[번역] 코드 리뷰를 끝내는 방법
I
Inkyu Oh
SW Engineering•2026.03.16
Ankit Jain - 2026-03-03
오늘 AIE Europe 스피커와 AIE World’s Fair를 위한 CFP의 두 번째 명단이 발표되었으며, 마이애미에서 OpenCode 개최가 확정되었습니다! 우리는 멜버른과 싱가포르에서도 여러분을 만날 예정입니다.
편집자 주: 이 글은 우리가 개인적으로 동의하지 않더라도 고려해 볼 가치가 있는 AI 엔지니어링 에세이를 게시하는 게스트 포스트 프로그램의 최신 기고문입니다. 최근 AI 리뷰 도구를 출시한 입장에서, 저는 아직 이 글의 주장에 완전히 도달하지는 못했지만, 이는 분명히 다가올 미래라고 생각합니다. Ankit이 펼치는 논리를 기쁘게 소개합니다!
인간이 인간의 속도로 코드를 작성하던 시절에도 이미 인간은 코드 리뷰 속도를 따라잡지 못하고 있었습니다. 제가 이야기를 나눠본 모든 엔지니어링 조직은 똑같은 공공연한 비밀을 가지고 있습니다. PR(Pull Request)은 며칠씩 방치되고, 형식적인 승인(Rubber-stamp approvals)이 남발되며, 리뷰어들은 자신의 업무가 바빠서 500줄짜리 변경 사항(diff)을 대충 훑어보고 넘깁니다.
우리는 코드 리뷰가 품질을 지키는 관문이라고 스스로를 속이지만, 사실 수십 년 동안 팀들은 한 줄 한 줄 리뷰하지 않고도 제품을 출시해 왔습니다. 한 베테랑 엔지니어는 코드 리뷰가 보편화된 것은 2012~2014년경부터였다고 말해주었습니다. 단지 우리 주변에 그 시절을 기억할 만큼 오래된 사람이 많지 않을 뿐입니다.
우리는 모든 코드를 읽는 것을 포기해야 합니다.
리뷰를 거치더라도 문제는 발생합니다. 우리는 리뷰만으로는 충분하지 않다는 사실을 받아들였기 때문에, 실패를 감당할 수 있는 시스템을 구축하는 법을 배웠습니다. 이는 기능 플래그(Feature flags), 단계적 배포(Rollouts), 즉각적인 롤백(Rollbacks)의 형태로 나타납니다.
1,255개 팀, 10,000명 이상의 개발자 데이터를 기반으로 한 Faros.ai의 자료에 따르면, AI 도입률이 높은 팀은 21% 더 많은 작업을 완료하고 98% 더 많은 PR을 병합하지만, PR 리뷰 시간은 91% 증가합니다.
