[번역] useEffect 완벽 가이드
Dan Abramov - 2019년 3월 9일
여러분은 Hooks를 사용하여 몇 개의 컴포넌트를 작성해 보았을 것입니다. 어쩌면 작은 앱 하나를 만들었을지도 모릅니다. 대체로 만족스러울 것이고, API에도 익숙해졌으며 그 과정에서 몇 가지 요령도 익혔을 것입니다. 심지어 반복되는 로직을 추출하기 위해 커스텀 Hooks를 만들어(300줄의 코드가 사라졌네요!) 동료들에게 자랑하기도 했을 것입니다. 동료들은 "잘했어"라고 말해주었겠죠.
하지만 가끔
useEffect를 사용할 때 조각들이 잘 맞지 않는 느낌을 받을 때가 있습니다. 무언가 놓치고 있다는 찜찜한 기분이 들기도 하죠. 클래스의 생명주기(Lifecycle)와 비슷해 보이는데... 정말 그럴까요? 여러분은 스스로에게 다음과 같은 질문을 던지게 될 것입니다.- 🤔
useEffect로componentDidMount를 어떻게 복제하나요?
- 🤔
useEffect안에서 데이터를 올바르게 가져오는(fetch) 방법은 무엇인가요?[]는 무엇을 의미하나요?
- 🤔 이펙트(Effect)의 의존성(Dependencies) 배열에 함수를 지정해야 하나요, 말아야 하나요?
- 🤔 왜 가끔 데이터 페칭 무한 루프에 빠지나요?
- 🤔 왜 가끔 이펙트 안에서 오래된(stale) props나 state 값을 보게 되나요?
제가 처음 Hooks를 사용하기 시작했을 때도 이런 질문들 때문에 혼란스러웠습니다. 초기 문서를 작성할 때조차 몇 가지 미묘한 부분들을 확실히 파악하지 못했었죠. 그 이후로 제가 경험한 몇 가지 "아하!" 모먼트들을 여러분과 공유하고자 합니다. 이 심층 분석을 통해 위 질문들에 대한 답이 여러분에게 명확해질 것입니다.
답을 보기 위해서는 한 걸음 뒤로 물러나야 합니다. 이 글의 목표는 요리법 같은 체크리스트를 제공하는 것이 아닙니다. 여러분이
useEffect를 진정으로 "이해(grok)"하도록 돕는 것입니다. 배울 것은 많지 않습니다. 사실, 우리는 대부분의 시간을 기존의 지식을 버리는(unlearning) 데 보낼 것입니다.익숙한 클래스 생명주기 메서드라는 프리즘을 통해
useEffect Hook을 바라보는 것을 멈추고 나서야 모든 것이 하나로 합쳐졌습니다."배운 것을 잊어라(Unlearn what you have learned)." — 요다

또한 이 글은 정말 깁니다. 미니북과 같죠. 제가 선호하는 형식이기도 합니다. 하지만 바쁘거나 관심이 없는 분들을 위해 바로 아래에 요약(TLDR)을 작성해 두었습니다.
심층적인 설명을 읽는 것이 부담스럽다면, 이러한 설명들이 다른 곳에 나타날 때까지 기다리셔도 좋습니다. 2013년 React가 처음 나왔을 때처럼, 사람들이 다른 멘탈 모델(Mental model)을 인식하고 가르치는 데는 시간이 좀 걸릴 것입니다.
요약 (TLDR)
전체 내용을 읽고 싶지 않은 분들을 위한 빠른 요약입니다. 이해가 되지 않는 부분이 있다면 관련 내용을 찾아 아래로 스크롤해 보세요.
전체 글을 읽을 계획이라면 이 부분을 건너뛰셔도 좋습니다. 마지막에 다시 링크를 걸어두겠습니다.
🤔 질문:
useEffect로 componentDidMount를 어떻게 복제하나요?useEffect(fn, [])를 사용할 수 있지만, 이것이 정확한 동등물은 아닙니다. componentDidMount와 달리, 이는 props와 state를 *캡처(Capture)*합니다. 따라서 콜백 안에서도 초기 props와 state를 보게 됩니다. 만약 "최신" 값을 보고 싶다면 ref에 기록하면 됩니다. 하지만 보통은 그렇게 하지 않아도 되도록 코드를 구조화하는 더 간단한 방법이 있습니다. 이펙트의 멘탈 모델은 componentDidMount나 다른 생명주기와 다르며, 정확한 동등물을 찾으려 하는 것이 도움보다는 혼란을 줄 수 있다는 점을 명심하세요. 생산성을 높이려면 "이펙트 방식으로 생각"해야 하며, 그 멘탈 모델은 생명주기 이벤트에 응답하는 것보다 동기화(Synchronization)를 구현하는 것에 더 가깝습니다.🤔 질문:
useEffect 안에서 데이터를 올바르게 가져오는 방법은 무엇인가요? []는 무엇을 의미하나요?이 글은
useEffect를 사용한 데이터 페칭에 대한 좋은 입문서입니다. 끝까지 읽어보세요! 이 글만큼 길지는 않습니다. []는 이펙트가 React 데이터 흐름에 참여하는 어떤 값도 사용하지 않음을 의미하며, 따라서 한 번만 적용해도 안전하다는 뜻입니다. 하지만 실제로 값이 사용되고 있는데도 이를 생략하면 버그의 흔한 원인이 됩니다. 의존성을 잘못 생략하는 대신, 의존성의 필요성을 제거할 수 있는 몇 가지 전략(useReducer와 useCallback이 주된 방법입니다)을 배워야 합니다.🤔 질문: 이펙트 의존성에 함수를 지정해야 하나요, 말아야 하나요?
권장 사항은 props나 state가 필요 없는 함수는 컴포넌트 외부로 끌어올리고(hoist), 이펙트 안에서만 사용되는 함수는 이펙트 내부로 넣는 것입니다. 그 후에도 이펙트가 렌더링 범위 내의 함수(props에서 전달받은 함수 포함)를 사용한다면, 해당 함수가 정의된 곳에서
useCallback으로 감싸고 과정을 반복하세요. 왜 이것이 중요할까요? 함수는 props와 state의 값을 "볼" 수 있으므로 데이터 흐름에 참여하기 때문입니다. FAQ에 더 자세한 답변이 있습니다.🤔 질문: 왜 가끔 데이터 페칭 무한 루프에 빠지나요?
이펙트의 두 번째 인자인 의존성 배열 없이 데이터 페칭을 할 때 발생할 수 있습니다. 의존성이 없으면 이펙트는 매 렌더링 후에 실행되며, state를 설정하면 다시 렌더링이 발생하여 이펙트가 또 실행됩니다. 의존성 배열에 항상 바뀌는 값을 지정했을 때도 무한 루프가 발생할 수 있습니다. 하나씩 제거해 보며 어떤 값인지 확인할 수 있습니다. 하지만 사용 중인 의존성을 제거하거나(또는 맹목적으로
[]를 지정하는 것)은 대개 잘못된 해결책입니다. 대신 문제의 근본 원인을 해결하세요. 예를 들어, 함수가 이 문제를 일으킬 수 있는데, 함수를 이펙트 내부로 옮기거나, 외부로 끌어올리거나, useCallback으로 감싸는 것이 도움이 됩니다. 객체 재생성을 피하기 위해 useMemo도 비슷한 목적으로 사용될 수 있습니다.🤔 질문: 왜 가끔 이펙트 안에서 오래된 state나 prop 값을 보게 되나요?
이펙트는 항상 자신이 정의된 렌더링 시점의 props와 state를 "봅니다". 이는 버그를 예방하는 데 도움이 되지만, 어떤 경우에는 성가실 수 있습니다. 그런 경우 가변적인(mutable) ref에 값을 명시적으로 유지할 수 있습니다(링크된 글의 마지막 부분에 설명되어 있습니다). 만약 예상치 못하게 이전 렌더링의 props나 state를 보고 있다면, 의존성을 빠뜨렸을 가능성이 큽니다. 린트(Lint) 규칙을 사용하여 이를 찾아내는 연습을 해보세요. 며칠만 지나면 제2의 천성처럼 익숙해질 것입니다. FAQ의 이 답변도 참고하세요.
이 요약이 도움이 되었기를 바랍니다! 이제 본격적으로 시작해 보죠.
모든 렌더링은 고유한 Props와 State를 가집니다
이펙트에 대해 이야기하기 전에, 렌더링에 대해 먼저 이야기해야 합니다.
여기 카운터가 있습니다. 강조된 줄을 자세히 보세요.
이것은 무엇을 의미할까요?
count가 우리 state의 변화를 어떻게든 "감시"하고 자동으로 업데이트되는 것일까요? React를 처음 배울 때는 그렇게 직관적으로 이해하는 것이 유용할 수 있지만, 그것은 정확한 멘탈 모델이 아닙니다.이 예시에서
count는 그저 숫자일 뿐입니다. 마법 같은 "데이터 바인딩", "와처(Watcher)", "프록시(Proxy)" 같은 것이 아닙니다. 다음과 같은 평범한 숫자와 같습니다.컴포넌트가 처음 렌더링될 때,
useState()로부터 얻은 count 변수는 0입니다. setCount(1)을 호출하면 React는 컴포넌트를 다시 호출합니다. 이때 count는 1이 됩니다. 이런 식으로 계속됩니다.**우리가 state를 업데이트할 때마다 React는 컴포넌트를 호출합니다. 각 렌더링 결과는 함수 내부에서 상수(Constant)인 고유한
count state 값을 "봅니다".따라서 이 줄은 특별한 데이터 바인딩을 수행하지 않습니다.
