수반합니다.
Playwright MCP(도구 21개, 13.7k 토큰)나 Chrome DevTools MCP(도구 26개, 18k 토큰) 같은 인기 있는 MCP 서버들은 매 세션마다 전체 도구 설명을 컨텍스트에 쏟아붓습니다. 작업을 시작하기도 전에 컨텍스트 윈도우의 7~9%가 사라지는 셈입니다. 이 도구들 중 상당수는 해당 세션에서 한 번도 쓰이지 않을 것입니다.
대안은 간단합니다. README 파일이 포함된 CLI 도구를 만드는 것입니다. 에이전트는 도구가 필요할 때 README를 읽고, 필요할 때만 토큰 비용을 지불하며(점진적 공개), bash를 사용하여 도구를 호출할 수 있습니다. 이 접근 방식은 조합 가능하고(출력 파이프 연결, 명령 체이닝), 확장하기 쉬우며(스크립트 추가), 토큰 효율적입니다.
제가 pi에 웹 검색 기능을 추가하는 방법은 다음과 같습니다.
저는 github.com/badlogic/agent-tools에서 이러한 도구 모음을 관리하고 있습니다. 각 도구는 에이전트가 필요할 때 읽는 README가 포함된 단순한 CLI입니다.
백그라운드 bash 없음
pi의 bash 도구는 명령을 동기적으로 실행합니다. 개발 서버를 시작하거나, 백그라운드에서 테스트를 실행하거나, 명령이 실행되는 동안 REPL과 상호작용하는 내장된 방법은 없습니다.
이는 의도된 것입니다. 백그라운드 프로세스 관리는 복잡성을 더합니다. 프로세스 추적, 출력 버퍼링, 종료 시 정리, 실행 중인 프로세스에 입력을 보내는 방법 등이 필요합니다. Claude Code는 백그라운드 bash 기능으로 이 중 일부를 처리하지만, 관찰 가능성이 떨어지며(Claude Code의 공통적인 테마입니다) 에이전트가 실행 중인 인스턴스를 쿼리할 도구도 없이 이를 추적하도록 강제합니다. 초기 Claude Code 버전에서는 컨텍스트 압축(compaction) 후에 에이전트가 백그라운드 프로세스를 잊어버리고 쿼리할 방법도 없어서 수동으로 죽여야 했습니다. 지금은 수정되었습니다.
관찰 가능성이 이 정도면 훌륭하지 않나요? 동일한 접근 방식이 오래 실행되는 개발 서버, 로그 출력 모니터링 및 유사한 유스케이스에도 적용됩니다. 원한다면 위의 LLDB 세션에 tmux를 통해 직접 들어가서 에이전트와 함께 공동 디버깅을 할 수도 있습니다. Tmux는 또한 활성 세션을 모두 나열하는 CLI 인자도 제공합니다. 얼마나 좋습니까.
백그라운드 bash는 전혀 필요 없습니다. Claude Code도 tmux를 사용할 수 있습니다. Bash만 있으면 충분합니다.
서브 에이전트 없음
pi에는 전용 서브 에이전트 도구가 없습니다. Claude Code는 복잡한 작업이 필요할 때 종종 서브 에이전트를 생성하여 작업의 일부를 처리하게 합니다. 당신은 그 서브 에이전트가 무엇을 하는지 전혀 알 수 없습니다. 블랙박스 안의 블랙박스인 셈입니다. 에이전트 간의 컨텍스트 전달도 부실합니다. 오케스트레이션 에이전트가 서브 에이전트에게 전달할 초기 컨텍스트를 결정하며, 당신은 대개 이를 제어할 수 없습니다. 서브 에이전트가 실수를 하면 전체 대화를 볼 수 없기 때문에 디버깅이 고통스럽습니다.
pi가 자기 자신을 생성하게 하려면 그냥 bash를 통해 실행하라고 시택하세요. 완전한 관찰 가능성과 서브 에이전트와 직접 상호작용할 수 있는 능력을 갖추기 위해 tmux 세션 내부에서 실행하게 할 수도 있습니다.