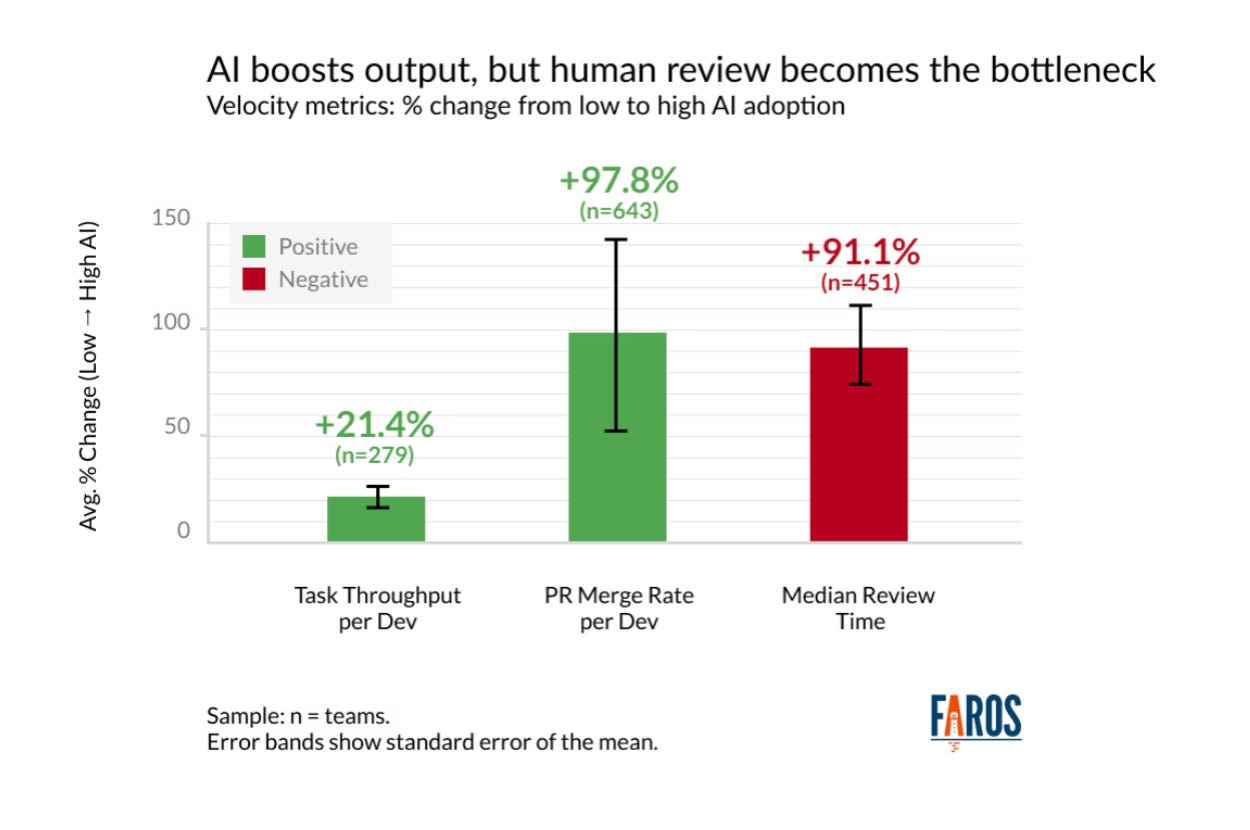
두 가지 요소가 기하급수적으로 증가하고 있습니다. 바로 변경 사항의 수와 변경 사항의 크기입니다. 우리는 이토록 많은 코드를 다 소화할 수 없습니다. 결코요. 게다가 개발자들은 AI가 생성한 코드를 리뷰하는 것이 동료가 쓴 코드를 리뷰하는 것보다 더 많은 노력이 필요하다고 계속해서 말합니다. 팀은 더 많은 코드를 생산하고, 그 코드를 리뷰하는 데 더 많은 시간을 씁니다.
수동 코드 리뷰로는 이 싸움에서 이길 방법이 없습니다. 코드 리뷰는 더 이상 현재의 작업 형태와 맞지 않는 과거의 승인 관문일 뿐입니다.
AI 코드 리뷰도 결국 리뷰입니다.
AI 코드 리뷰 도구는 단지 시간을 벌어줄 뿐입니다. AI가 코드를 쓰고 AI가 리뷰한다면, 왜 그것을 보여주기 위한 예쁜 리뷰 UI가 필요할까요? AI 코드 리뷰가 가치 있는 만큼, 이는 개발 사이클의 왼쪽(Shift left, 초기 단계)으로 이동할 것입니다. 리뷰 사이클 중간에 CI 리소스를 낭비하고 버전을 관리할 이유가 없습니다.
PR 이후의 리뷰는 인간이 코드를 작성하고 새로운 시각(Fresh eyes)이 필요했을 때나 의미가 있었습니다. 에이전트(Agent)가 코드를 작성할 때 '새로운 시각'이란 동일한 사각지대를 가진 또 다른 에이전트일 뿐입니다. 여기서 가치는 승인 관문으로서가 아니라 반복 루프(Iteration loop)에 있습니다.
우리는 경험을 통해 에이전트가 항상 신뢰할 수 있는 것은 아니라는 점을 알고 있습니다. "AI가 멍청한 짓을 하는 걸 한 번 잡았으니, 내가 항상 확인해야 해"라고 생각하는 것은 매우 인간적인 본능입니다. 수동 검증이 가능했을 때는 그 본능이 타당했습니다. 하지만 현재의 규모에서는 더 이상 불가능합니다. 그리고 상황은 더 악화될 것입니다.
코드 리뷰에서 의도 리뷰로
해답은 인간의 체크포인트를 상류(Upstream)로 옮기는 것입니다. 코드를 리뷰하지 않는다는 생각이 무섭게 느껴진다면, 소프트웨어 개발에서 체크포인트가 이전에도 이동한 적이 있다는 사실을 상기해 보십시오. 우리는 워터폴(Waterfall) 방식의 승인에서 지속적 통합(CI)으로 이동했습니다. 이번에도 옮길 수 있습니다.