그저 렌더링 출력물에 숫자 값을 삽입할 뿐입니다. 그 숫자는 React가 제공합니다. 우리가
setCount를 호출하면 React는 다른 count 값으로 컴포넌트를 다시 호출합니다. 그런 다음 React는 최신 렌더링 출력물에 맞춰 DOM을 업데이트합니다.핵심은 특정 렌더링 내부의
count 상수는 시간이 지나도 변하지 않는다는 것입니다. 다시 호출되는 것은 컴포넌트이며, 각 렌더링은 렌더링 간에 격리된 고유한 count 값을 "봅니다".모든 렌더링은 고유한 이벤트 핸들러를 가집니다
여기까지는 좋습니다. 이벤트 핸들러는 어떨까요?
이 예시를 보세요. 3초 후에
count를 알림창(alert)으로 보여줍니다.제가 다음과 같은 순서로 조작한다고 가정해 봅시다.
- 카운터를 3까지 증가시킵니다.
- "Show alert"를 누릅니다.
- 타임아웃이 실행되기 전에 카운터를 5까지 증가시킵니다.
알림창에 어떤 숫자가 표시될 것으로 예상하시나요? 알림이 뜨는 시점의 카운터 상태인 5일까요? 아니면 제가 클릭했을 때의 상태인 3일까요?
스포일러 주의
직접 시도해 보세요!
이 동작이 잘 이해되지 않는다면, 더 실용적인 예시를 상상해 보세요. 현재 수신자 ID가 state에 있고 "보내기" 버튼이 있는 채팅 앱입니다. 이 글에서 그 이유를 심층적으로 탐구하지만, 정답은 3입니다.
알림창은 제가 버튼을 클릭한 시점의 state를 "캡처"합니다.
(다른 동작을 구현하는 방법도 있지만, 지금은 기본 케이스에 집중하겠습니다. 멘탈 모델을 구축할 때는 "최소 저항 경로"와 선택적인 탈출구(escape hatch)를 구분하는 것이 중요합니다.)
그런데 어떻게 이렇게 작동하는 걸까요?
우리는
count 값이 특정 함수 호출 내에서 일정하다는 것을 논의했습니다. 이를 강조할 가치가 있습니다. 우리 함수는 여러 번 호출되지만(렌더링당 한 번), 그 매번의 호출 내부에서 count 값은 상수이며 특정 값(해당 렌더링의 state)으로 설정되어 있습니다.이것은 React에 국한된 것이 아닙니다. 일반 함수도 비슷하게 작동합니다.
이 예시에서 외부의
someone 변수는 여러 번 재할당됩니다. (React 어딘가에서 현재 컴포넌트 state가 변할 수 있는 것과 같습니다.) 하지만 sayHi 내부에는 특정 호출의 person과 연결된 지역 상수 name이 있습니다. 그 상수는 지역적(local)이므로 호출 간에 격리되어 있습니다! 결과적으로 타임아웃이 실행될 때 각 알림창은 자신만의 name을 "기억"합니다.이것이 우리 이벤트 핸들러가 클릭 시점의
count를 캡처하는 이유를 설명해 줍니다. 동일한 치환 원리를 적용하면, 각 렌더링은 고유한 count를 "봅니다".따라서 실질적으로 각 렌더링은 고유한 "버전"의
handleAlertClick을 반환합니다. 각 버전은 고유한 count를 "기억"합니다.특정 렌더링 내부에서 props와 state는 영원히 동일하게 유지됩니다. 하지만 props와 state가 렌더링 간에 격리되어 있다면, 그것들을 사용하는 모든 값(이벤트 핸들러 포함)도 마찬가지입니다. 그것들 역시 특정 렌더링에 "속합니다". 따라서 이벤트 핸들러 내부의 비동기 함수조차 동일한
count 값을 "보게" 됩니다.참고: 위에서
handleAlertClick 함수 안에 구체적인 count 값을 직접 대입했습니다. 이러한 정신적 치환은 안전합니다. 왜냐하면 count는 특정 렌더링 내에서 절대 변할 수 없기 때문입니다. const로 선언되었고 숫자입니다. 객체와 같은 다른 값에 대해서도 동일하게 생각하는 것이 안전하지만, 이는 우리가 state를 변이(mutate)하지 않기로 동의했을 때만 해당합니다. 기존 객체를 변이하는 대신 새로 생성된 객체로 setSomething(newObj)를 호출하는 것은 이전 렌더링에 속한 state가 그대로 유지되므로 괜찮습니다.모든 렌더링은 고유한 이펙트를 가집니다
이 글은 이펙트에 관한 글이어야 하는데 아직 이펙트에 대해 이야기하지 않았네요! 이제 바로잡겠습니다. 알고 보니 이펙트도 크게 다르지 않습니다.
문서의 예시로 돌아가 봅시다.
질문 하나 드릴게요. 이펙트는 어떻게 최신
count state를 읽을까요?혹시 이펙트 함수 내부에서
count가 실시간으로 업데이트되도록 하는 어떤 종류의 "데이터 바인딩"이나 "감시"가 있는 걸까요? 아니면 count가 React가 컴포넌트 내부에 설정하는 가변 변수라서 이펙트가 항상 최신 값을 보게 되는 걸까요?아닙니다.
우리는 이미
count가 특정 컴포넌트 렌더링 내에서 상수라는 것을 알고 있습니다. 이벤트 핸들러는 count가 자신의 스코프 내에 있는 변수이기 때문에 자신이 "속한" 렌더링의 count state를 "봅니다". 이펙트도 마찬가지입니다!"변하지 않는" 이펙트 내부에서
count 변수가 어떻게든 변하는 것이 아닙니다. 매 렌더링마다 이펙트 함수 자체가 달라지는 것입니다.각 버전은 자신이 "속한" 렌더링의
count 값을 "봅니다".React는 여러분이 제공한 이펙트 함수를 기억해 두었다가, DOM에 변경 사항을 반영하고 브라우저가 화면을 그린 후에 실행합니다.
따라서 여기서 개념적으로는 하나의 이펙트(문서 제목 업데이트)를 말하고 있지만, 이는 매 렌더링마다 다른 함수로 표현됩니다. 그리고 각 이펙트 함수는 자신이 "속한" 특정 렌더링의 props와 state를 "봅니다".
개념적으로 이펙트는 렌더링 결과의 일부라고 생각할 수 있습니다.
엄밀히 말하면 그렇지 않습니다(어색한 문법이나 런타임 오버헤드 없이 Hook 합성을 허용하기 위해). 하지만 우리가 구축하고 있는 멘탈 모델에서 이펙트 함수는 이벤트 핸들러와 마찬가지로 특정 렌더링에 속합니다.
확실한 이해를 위해 첫 번째 렌더링을 요약해 봅시다.
- React: state가
0일 때의 UI를 줘.
- 당신의 컴포넌트:
- 여기 렌더링 결과야:
<p>You clicked 0 times</p>.
- 그리고 다 끝나면 이 이펙트를 실행하는 걸 잊지 마:
() => { document.title = 'You clicked 0 times' }.
- React: 알았어. UI를 업데이트할게. 브라우저야, DOM에 몇 가지를 추가할 거야.
- 브라우저: 좋아, 화면에 그렸어.
- React: 좋아, 이제 네가 준 이펙트를 실행할게.
() => { document.title = 'You clicked 0 times' }실행 중.
이제 클릭 후 어떤 일이 일어나는지 요약해 봅시다.
- 당신의 컴포넌트: React야, 내 state를
1로 설정해 줘.
- React: state가
1일 때의 UI를 줘.
- 당신의 컴포넌트:
- 여기 렌더링 결과야:
<p>You clicked 1 times</p>.
- 그리고 다 끝나면 이 이펙트를 실행하는 걸 잊지 마:
() => { document.title = 'You clicked 1 times' }.
- React: 알았어. UI를 업데이트할게. 브라우저야, DOM을 변경했어.
- 브라우저: 좋아, 변경 사항을 화면에 그렸어.
- React: 좋아, 이제 방금 한 렌더링에 속한 이펙트를 실행할게.
() => { document.title = 'You clicked 1 times' }실행 중.
모든 렌더링은 고유한... 모든 것을 가집니다
우리는 이제 이펙트가 매 렌더링 후에 실행되고, 개념적으로 컴포넌트 출력의 일부이며, 해당 특정 렌더링의 props와 state를 "본다"는 것을 알게 되었습니다.
사고 실험을 하나 해봅시다. 이 코드를 고려해 보세요.
짧은 간격으로 여러 번 클릭하면 로그가 어떻게 찍힐까요?