하지만 더 중요한 것은, 적어도 컨텍스트 수집에 관한 워크플로우를 수정하는 것입니다. 사람들은 세션 내에서 서브 에이전트를 사용하면 컨텍스트 공간을 절약할 수 있다고 생각하며, 이는 사실입니다. 하지만 그것은 서브 에이전트에 대한 잘못된 생각입니다. 세션 중간에 컨텍스트 수집을 위해 서브 에이전트를 사용하는 것은 미리 계획을 세우지 않았다는 신호입니다. 컨텍스트 수집이 필요하다면 먼저 별도의 세션에서 수행하세요. 나중에 새로운 세션에서 사용할 수 있는 아티팩트(artifact)를 만들어, 도구 출력으로 컨텍스트 윈도우를 오염시키지 않고 에이전트에게 필요한 모든 컨텍스트를 제공하세요. 그 아티팩트는 다음 기능을 구현할 때도 유용할 수 있으며, 컨텍스트 수집 과정에서 중요한 관찰 가능성과 조종 가능성(steerability)을 얻을 수 있습니다.
대중적인 믿음과 달리, 모델은 여전히 새로운 기능을 구현하거나 버그를 수정하는 데 필요한 모든 컨텍스트를 찾는 데 서툽니다. 저는 이것이 모델들이 파일 전체가 아닌 일부만 읽도록 훈련받았기 때문이라고 생각하며, 그래서 모든 것을 읽기를 주저합니다. 이는 중요한 컨텍스트를 놓치고 작업을 제대로 완료하기 위해 필요한 것을 보지 못한다는 것을 의미합니다.
pi-mono 이슈 트래커와 풀 리퀘스트(PR)들을 보세요. 에이전트가 무엇이 필요한지 완전히 파악하지 못해 닫히거나 수정되는 경우가 많습니다. 이는 기여자들의 잘못이 아닙니다. 불완전한 PR이라도 제가 더 빨리 움직이는 데 도움이 되기에 진심으로 감사하게 생각합니다. 단지 우리가 에이전트를 너무 과신하고 있다는 뜻일 뿐입니다.
서브 에이전트를 완전히 부정하는 것은 아닙니다. 유효한 유스케이스들이 있습니다. 제가 가장 흔히 사용하는 것은 코드 리뷰입니다. pi에게 코드 리뷰 프롬프트(커스텀 슬래시 명령을 통해)와 함께 자기 자신을 생성하라고 말하면 결과를 가져옵니다.
---description: 코드 리뷰 서브 에이전트 실행---bash를 통해 자기 자신을 서브 에이전트로 생성하여 코드 리뷰를 수행하세요: $@적절한 인자와 함께 `pi --print`를 사용하세요. 사용자가 모델을 지정하면`--provider`와 `--model`을 그에 맞춰 사용하세요.서브 에이전트에게 다음 사항을 리뷰하도록 프롬프트를 전달하세요:- 버그 및 로직 오류- 보안 문제- 에러 처리 누락당신이 직접 코드를 읽지 마세요. 서브 에이전트가 하도록 하세요.서브 에이전트의 발견 사항을 보고하세요.GitHub에서 풀 리퀘스트를 리뷰하기 위해 이를 사용하는 방법은 다음과 같습니다.
단순한 프롬프트로 리뷰하고 싶은 구체적인 내용과 사용할 모델을 선택할 수 있습니다. 원한다면 사고 수준(thinking levels)을 설정할 수도 있습니다. 또한 전체 리뷰 세션을 파일로 저장하고 원한다면 다른 pi 세션에서 해당 파일로 들어갈 수도 있습니다. 또는 이것이 일시적인 세션이며 디스크에 저장되지 않아야 한다고 말할 수도 있습니다. 이 모든 것이 메인 에이전트가 읽는 프롬프트로 번역되고, 메인 에이전트는 그에 따라 bash를 통해 자기 자신을 다시 실행합니다. 서브 에이전트의 내부 작동 방식에 대한 완전한 관찰 가능성은 얻지 못하더라도, 그 출력에 대해서는 완전한 관찰 가능성을 얻습니다. 다른 하네스들이 제공하지 않는 기능인데, 저로서는 이해가 가지 않습니다.