스펙(Spec) 중심 개발은 AI와 함께 일하는 주요 방식이 되고 있습니다. 인간은 500줄의 코드 차이점이 아니라 스펙, 계획, 제약 조건, 그리고 수락 기준(Acceptance criteria)을 리뷰해야 합니다.
이 새로운 패러다임에서 스펙은 진실의 원천(Source of truth)이 됩니다. 코드는 스펙의 부산물이 됩니다. 코드를 리뷰할 필요가 없습니다. 단계를 리뷰하십시오. 검증 규칙(Verification rules)을 리뷰하십시오. 코드가 충족해야 하는 계약(Contract)을 리뷰하십시오.
인간 참여형(Human-in-the-loop) 승인은 "이것을 올바르게 작성했는가?"에서 "우리가 올바른 제약 조건을 가지고 올바른 문제를 해결하고 있는가?"로 이동합니다. 가장 가치 있는 인간의 판단은 첫 줄의 코드가 생성된 후가 아니라, 생성되기 전에 행사됩니다.
레이어를 통한 신뢰 구축
규칙으로 정의하자면: 코드는 인간에 의해 작성되어서는 안 된다 코드는 인간에 의해 리뷰되어서는 안 된다
LLM은 명령을 따르는 데 완벽하지 않습니다. 자주 이탈합니다. 그리고 자기 검증(Self-verification)에 있어서도 신뢰할 수 없습니다. 코드가 엉망인데도 자신 있게 작동한다고 말하곤 하죠. 해결책은 LLM에게 검증해달라고 요청하는 것이 아닙니다. 검증하는 스크립트를 작성하라고 요청하는 것입니다. 판단에서 결과물(Artifact)로 전환하십시오.
신뢰는 계층화되어 있습니다. 이것이 스위스 치즈 모델(Swiss-cheese model)입니다. 단 하나의 관문도 모든 것을 잡아낼 수는 없습니다. 구멍이 일직선으로 정렬되지 않을 때까지 불완전한 필터들을 쌓는 것입니다. 그렇다면 승인 관문을 또 어디에 둘 수 있을까요?
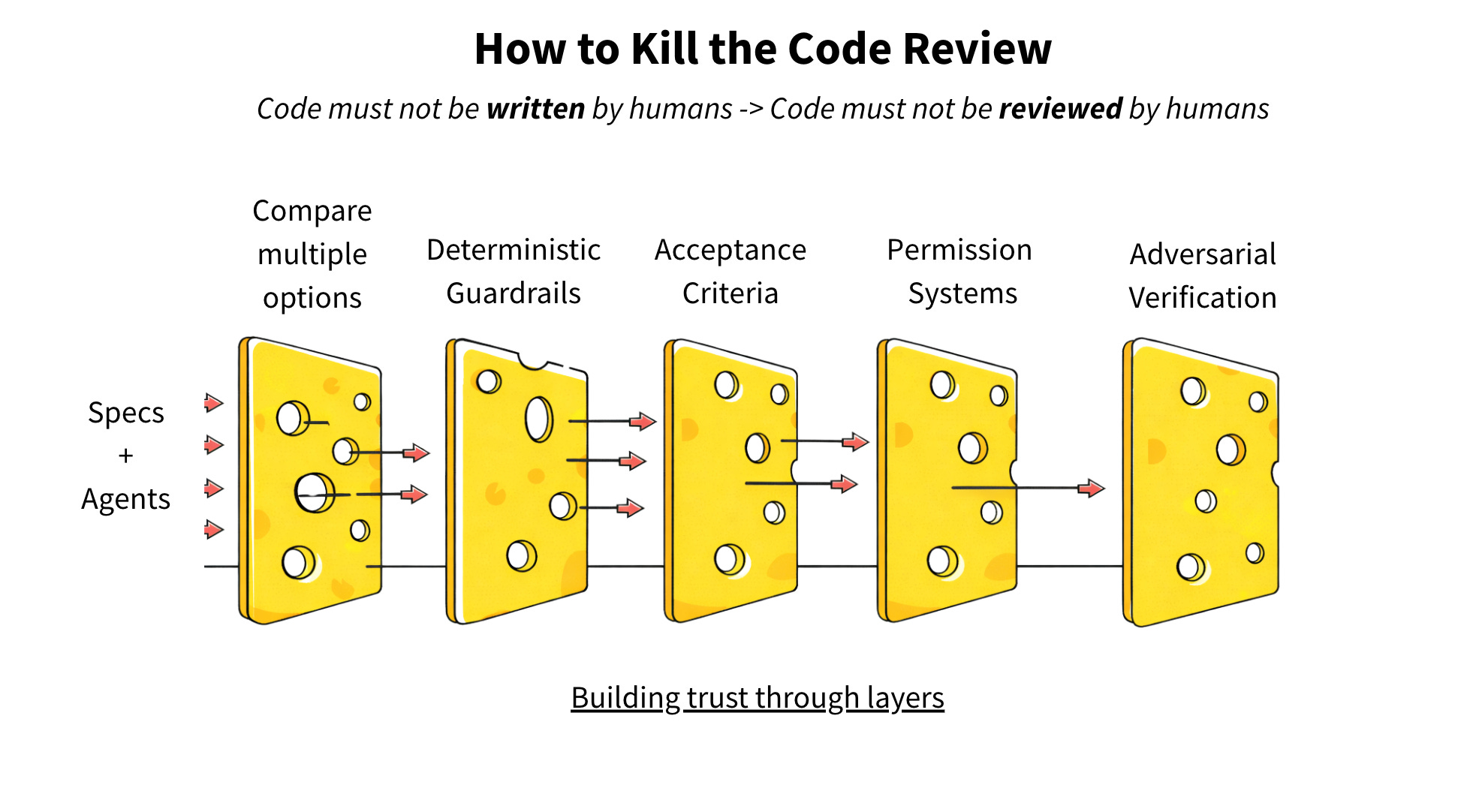
Layer 1: Compare Multiple Options