스포일러 주의
이것이 함정이고 결과가 직관적이지 않다고 생각할 수도 있습니다. 그렇지 않습니다! 우리는 로그의 시퀀스를 보게 될 것입니다. 각 로그는 특정 렌더링에 속하며 따라서 고유한
count 값을 가집니다. 직접 시도해 보세요.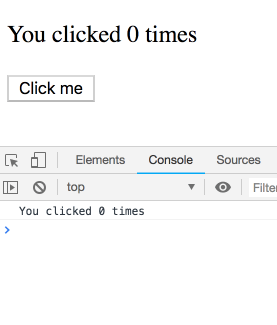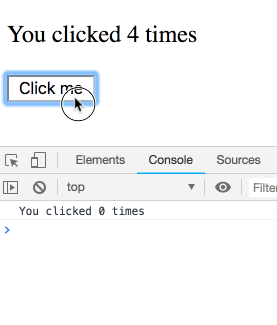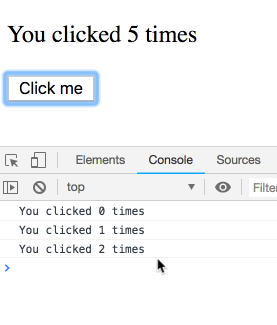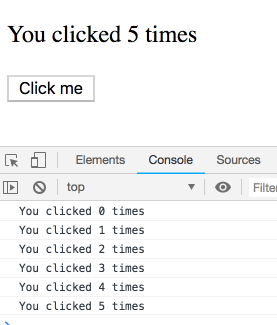
여러분은 "당연히 그렇게 작동해야지! 다르게 작동할 리가 있나?"라고 생각할 수도 있습니다.
하지만
this.state.count는 특정 렌더링에 속한 값이 아니라 항상 최신 카운트를 가리킵니다. 따라서 매번 5가 기록되는 것을 보게 될 것입니다.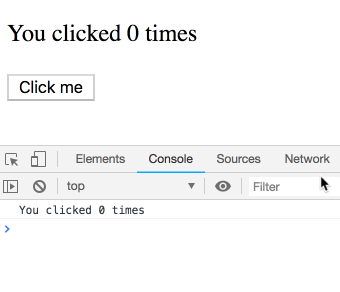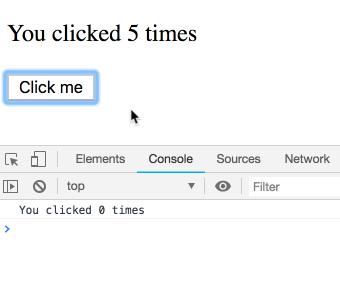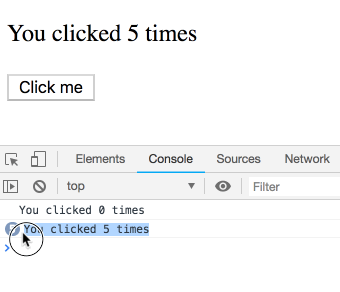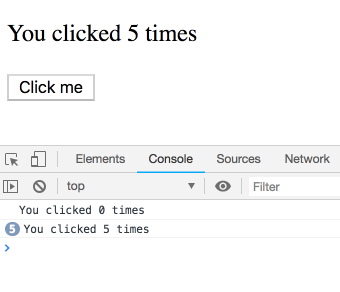
Hooks가 자바스크립트 클로저(Closure)에 크게 의존함에도 불구하고, 클로저와 흔히 연관되는 전형적인 타임아웃 내 잘못된 값 문제로 고통받는 것은 클래스 구현이라는 점이 아이러니합니다. 이는 이 예시에서 혼란의 실제 원인이 클로저 자체가 아니라 변이(Mutation)이기 때문입니다(React는 클래스에서 최신 state를 가리키도록
this.state를 변이시킵니다).클로저는 닫혀 있는(close over) 값이 절대 변하지 않을 때 훌륭합니다. 기본적으로 상수를 참조하기 때문에 생각하기 쉽습니다. 그리고 우리가 논의했듯이, props와 state는 특정 렌더링 내에서 절대 변하지 않습니다. 참고로, 클래스 버전도 클로저를 사용하면 고칠 수 있습니다.
흐름을 거스르기
이 시점에서 명시적으로 짚고 넘어가는 것이 중요합니다. 컴포넌트 렌더링 내부의 모든 함수(이벤트 핸들러, 이펙트, 타임아웃 또는 그 내부의 API 호출 포함)는 해당 함수를 정의한 렌더링 호출의 props와 state를 캡처합니다.
따라서 다음 두 예시는 동일합니다.
컴포넌트 내부에서 props나 state를 "일찍" 읽는지는 중요하지 않습니다. 그것들은 변하지 않을 테니까요! 단일 렌더링의 스코프 내에서 props와 state는 동일하게 유지됩니다. (props를 구조 분해 할당하면 이 점이 더 명확해집니다.)
물론, 이펙트에 정의된 어떤 콜백 내부에서 캡처된 값이 아닌 최신 값을 읽고 싶을 때가 있습니다. 가장 쉬운 방법은 이 글의 마지막 섹션에 설명된 대로 ref를 사용하는 것입니다.
과거 렌더링의 함수에서 미래의 props나 state를 읽으려 할 때, 여러분은 흐름을 거스르고 있다는 점을 인지하세요. 그것이 틀린 것은 아니며(어떤 경우에는 필요합니다), 패러다임을 벗어나는 것이기 때문에 코드가 덜 "깔끔해" 보일 수 있습니다. 이는 어떤 코드가 취약하고 타이밍에 의존하는지 강조하는 데 도움이 되기 때문에 의도된 결과입니다. 클래스에서는 이런 일이 일어날 때 덜 명확합니다.
React에서 무언가를 변이시키는 것이 기이해 보일 수 있습니다. 하지만 이것이 바로 React 자체가 클래스에서
this.state를 재할당하는 방식입니다. 캡처된 props 및 state와 달리, latestCount.current를 읽는 것이 특정 콜백에서 동일한 값을 줄 것이라는 보장은 없습니다. 정의상 언제든지 변이할 수 있기 때문입니다. 이것이 기본값이 아닌 이유이며, 여러분이 명시적으로 선택해야 하는 이유입니다.그렇다면 클린업(Cleanup)은 어떨까요?
문서에서 설명하듯이, 일부 이펙트는 클린업 단계가 있을 수 있습니다. 본질적으로 그 목적은 구독(Subscription)과 같은 경우에 이펙트를 "취소"하는 것입니다.
이 코드를 고려해 보세요.
첫 번째 렌더링에서
props가 {id: 10}이고, 두 번째 렌더링에서 {id: 20}이라고 가정해 봅시다. 여러분은 다음과 같은 일이 일어난다고 생각할 수 있습니다.- React가
{id: 10}에 대한 이펙트를 클린업합니다.
- React가
{id: 20}에 대한 UI를 렌더링합니다.
- React가
{id: 20}에 대한 이펙트를 실행합니다.
(실제로는 그렇지 않습니다.)
이 멘탈 모델로는 클린업이 재렌더링 전에 실행되기 때문에 이전 props를 "보고", 새로운 이펙트는 재렌더링 후에 실행되기 때문에 새로운 props를 "본다"고 생각할 수 있습니다. 이는 클래스 생명주기에서 그대로 가져온 멘탈 모델이며, 여기서는 정확하지 않습니다. 이유를 알아봅시다.
React는 브라우저가 화면을 그리게 한 후에만 이펙트를 실행합니다. 대부분의 이펙트가 화면 업데이트를 차단할 필요가 없으므로 이는 앱을 더 빠르게 만듭니다. 이펙트 클린업 또한 지연됩니다. 이전 이펙트는 새로운 props로 재렌더링된 후에 클린업됩니다.
- React가
{id: 20}에 대한 UI를 렌더링합니다.
- 브라우저가 화면을 그립니다. 화면에
{id: 20}에 대한 UI가 보입니다.
- React가
{id: 10}에 대한 이펙트를 클린업합니다.
- React가
{id: 20}에 대한 이펙트를 실행합니다.
여러분은 의아할 수 있습니다. 이전 이펙트의 클린업이 props가
{id: 20}으로 바뀐 후에 실행되는데, 어떻게 여전히 이전의 {id: 10} props를 "볼" 수 있는 걸까요?우리는 이미 이 답을 알고 있습니다... 🤔

이전 섹션의 인용구입니다.
컴포넌트 렌더링 내부의 모든 함수(이벤트 핸들러, 이펙트, 타임아웃 또는 그 내부의 API 호출 포함)는 해당 함수를 정의한 렌더링 호출의 props와 state를 캡처합니다.
이제 답이 명확해졌습니다! 이펙트 클린업은 "최신" props를 읽는 것이 아닙니다. 그것이 정의된 렌더링에 속한 props를 읽습니다.