물론 이것은 약간 시뮬레이션된 유스케이스입니다. 실제로는 그냥 새로운 pi 세션을 열고 풀 리퀘스트를 리뷰해달라고 하거나, 로컬 브랜치로 가져오라고 할 것입니다. 초기 리뷰를 본 후 제 의견을 주고, 코드가 좋아질 때까지 함께 작업할 것입니다. 그것이 제가 쓰레기 코드를 머지하지 않기 위해 사용하는 워크플로우입니다.
여러 서브 에이전트를 생성하여 다양한 기능을 병렬로 구현하는 것은 제 기준에서는 안티 패턴이며, 코드베이스가 쓰레기 더미로 변해도 상관없는 경우가 아니라면 제대로 작동하지 않습니다.
벤치마크
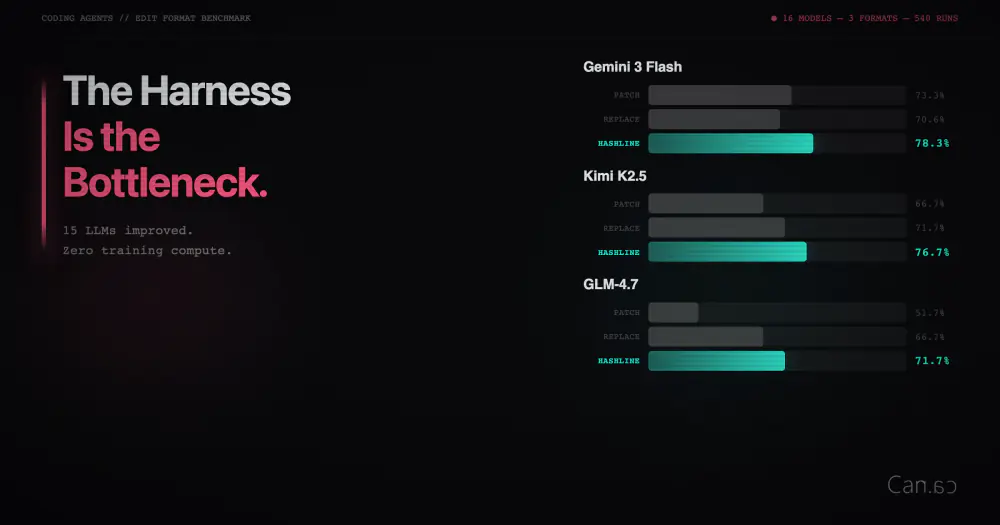
제가 거창한 주장을 많이 했지만, 위에서 말한 반골 기질 가득한 내용들이 실제로 작동한다는 수치적 증거가 있을까요? 저의 생생한 경험이 있지만, 그것은 블로그 포스트로 전달하기 어렵고 여러분은 그저 저를 믿어야 할 뿐입니다. 그래서 저는 Claude Opus 4.5를 사용하는 pi를 위해 Terminal-Bench 2.0 테스트를 만들고 Codex, Cursor, Windsurf 및 각 네이티브 모델을 사용하는 다른 코딩 하네스들과 경쟁하게 했습니다. 물론 벤치마크가 실제 성능을 대변하지 않는다는 것은 우리 모두 알고 있지만, 제가 하는 말이 전부 헛소리는 아니라는 일종의 증거로서 제공할 수 있는 최선의 방법입니다.
저는 작업당 5회씩 시도하는 전체 테스트를 수행했으며, 이는 리더보드 제출 자격이 됩니다. 또한 PST(태평양 표준시) 시간대가 온라인이 되면 오류율이 높아지고 결과적으로 벤치마크 결과가 나빠진다는 것을 발견했기 때문에, CET(중앙 유럽 표준시) 시간대에만 실행되는 두 번째 테스트도 시작했습니다. 첫 번째 테스트 결과는 다음과 같습니다.