한 명의 에이전트에게 제대로 하라고 요구하는 대신, 세 명의 에이전트에게 서로 다른 방식으로 시도하게 하고 가장 좋은 결과를 선택하게 하십시오. 그들이 경쟁하게 만드십시오. 소프트웨어 엔지니어링 역사상 선택권(Optionality)을 갖는 비용이 지금처럼 낮은 적은 없었습니다.
선택 과정이 반드시 수동일 필요는 없습니다. 어떤 결과물이 가장 많은 검증 단계를 통과하는지, 어떤 것이 가장 작은 코드 차이를 만드는지, 어떤 것이 새로운 의존성을 추가하지 않는지에 따라 순위를 매길 수 있습니다. 경쟁은 단 한 번의 시도에서는 얻을 수 없는 신호를 만들어냅니다.
Layer 2: Deterministic Guardrails
작업을 검증하는 결정론적(Deterministic)인 방법이 있어야 합니다. 테스트, 타입 체크, 계약 검증(Contract verification) 등 의견이 아닌 사실만을 다루는 것들입니다.
LLM에게 "이게 작동하나요?"라고 묻는 대신, 일련의 통과/실패 결과물을 생성하는 검증 단계를 정의하십시오. 에이전트는 실패한 테스트와 협상할 수 없습니다. 스펙을 충족하거나, 충족하지 못하거나 둘 중 하나입니다.
이러한 가드레일(Guardrails)은 그 자체로 계층으로 정의될 수 있습니다.
- 코딩 가이드라인 - 커스텀 린터(Linter)로 구현 가능
- 조직 전체의 불변성(Invariants) - 타협 불가능한 사항들 (예: 하드코딩된 자격 증명, API 키 또는 토큰 금지)
- 도메인 계약(Domain Contracts) - 특정 프레임워크, 서비스 또는 코드베이스의 일부에 특화된 규칙 (예: 결제 도메인: 모든 금액은 Money 타입을 사용해야 함)
- 수락 기준(Acceptance Criteria) - 해당 작업에 특화된 기준
검증 단계는 코드가 작성된 후에 이미 있는 것을 확인하기 위해 급조되는 것이 아니라, 코드가 작성되기 전에 정의되어야 합니다. 에이전트가 코드와 테스트를 모두 작성한다면, 문제는 해결되지 않고 옮겨진 것뿐입니다. 이제 에이전트가 올바른 것을 테스트하는지 신뢰해야 하는 상황이 되기 때문입니다. 검증 기준은 구현이 아니라 스펙에서 나와야 합니다.