왕국이 흥망성쇠를 거듭하고, 태양이 외층을 벗어던져 백색왜성이 되고, 마지막 문명이 종말을 맞이하더라도, 첫 번째 렌더링 이펙트의 클린업이 보게 될 props가
{id: 10}이 아닌 다른 것이 되게 할 수는 없습니다.이것이 React가 화면을 그린 직후에 이펙트를 처리할 수 있게 하고, 기본적으로 앱을 더 빠르게 만들 수 있게 해주는 원리입니다. 우리 코드가 필요로 한다면 이전 props는 여전히 그곳에 있습니다.
생명주기가 아닌 동기화
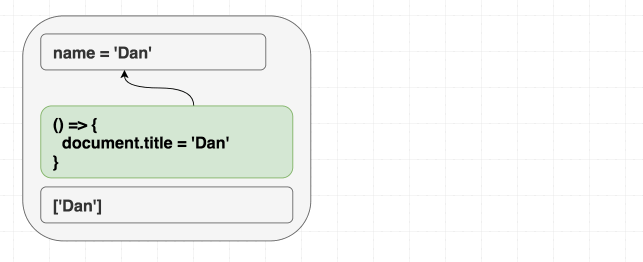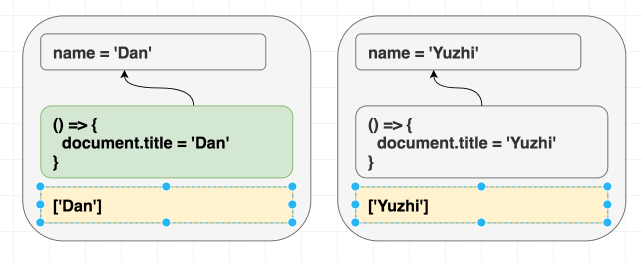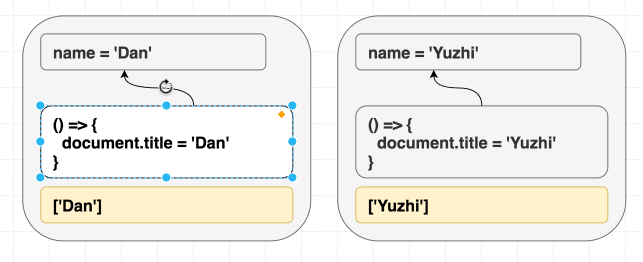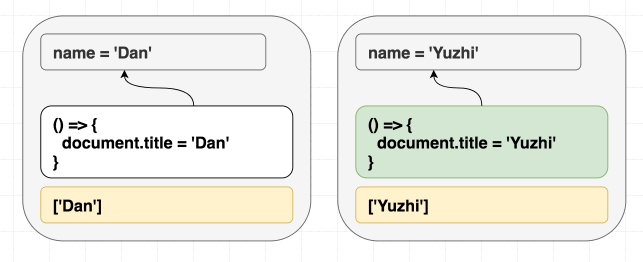
제 컴포넌트가 다음과 같다고 가정해 봅시다.
제가
<Greeting name="Dan" />을 렌더링하고 나중에 <Greeting name="Yuzhi" />를 렌더링하든, 아니면 그냥 바로 <Greeting name="Yuzhi" />를 렌더링하든 상관없습니다. 결국 두 경우 모두 "Hello, Yuzhi"를 보게 될 것입니다.사람들은 "중요한 것은 목적지가 아니라 과정이다"라고 말합니다. React에서는 그 반대입니다. 중요한 것은 과정이 아니라 목적지입니다. 이것이 jQuery 코드에서의
$.addClass와 $.removeClass 호출("과정")과 React 코드에서 CSS 클래스가 무엇이어야 하는지 지정하는 것("목적지")의 차이입니다.React는 현재 props와 state에 따라 DOM을 동기화합니다. 렌더링할 때 "마운트"와 "업데이트" 사이의 구분이 없습니다.
이펙트도 비슷한 방식으로 생각해야 합니다.
useEffect는 props와 state에 따라 React 트리 외부의 것들을 동기화하게 해줍니다.이는 익숙한 마운트/업데이트/언마운트 멘탈 모델과는 미묘하게 다릅니다. 이를 진정으로 내면화하는 것이 중요합니다. 만약 컴포넌트가 처음 렌더링되는지 여부에 따라 다르게 동작하는 이펙트를 작성하려 한다면, 여러분은 흐름을 거스르고 있는 것입니다! 결과가 "목적지"가 아닌 "과정"에 의존한다면 우리는 동기화에 실패하고 있는 것입니다.
우리가 props A, B, C로 렌더링했는지, 아니면 즉시 C로 렌더링했는지는 중요하지 않아야 합니다. 일시적인 차이(예: 데이터를 가져오는 동안)는 있을 수 있지만, 결국 최종 결과는 같아야 합니다.
물론, 모든 렌더링마다 모든 이펙트를 실행하는 것은 효율적이지 않을 수 있습니다. (그리고 어떤 경우에는 무한 루프로 이어질 수도 있습니다.)
그렇다면 이를 어떻게 해결할 수 있을까요?
React에게 이펙트 비교(Diffing) 가르치기
우리는 이미 DOM을 통해 그 교훈을 배웠습니다. 매 재렌더링마다 DOM을 건드리는 대신, React는 실제로 변경된 DOM 부분만 업데이트합니다.
여러분이
를
로 업데이트할 때, React는 두 개의 객체를 봅니다.
React는 각 props를 살펴보고
children이 변경되어 DOM 업데이트가 필요하지만, className은 그렇지 않다는 것을 결정합니다. 그래서 다음과 같이만 수행할 수 있습니다.이펙트에서도 이와 같은 작업을 할 수 있을까요? 이펙트를 적용할 필요가 없을 때 재실행을 피할 수 있다면 좋을 것입니다.
예를 들어, state 변경으로 인해 컴포넌트가 재렌더링될 수 있습니다.
하지만 우리 이펙트는
counter state를 사용하지 않습니다. 우리 이펙트는 document.title을 name prop과 동기화하지만, name prop은 동일합니다. 카운터가 바뀔 때마다 document.title을 다시 할당하는 것은 이상적이지 않아 보입니다.좋습니다, 그럼 React가 그냥... 이펙트를 비교할 수 있을까요?
그럴 수 없습니다. React는 함수를 호출해 보지 않고는 그 함수가 무엇을 하는지 추측할 수 없습니다. (소스 코드에는 구체적인 값이 들어있지 않고 그저
name prop을 닫고 있을 뿐입니다.)이것이 이펙트의 불필요한 재실행을 피하고 싶을 때
useEffect에 의존성 배열(deps라고도 함) 인자를 제공할 수 있는 이유입니다.이는 마치 React에게 이렇게 말하는 것과 같습니다. "이봐, 네가 이 함수 내부를 볼 수 없다는 건 알지만, 이 함수가 렌더링 스코프에서
name 외에는 아무것도 사용하지 않는다고 약속할게."이펙트가 실행된 현재 시점과 이전 시점 사이에 이 값들이 모두 같다면, 동기화할 것이 없으므로 React는 이펙트를 건너뛸 수 있습니다.
의존성 배열의 값 중 하나라도 렌더링 간에 다르다면, 이펙트 실행을 건너뛸 수 없음을 알게 됩니다. 모든 것을 동기화하세요!
의존성에 대해 React를 속이지 마세요
의존성에 대해 React를 속이는 것은 나쁜 결과를 초래합니다. 직관적으로는 이해가 가지만, 클래스 기반의 멘탈 모델로
useEffect를 시도하는 거의 모든 사람이 규칙을 어기려 하는 것을 보았습니다. (저도 처음에는 그랬습니다!)"하지만 난 마운트될 때만 실행하고 싶단 말이야!"라고 말할 수도 있습니다. 지금은 이것만 기억하세요. 만약 deps를 지정한다면, 이펙트 내부에서 사용되는 컴포넌트 내부의 모든 값은 그곳에 있어야 합니다. props, state, 함수 등 컴포넌트 안에 있는 모든 것이 포함됩니다.
가끔 그렇게 하면 문제가 발생할 때가 있습니다. 예를 들어, 데이터 페칭 무한 루프가 발생하거나 소켓이 너무 자주 재생성될 수 있습니다. 그 문제의 해결책은 의존성을 제거하는 것이 아닙니다. 곧 해결책들을 살펴보겠습니다.
하지만 해결책으로 넘어가기 전에, 문제를 더 잘 이해해 봅시다.
의존성이 거짓말을 할 때 일어나는 일
deps에 이펙트가 사용하는 모든 값이 포함되어 있다면, React는 언제 재실행해야 할지 압니다.
(의존성이 다르므로 이펙트를 재실행합니다.)