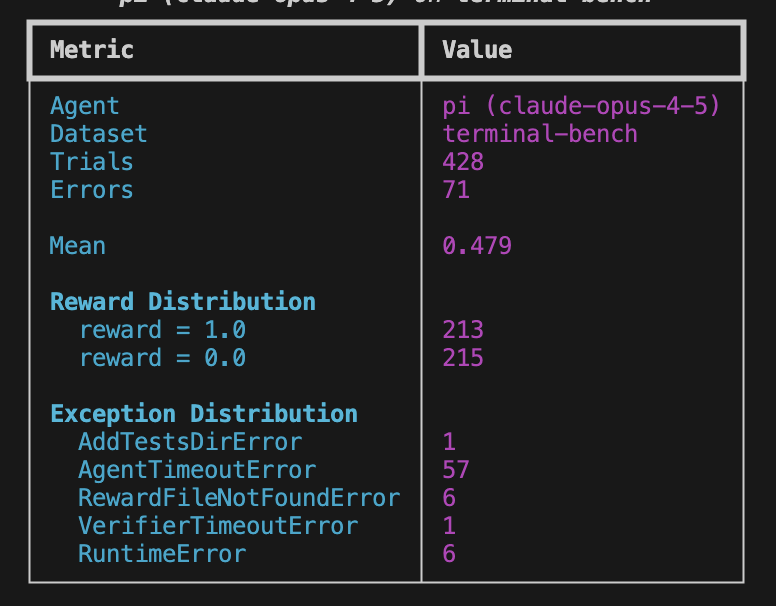
그리고 2025년 12월 2일 기준 현재 리더보드에서의 pi 순위입니다.
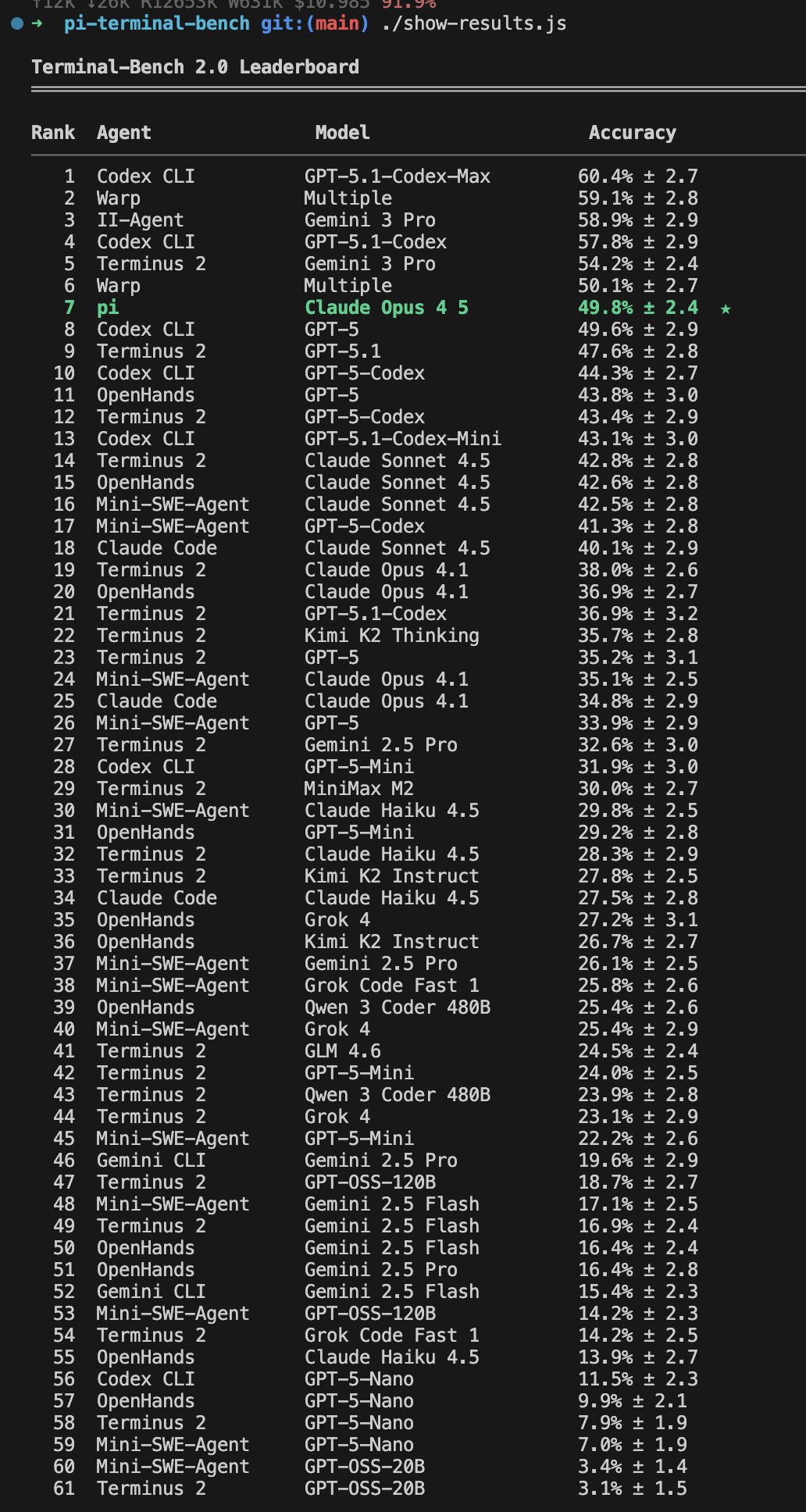
리더보드 등재를 위해 Terminal-Bench 팀에 제출한 results.json 파일입니다. 