Layer 3: Humans define acceptance criteria
그렇다면 인간은 어디에서 가치를 더할까요? 상류에서 무엇이 성공인지를 정의하는 단계입니다.
이 지점에서 행동 주도 개발(BDD, Behavior-Driven Development)이 새롭게 중요해집니다. BDD는 항상 좋은 아이디어였습니다. 예상되는 동작을 자연어로 스펙을 작성하고, 그 스펙을 테스트로 자동화하는 것이죠. 하지만 코드를 직접 짤 때 스펙까지 쓰는 것이 추가 업무처럼 느껴졌기 때문에 완전히 정착되지는 못했습니다.
에이전트와 함께라면 이 방정식이 뒤집힙니다. 스펙은 추가 업무가 아니라 핵심 결과물입니다. 당신은 이렇게 작성합니다:
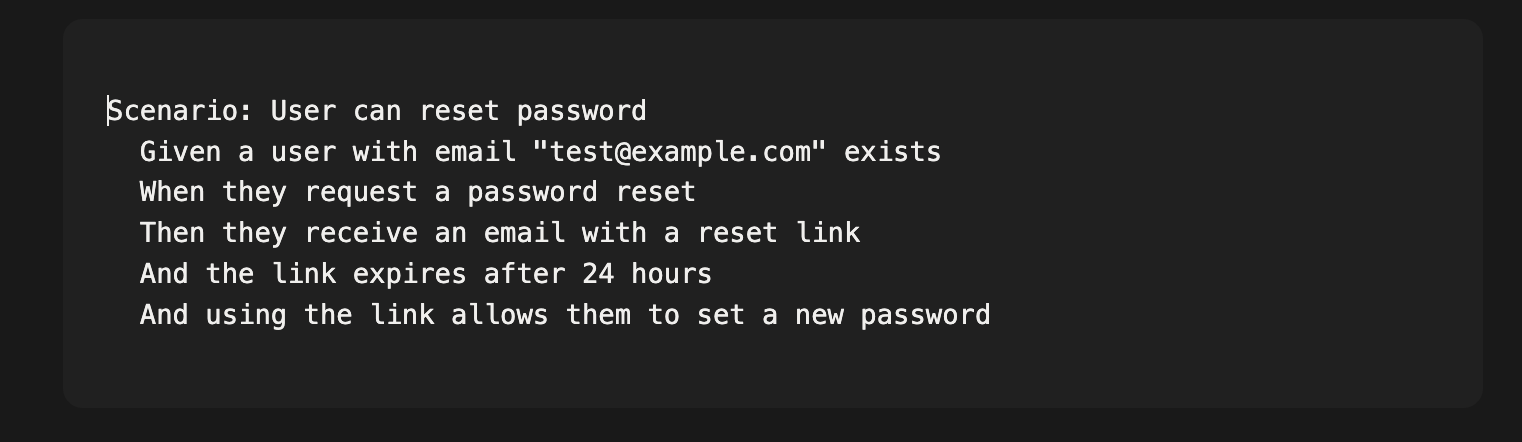
에이전트가 구현합니다. BDD 프레임워크가 검증합니다. 무언가 실패하지 않는 한 당신은 구현 코드를 읽을 필요가 없습니다.
이것이 바로 인간이 잘하는 일입니다. "올바름"이 무엇인지 정의하고, 비즈니스 로직과 예외 상황(Edge cases)을 인코딩하며, 무엇이 잘못될 수 있는지 생각하는 것입니다. 에이전트는 의도를 코드로 번역하는 일을 처리합니다. BDD 스펙은 당신의 검증 계층이 됩니다. 이는 결정론적이고 자동화되어 있으며, 첫 줄의 코드가 쓰이기 전에 정의됩니다.
Layer 4: Permission Systems as Architecture
이 에이전트가 무엇을 건드릴 수 있는가? 무엇이 에스컬레이션(Escalation, 상위 보고)을 필요로 하는가? 이는 사후 고려 사항이 아니라 아키텍처적인 결정이 됩니다.