하지만 이 이펙트에
[]를 지정했다면, 새로운 이펙트 함수는 실행되지 않을 것입니다.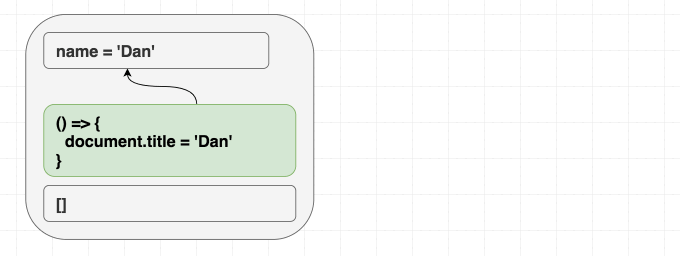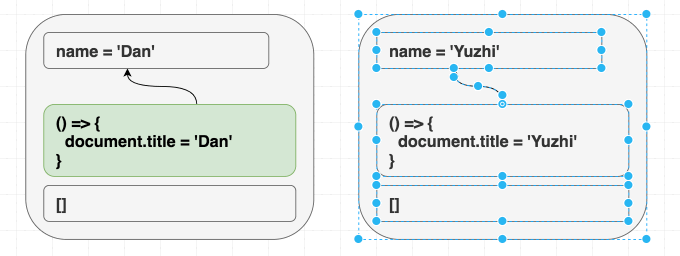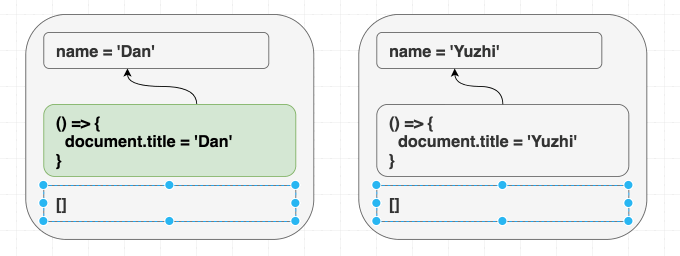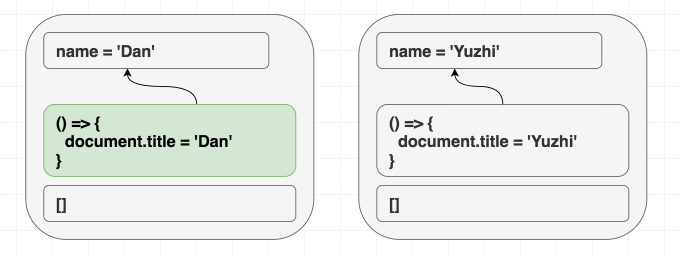
(의존성이 같으므로 이펙트를 건너뜁니다.)
이 경우 문제는 명백해 보입니다. 하지만 클래스에서의 해결책이 기억 속에서 "튀어나오는" 다른 사례에서는 직관이 여러분을 속일 수 있습니다.
예를 들어, 매초 증가하는 카운터를 작성한다고 해봅시다. 클래스를 사용할 때 우리의 직관은 "인터벌(Interval)을 한 번 설정하고 한 번 해제한다"입니다. 여기 어떻게 할 수 있는지에 대한 예시가 있습니다. 이 코드를 정신적으로
useEffect로 번역할 때, 우리는 본능적으로 deps에 []를 추가합니다. "한 번만 실행하고 싶으니까", 맞죠?만약 여러분의 멘탈 모델이 "의존성은 이펙트를 언제 다시 트리거할지 지정하게 해준다"라면, 이 예시는 여러분에게 존재론적 위기를 줄 수도 있습니다. 인터벌이니까 한 번만 트리거하고 싶은데, 왜 문제가 생기는 걸까요?
하지만 의존성이 렌더링 스코프에서 이펙트가 사용하는 모든 것에 대해 React에게 주는 힌트라는 것을 안다면 이해가 됩니다. 이펙트는
count를 사용하지만 우리는 []를 사용하여 그렇지 않다고 거짓말을 했습니다. 머지않아 이것이 우리를 괴롭힐 것입니다!첫 번째 렌더링에서
count는 0입니다. 따라서 첫 번째 렌더링 이펙트의 setCount(count + 1)은 setCount(0 + 1)을 의미합니다. [] deps 때문에 이펙트를 절대 재실행하지 않으므로, 매초 setCount(0 + 1)을 계속 호출하게 됩니다.우리는 컴포넌트 내부의 값을 사용하면서도 사용하지 않는다고 React에게 거짓말을 했습니다!
우리 이펙트는 컴포넌트 내부(하지만 이펙트 외부)의 값인
count를 사용합니다.따라서
[]를 의존성으로 지정하면 버그가 발생합니다. React는 의존성을 비교하고 이 이펙트 업데이트를 건너뛸 것입니다.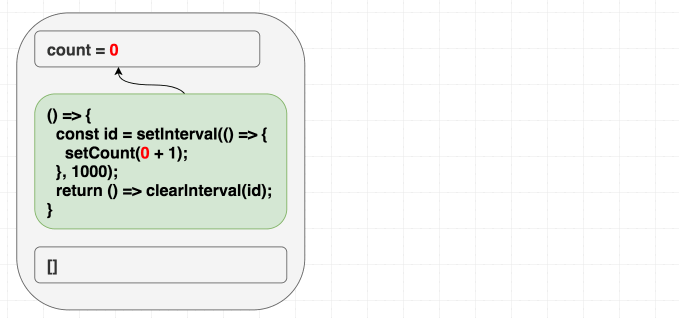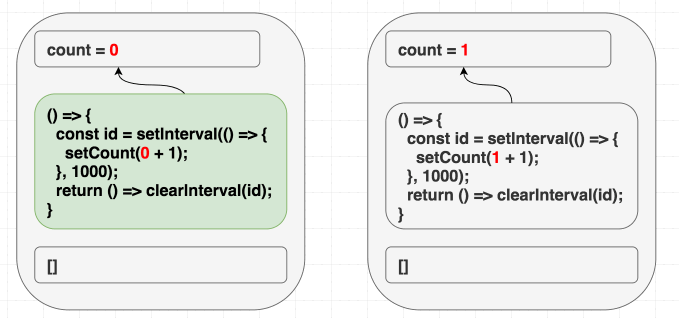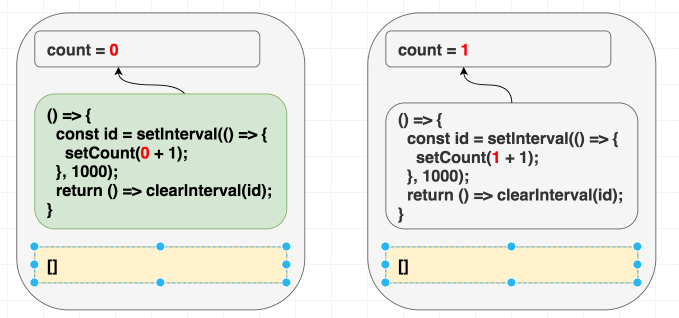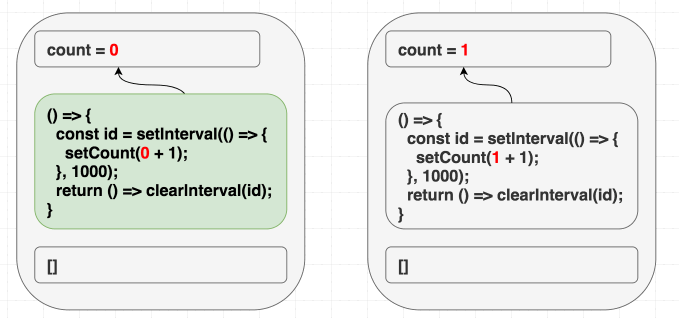
(의존성이 같으므로 이펙트를 건너뜁니다.)
이와 같은 문제는 생각하기 어렵습니다. 따라서 저는 항상 이펙트 의존성에 대해 정직하고 모든 의존성을 지정하는 것을 엄격한 규칙으로 삼기를 권장합니다. (팀에서 이를 강제하고 싶다면 린트 규칙을 제공합니다.)
의존성에 대해 정직해지는 두 가지 방법
의존성에 대해 정직해지는 두 가지 전략이 있습니다. 일반적으로 첫 번째 전략으로 시작하고, 필요한 경우 두 번째 전략을 적용해야 합니다.
첫 번째 전략은 이펙트 내부에서 사용되는 컴포넌트 내부의 모든 값을 포함하도록 의존성 배열을 수정하는 것입니다.