결과를 재현하고 싶다면 이 저장소에서 pi용 벤치 러너를 찾을 수 있습니다. 종량제(pay-as-you-go) 대신 Claude 플랜을 사용하시길 권장합니다.
마지막으로, CET 전용 테스트의 짧은 모습입니다.
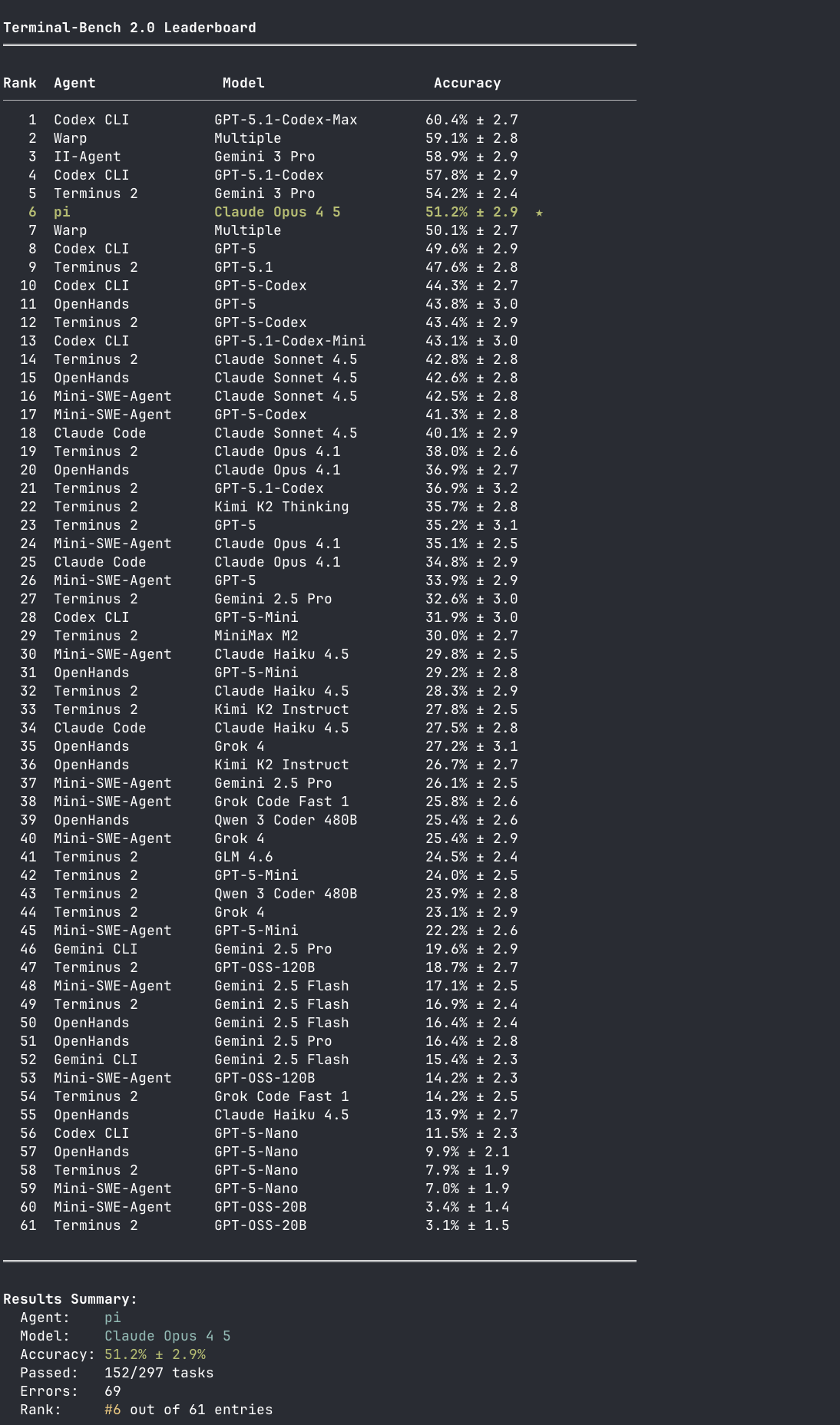
이 테스트는 완료까지 하루 정도 더 걸릴 예정입니다. 완료되면 이 포스트를 업데이트하겠습니다.