대부분의 에이전트 프레임워크는 권한을 '전부 아니면 전무(All-or-nothing)'로 취급합니다. 에이전트가 셸(Shell) 접근 권한을 갖거나 갖지 않거나 둘 중 하나죠. 하지만 세분화(Granularity)가 중요합니다. 유틸리티 함수의 버그를 수정하는 에이전트는 인프라 설정에 접근할 필요가 없습니다. 테스트를 작성하는 에이전트는 CI 파이프라인을 수정할 필요가 없습니다.
범위(Scope)는 에이전트가 유용한 작업을 수행할 수 있는 한 최대한 좁게 유지되어야 합니다. 작업이 "utils/dates.py의 날짜 파싱 버그 수정"이라면, 에이전트의 파일 시스템 접근은 해당 파일과 그 테스트 파일로 제한되어야 합니다. 전체 코드베이스가 아니라, "src/ 및 tests/"도 아니라, 오직 이 작업에 중요한 파일들만 말이죠.
에스컬레이션 트리거도 똑같이 중요합니다. 인증 로직을 건드리거나, 데이터베이스 스키마를 수정하거나, 새로운 의존성을 추가하는 등의 특정 패턴은 에이전트의 확신과 관계없이 자동으로 인간의 리뷰를 받도록 플래그를 세워야 합니다.
Layer 5: Adversarial Verification
책임의 분리: 한 에이전트가 작업을 수행하고, 다른 에이전트가 검증합니다. 그들은 서로를 믿지 않으며, 그것이 핵심입니다.
이는 오래된 패턴입니다. QA 팀이 엔지니어링 매니저에게 보고해서는 안 되는 이유이자, 코드를 쓴 사람이 리뷰까지 해서는 안 되는 이유와 같습니다.
에이전트를 사용하면 이를 아키텍처적으로 강제할 수 있습니다. 코딩 에이전트는 검증 에이전트가 무엇을 확인할지 알지 못합니다. 검증 에이전트는 자신의 일을 편하게 하기 위해 코드를 수정할 능력이 없습니다. 그들은 설계상 적대적(Adversarial)입니다.
여기서 더 나아갈 수도 있습니다. 세 번째 에이전트가 첫 번째 에이전트가 만든 것을 망가뜨리려 시도하며, 특히 예외 상황과 실패 모드를 공략하는 것입니다. 레드 팀(Red team)과 블루 팀(Blue team)의 구성을 자동화하여 모든 변경 사항마다 실행하는 것이죠.
결론: "좋은 코드"의 기준이 변하고 있습니다
에이전트 시스템의 동기는 단순합니다. "주어진 작업을 완료할 수 있는가? 나에게 일을 준 사람을 기쁘게 할 수 있는가?" 에이전트의 성공은 본질적으로 장기적인 정확성이나 비즈니스 요구 사항에 의해 주도되지 않습니다.
제약 조건 안에 이를 인코딩하는 것이 우리의 몫입니다.
에이전트가 생성하고 에이전트가 읽는 코드의 경우, "좋은 코드"의 모습은 더욱 표준화될 것입니다. 새로운 코드베이스의 경우, 기본 설정이 더 일관되게 유지될 것이므로 지시를 덜 내려도 될 것입니다.
미래는 빠르게 출시하고, 모든 것을 관찰하며, 더 빠르게 되돌리는 것입니다.
느리게 리뷰하고, 어차피 버그를 놓치며, 운영 환경에서 디버깅하는 것이 아닙니다.
우리는 기계보다 더 많이 읽을 수 없습니다. 우리는 결정이 실제로 중요한 상류에서 기계보다 더 깊이 생각해야 합니다.
궁극적으로, 에이전트가 코드를 잘 처리할 수 있다면, 우리가 그 코드를 읽을 수 있는지 없는지가 무슨 상관이겠습니까?
Ankit Jain은 AI 네이티브 엔지니어링 팀을 위한 인프라를 구축하는 Aviator의 설립자이자 CEO입니다. Aviator의 플랫폼은 현대적인 조직이 높은 엔지니어링 표준을 유지하면서 AI 도입을 개선할 수 있도록 돕습니다.
0
3
댓글
?
아직 댓글이 없습니다.
첫 번째 댓글을 작성해보세요!
Inkyu Oh님의 다른 글
더보기
번역
TypeScript 6.0 RC 발표
Inkyu Oh • 라이브러리, 프레임워크
0
0
5
번역
Requests 라이브러리가 결혼에 대해 가르쳐준 것들
Inkyu Oh • Career
0
0
6