count를 dep에 포함해 봅시다.이렇게 하면 의존성 배열이 올바르게 됩니다. 이상적이지는 않을 수 있지만, 우리가 가장 먼저 해결해야 했던 문제입니다. 이제
count가 변경되면 이펙트가 재실행되고, 다음 인터벌은 setCount(count + 1)에서 해당 렌더링의 count를 참조하게 됩니다.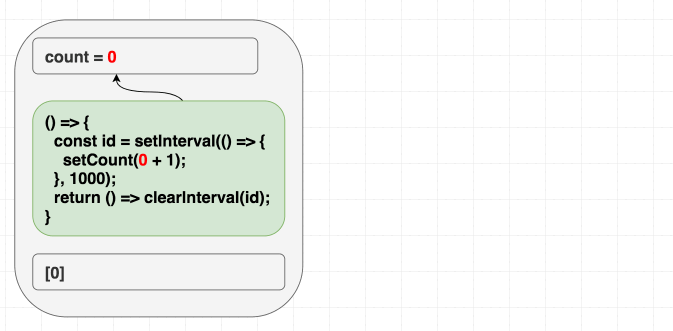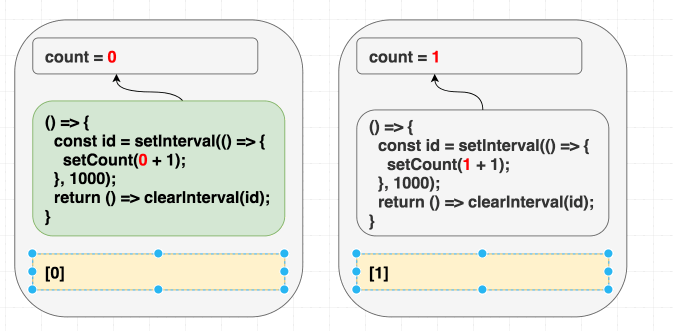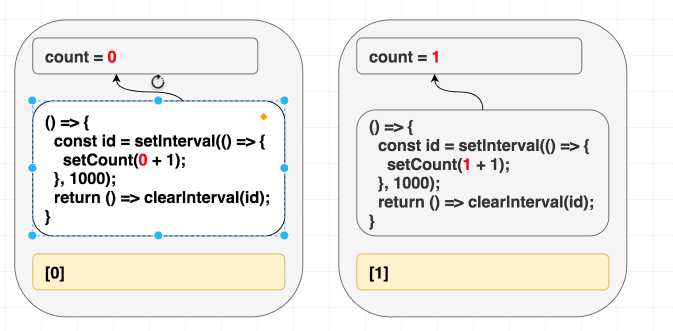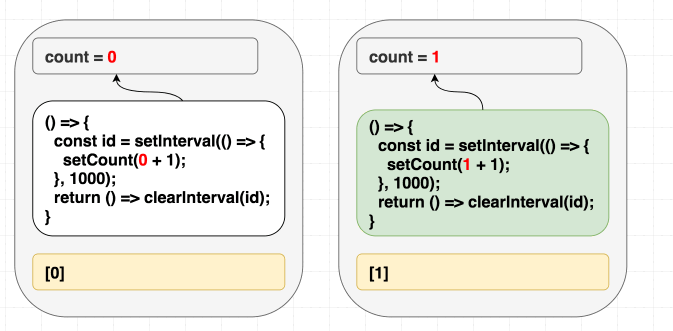
(의존성이 다르므로 이펙트를 재실행합니다.)
두 번째 전략은 우리가 원하는 것보다 더 자주 바뀌는 값을 필요로 하지 않도록 이펙트 코드를 변경하는 것입니다. 우리는 의존성에 대해 거짓말을 하고 싶지 않습니다. 단지 이펙트가 더 적은 의존성을 갖도록 바꾸고 싶을 뿐입니다.
의존성을 제거하기 위한 몇 가지 일반적인 기술을 살펴봅시다.
이펙트를 자급자족하게 만들기
우리는 이펙트에서
count 의존성을 제거하고 싶습니다.이를 위해 스스로에게 물어봐야 합니다. 우리는
count를 무엇을 위해 사용하고 있는가? 오직 setCount 호출을 위해서만 사용하는 것 같습니다. 그런 경우 스코프 내에 count가 전혀 필요하지 않습니다. 이전 state를 기반으로 state를 업데이트하고 싶을 때는 setState의 함수형 업데이트(Functional updater) 형태를 사용할 수 있습니다.저는 이런 경우를 "가짜 의존성"이라고 생각하는 것을 좋아합니다. 네, 이펙트 내부에
setCount(count + 1)을 썼기 때문에 count는 필요한 의존성이었습니다. 하지만 우리는 count를 count + 1로 변환하여 React에 "다시 보내기" 위해서만 count가 필요했습니다. 하지만 React는 이미 현재의 count를 알고 있습니다. 우리가 해야 할 일은 React에게 현재 값이 무엇이든 상관없이 state를 증가시키라고 말하는 것뿐입니다.그것이 바로
setCount(c => c + 1)이 하는 일입니다. 이를 React에게 state가 어떻게 변해야 하는지에 대한 "지시를 보내는 것"으로 생각할 수 있습니다. 이 "업데이트 형태"는 여러 업데이트를 일괄 처리(Batching)할 때와 같은 다른 경우에도 도움이 됩니다.우리가 의존성을 제거하기 위해 실제로 작업을 수행했다는 점에 주목하세요. 우리는 속이지 않았습니다. 우리 이펙트는 더 이상 렌더링 스코프에서
counter 값을 읽지 않습니다.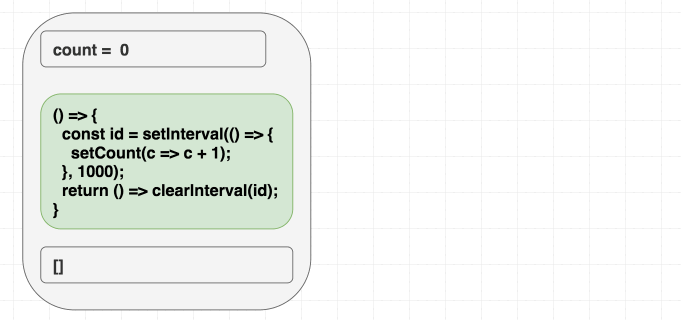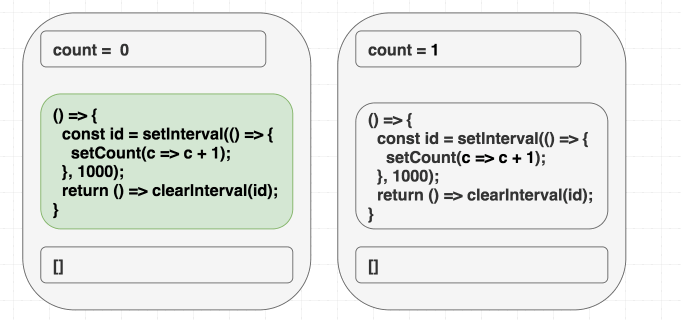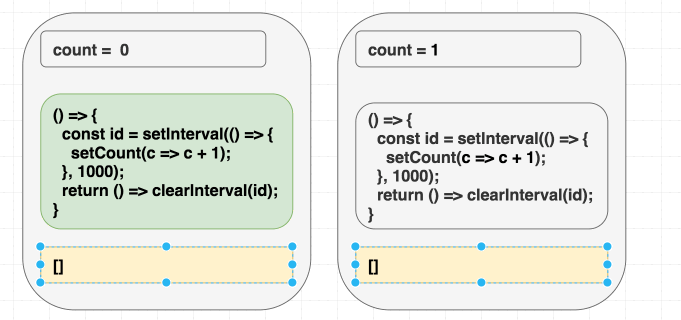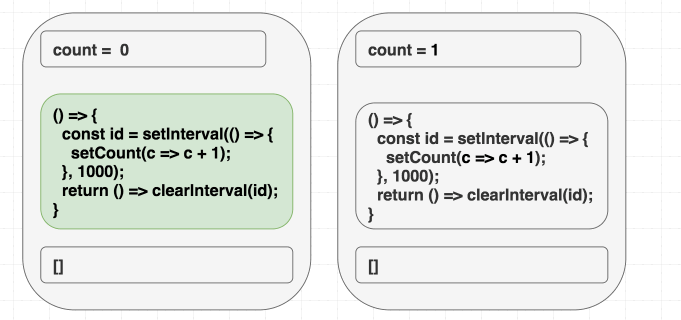
(의존성이 같으므로 이펙트를 건너뜁니다.)
여기에서 시도해 볼 수 있습니다.
이 이펙트는 한 번만 실행되지만, 첫 번째 렌더링에 속한 인터벌 콜백은 인터벌이 발생할 때마다
c => c + 1 업데이트 지시를 완벽하게 보낼 수 있습니다. 더 이상 현재의 counter state를 알 필요가 없습니다. React가 이미 알고 있으니까요.함수형 업데이트와 구글 문서
이펙트의 멘탈 모델로 동기화에 대해 이야기했던 것을 기억하시나요? 동기화의 흥미로운 측면은 시스템 간의 "메시지"를 상태와 엉키지 않게 유지하고 싶을 때가 많다는 것입니다. 예를 들어, 구글 문서에서 문서를 편집할 때 실제로 페이지 전체를 서버로 보내지 않습니다. 그것은 매우 비효율적일 것입니다. 대신 사용자가 하려고 했던 일의 표현(Representation)을 보냅니다.
우리의 사례는 다르지만, 이펙트에도 비슷한 철학이 적용됩니다. 이펙트 내부에서 컴포넌트로 최소한의 필요한 정보만 보내는 것이 도움이 됩니다.
setCount(c => c + 1)과 같은 업데이트 형태는 현재 카운트에 "오염"되지 않았기 때문에 setCount(count + 1)보다 엄격하게 적은 정보를 전달합니다. 이는 오직 액션("증가시키기")만을 표현합니다. React로 생각하기는 최소한의 state를 찾는 것을 포함합니다. 이는 업데이트에 대해서도 동일한 원칙입니다.결과가 아닌 *의도(Intent)*를 인코딩하는 것은 구글 문서가 협업 편집을 해결하는 방식과 유사합니다. 비유가 좀 과할 수도 있지만, 함수형 업데이트는 React에서 비슷한 역할을 합니다. 여러 소스(이벤트 핸들러, 이펙트 구독 등)로부터의 업데이트가 일괄적으로, 그리고 예측 가능한 방식으로 올바르게 적용될 수 있도록 보장합니다.