또한 리더보드에서 Terminus 2의 순위를 주목해 보세요. Terminus 2는 Terminal-Bench 팀이 만든 미니멀한 에이전트로, 모델에게 그냥 tmux 세션을 제공합니다. 모델은 명령을 텍스트로 tmux에 보내고 터미널 출력을 직접 파싱합니다. 화려한 도구도, 파일 작업도 없이 오직 원시 터미널 상호작용만 있습니다. 그런데도 훨씬 정교한 툴링을 갖춘 에이전트들 사이에서 제 몫을 다하며 다양한 모델들과 함께 작동합니다. 미니멀한 접근 방식이 충분히 잘 해낼 수 있다는 또 다른 증거입니다.
요약하며
벤치마크 결과는 즐거운 일이지만, 진짜 증거는 실제 결과물에 있습니다. 그리고 저의 결과물은 저의 일상 업무이며, 그곳에서 pi는 훌륭하게 성능을 발휘하고 있습니다. 트위터는 컨텍스트 엔지니어링 포스트와 블로그로 가득하지만, 현재 우리가 가진 하네스 중 실제로 컨텍스트 엔지니어링을 가능하게 해주는 것은 없다고 느낍니다. pi는 제가 가능한 한 많은 제어권을 가질 수 있는 도구를 스스로 만들기 위한 시도입니다.
저는 현재의 pi에 꽤 만족합니다. 압축(compaction)이나 도구 결과 스트리밍 같은 몇 가지 기능을 더 추가하고 싶지만, 개인적으로 더 필요한 것은 많지 않다고 생각합니다. 압축 기능의 부재는 저에게 큰 문제가 되지 않았습니다. 왠지 모르겠지만, 저는 Claude Code에서 압축 없이는 불가능했던 수백 번의 대화를 단일 세션에 밀어 넣을 수 있었습니다.
그렇긴 하지만, 기여는 언제나 환영합니다. 하지만 저의 다른 오픈 소스 프로젝트들과 마찬가지로, 저는 독단적인 경향이 있습니다. 수년 동안 큰 프로젝트들을 운영하며 뼈저리게 배운 교훈입니다. 만약 제가 여러분이 보낸 이슈나 PR을 닫더라도 서운해하지 않으셨으면 좋겠습니다. 최대한 그 이유를 설명해 드리려 노력하겠습니다. 저는 그저 이 프로젝트를 집중력 있고 유지보수 가능하게 유지하고 싶을 뿐입니다. 만약 pi가 여러분의 요구에 맞지 않는다면, 진심으로 포크(fork)하시길 권합니다. 그리고 만약 제 요구에 더 잘 맞는 무언가를 만드신다면, 기꺼이 여러분의 노력에 동참하겠습니다.
위의 배움 중 일부는 다른 하네스들에도 적용될 수 있다고 생각합니다. 여러분에게는 어떻게 작용하는지 알려주세요.
0
16
댓글
?
아직 댓글이 없습니다.
첫 번째 댓글을 작성해보세요!