하지만
setCount(c => c + 1)조차도 그리 훌륭하지는 않습니다. 약간 이상해 보이고 할 수 있는 일이 매우 제한적입니다. 예를 들어, 서로 의존하는 두 개의 state 변수가 있거나, prop을 기반으로 다음 state를 계산해야 한다면 도움이 되지 않습니다. 다행히 setCount(c => c + 1)에는 더 강력한 자매 패턴이 있습니다. 그 이름은 useReducer입니다.액션에서 업데이트 분리하기
이전 예시를
count와 step이라는 두 개의 state 변수를 갖도록 수정해 봅시다. 우리 인터벌은 step 입력값만큼 카운트를 증가시킬 것입니다.우리는 속이지 않고 있습니다. 이펙트 내부에서
step을 사용하기 시작했으므로 의존성에 추가했습니다. 그래서 코드가 올바르게 작동하는 것입니다.이 예시의 현재 동작은
step을 변경하면 인터벌이 재시작되는 것입니다. step이 의존성 중 하나이기 때문이죠. 그리고 많은 경우, 그것이 바로 여러분이 원하는 동작일 것입니다! 이펙트를 해제하고 새로 설정하는 것은 전혀 잘못된 것이 아니며, 타당한 이유가 없다면 이를 피할 필요는 없습니다.하지만
step이 변경되어도 인터벌 시계가 초기화되지 않기를 원한다고 가정해 봅시다. 이펙트에서 step 의존성을 어떻게 제거할까요?어떤 state 변수를 설정하는 것이 다른 state 변수의 현재 값에 의존할 때, 두 가지 모두를
useReducer로 교체해 보는 것이 좋습니다.setSomething(something => ...)을 쓰고 있는 자신을 발견했다면, 리듀서(Reducer) 사용을 고려해 볼 좋은 타이밍입니다. 리듀서는 컴포넌트에서 발생한 "액션"을 표현하는 것과 그에 응답하여 state가 어떻게 업데이트되는지를 분리하게 해줍니다.이펙트에서
step 의존성을 dispatch 의존성으로 바꿔봅시다.여러분은 "이게 뭐가 더 나은가요?"라고 물을 수 있습니다. 답은 React가 컴포넌트 생명주기 동안
dispatch 함수가 변하지 않음을 보장한다는 것입니다. 따라서 위 예시는 인터벌을 재구독할 필요가 전혀 없습니다.문제를 해결했습니다!
(React가
dispatch, setState, useRef 컨테이너 값이 정적임을 보장하므로 deps에서 생략할 수 있습니다. 하지만 지정해도 해가 되지는 않습니다.)이펙트 내부에서 state를 읽는 대신, 무슨 일이 일어났는지에 대한 정보를 인코딩하는 액션을 디스패치합니다. 이를 통해 이펙트는
step state와 분리된 상태를 유지할 수 있습니다. 우리 이펙트는 state를 어떻게 업데이트하는지 신경 쓰지 않고, 그저 무슨 일이 일어났는지만 알려줍니다. 그리고 리듀서가 업데이트 로직을 중앙 집중화합니다.왜 useReducer가 Hooks의 치트 모드인가
우리는 이펙트가 이전 state나 다른 state 변수를 기반으로 state를 설정해야 할 때 의존성을 제거하는 방법을 보았습니다. 하지만 다음 state를 계산하기 위해 _props_가 필요하다면 어떨까요? 예를 들어, 우리 API가
<Counter step={1} />이라고 해봅시다. 분명히 이런 경우에는 props.step을 의존성으로 지정하는 것을 피할 수 없겠죠?사실, 피할 수 있습니다! 리듀서 자체를 컴포넌트 내부에 두어 props를 읽게 할 수 있습니다.
이 경우에도
dispatch의 정체성(Identity)은 재렌더링 간에 안정적임이 보장됩니다. 따라서 원한다면 이펙트 deps에서 생략할 수 있습니다. 이펙트가 재실행되지 않을 것입니다.여러분은 의아할 수 있습니다. 이게 어떻게 가능할까요? 다른 렌더링에 속한 이펙트 내부에서 호출되었을 때 리듀서가 어떻게 props를 "알" 수 있을까요? 답은 여러분이
dispatch할 때 React는 단지 액션을 기억해 두었다가, 다음 렌더링 중에 리듀서를 호출한다는 것입니다. 그 시점에는 새로운 props가 스코프 내에 있을 것이고, 여러분은 이펙트 내부에 있지 않게 됩니다.이것이 제가
useReducer를 Hooks의 "치트 모드"라고 생각하는 이유입니다. 업데이트 로직을 무슨 일이 일어났는지 설명하는 것과 분리할 수 있게 해줍니다. 이는 결과적으로 이펙트에서 불필요한 의존성을 제거하고 필요 이상으로 자주 재실행되는 것을 방지하는 데 도움이 됩니다.함수를 이펙트 내부로 옮기기
흔한 실수는 함수가 의존성이 되어서는 안 된다고 생각하는 것입니다. 예를 들어, 이런 코드는 작동할 것처럼 보입니다.
분명히 말하자면, 이 코드는 작동합니다. 하지만 지역 함수를 단순히 생략할 때의 문제는 컴포넌트가 커짐에 따라 모든 케이스를 처리하고 있는지 알기 매우 어려워진다는 점입니다!
우리 코드가 다음과 같이 쪼개져 있고 각 함수가 5배 더 길다고 상상해 보세요.
이제 나중에 이 함수들 중 하나에서 어떤 state나 prop을 사용한다고 해봅시다.
만약 이 함수들을 호출하는(아마도 다른 함수를 거쳐서!) 이펙트의 deps를 업데이트하는 것을 잊는다면, 우리 이펙트는 props와 state의 변경 사항을 동기화하는 데 실패할 것입니다. 이는 좋지 않은 상황입니다.
다행히 이 문제에 대한 쉬운 해결책이 있습니다. 어떤 함수를 오직 이펙트 _내부_에서만 사용한다면, 그 함수를 이펙트 _내부_로 직접 옮기세요.
이것의 장점은 무엇일까요? 더 이상 "전이적 의존성(Transitive dependencies)"에 대해 생각할 필요가 없다는 것입니다. 우리 의존성 배열은 더 이상 거짓말을 하지 않습니다. 우리는 이펙트에서 컴포넌트의 외부 스코프에 있는 어떤 것도 사용하지 않고 있습니다.
나중에
getFetchUrl이 query state를 사용하도록 수정한다면, 우리가 이펙트 내부에서 수정하고 있다는 것을 훨씬 더 쉽게 알아차릴 수 있고, 따라서 이펙트 의존성에 query를 추가해야 한다는 것도 알게 됩니다.이 의존성을 추가함으로써 우리는 단지 "React를 달래는" 것이 아닙니다. 쿼리가 변경될 때 데이터를 다시 가져오는 것은 타당합니다.
useEffect의 설계는 여러분이 데이터 흐름의 변화를 알아차리고 우리 이펙트가 이를 어떻게 동기화해야 할지 선택하도록 강제합니다. 제품 사용자가 버그를 발견할 때까지 이를 무시하는 대신 말이죠.eslint-plugin-react-hooks 플러그인의 exhaustive-deps 린트 규칙 덕분에, 여러분은 에디터에서 타이핑하는 동안 이펙트를 분석하고 어떤 의존성이 누락되었는지 제안받을 수 있습니다. 즉, 기계가 컴포넌트에서 어떤 데이터 흐름의 변화가 올바르게 처리되지 않았는지 알려줄 수 있습니다.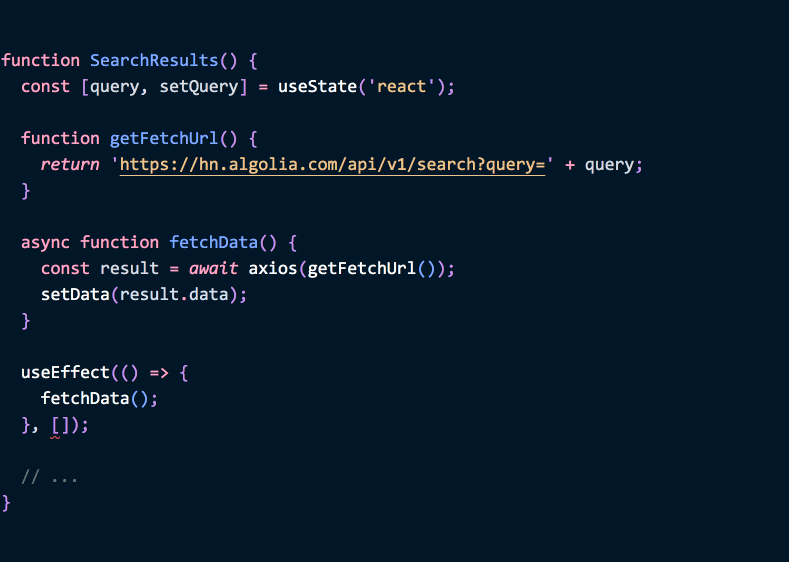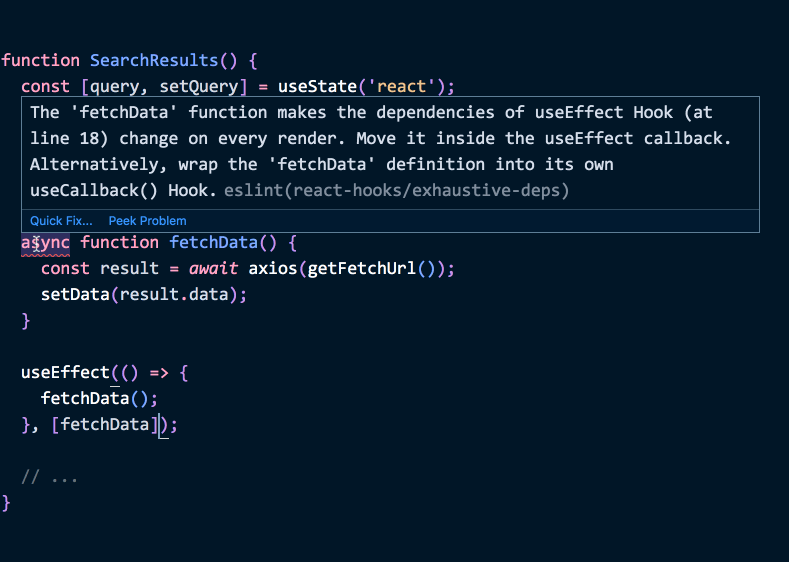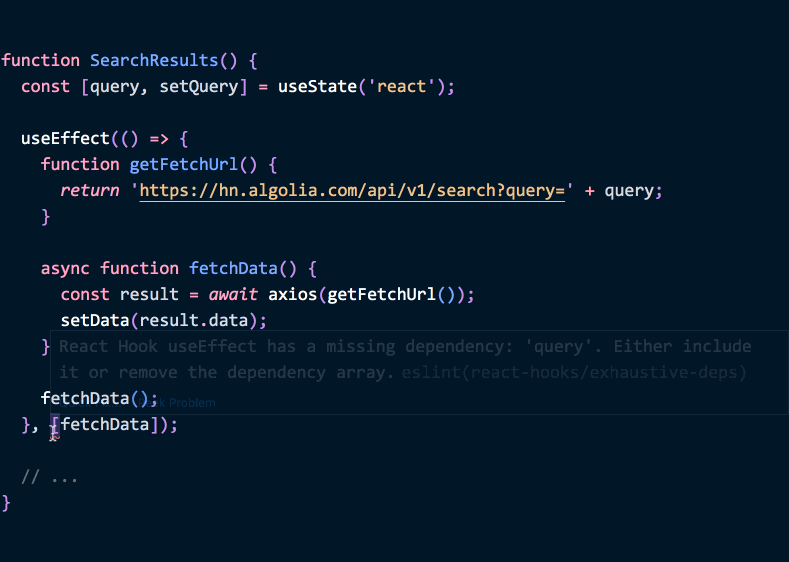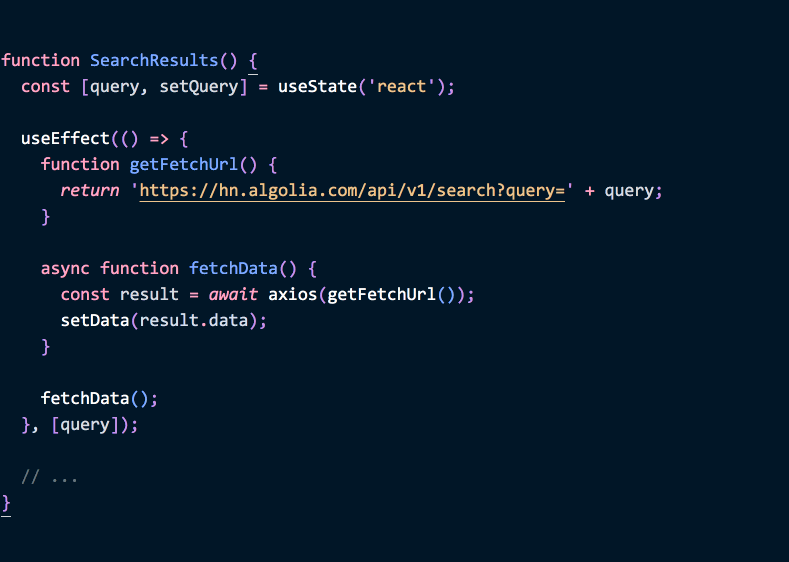
정말 멋지죠.
하지만 이 함수를 이펙트 내부에 넣을 수 없어요
가끔 함수를 이펙트 내부로 옮기고 싶지 않을 때가 있습니다. 예를 들어, 동일한 컴포넌트 내의 여러 이펙트가 같은 함수를 호출할 수 있고, 로직을 복사해서 붙여넣고 싶지 않을 수 있습니다. 또는 그 함수가 prop일 수도 있습니다.
이런 경우 이펙트 의존성에서 함수를 제외해야 할까요? 저는 그렇게 생각하지 않습니다. 다시 말하지만, 이펙트는 의존성에 대해 거짓말을 해서는 안 됩니다. 보통 더 나은 해결책이 있습니다. 흔한 오해는 "함수는 절대 변하지 않을 것"이라는 생각입니다. 하지만 이 글 전체에서 배웠듯이, 이는 진실과 거리가 멉니다. 실제로 컴포넌트 내부에 정의된 함수는 매 렌더링마다 바뀝니다!
그 자체로 문제가 됩니다. 두 개의 이펙트가
getFetchUrl을 호출한다고 가정해 봅시다.이 경우 로직을 공유할 수 없게 되므로
getFetchUrl을 어느 한 이펙트 내부로 옮기고 싶지 않을 수 있습니다.반면에 이펙트 의존성에 대해 "정직"하다면 문제에 부딪힐 수 있습니다. 두 이펙트 모두 (매 렌더링마다 달라지는)
getFetchUrl에 의존하므로, 의존성 배열이 무용지물이 됩니다.이에 대한 유혹적인 해결책은 deps 목록에서
getFetchUrl 함수를 그냥 빼버리는 것입니다. 하지만 저는 그것이 좋은 해결책이라고 생각하지 않습니다. 그렇게 하면 이펙트가 처리해야 하는 데이터 흐름의 변화를 추가했을 때 이를 알아차리기 어렵게 만듭니다. 이는 앞서 보았던 "절대 업데이트되지 않는 인터벌"과 같은 버그로 이어집니다.대신, 더 간단한 두 가지 다른 해결책이 있습니다.
첫째, 함수가 컴포넌트 스코프의 어떤 것도 사용하지 않는다면, 함수를 컴포넌트 외부로 끌어올리고 이펙트 내부에서 자유롭게 사용할 수 있습니다.
이 함수는 렌더링 스코프에 있지 않고 데이터 흐름의 영향을 받을 수 없으므로 deps에 지정할 필요가 없습니다. 실수로 props나 state에 의존할 수도 없습니다.
useCallback은 본질적으로 의존성 체크의 레이어를 하나 더 추가하는 것과 같습니다. 이는 다른 쪽 끝에서 문제를 해결합니다. 함수 의존성을 피하는 대신, 함수 자체가 필요할 때만 바뀌도록 만드는 것입니다.왜 이 접근 방식이 유용한지 알아봅시다. 이전 예시는 두 개의 검색 결과(
'react'와 'redux')를 보여주었습니다. 하지만 임의의 query를 검색할 수 있도록 입력을 추가하고 싶다고 가정해 봅시다. 이제 getFetchUrl은 인자를 받는 대신 지역 state에서 query를 읽을 것입니다.그러면 즉시
query 의존성이 누락되었다는 것을 알게 됩니다.만약
useCallback deps에 query를 포함하도록 수정한다면, getFetchUrl을 deps로 가진 모든 이펙트는 query가 변경될 때마다 재실행될 것입니다.useCallback 덕분에 query가 같다면 getFetchUrl도 동일하게 유지되고 우리 이펙트는 재실행되지 않습니다. 하지만 query가 바뀌면 getFetchUrl도 바뀌고 데이터를 다시 가져오게 됩니다. 이는 엑셀 스프레드시트에서 어떤 셀을 바꾸면 그것을 사용하는 다른 셀들이 자동으로 다시 계산되는 것과 매우 비슷합니다.이것은 단지 데이터 흐름과 동기화 사고방식을 수용한 결과일 뿐입니다. 부모로부터 전달받은 함수 props에 대해서도 동일한 해결책이 작동합니다.
fetchData는 Parent 내부의 query state가 바뀔 때만 변경되므로, 우리 Child는 앱에 실제로 필요할 때까지 데이터를 다시 가져오지 않을 것입니다.함수는 데이터 흐름의 일부인가요?
흥미롭게도, 이 패턴은 클래스에서 깨지게 되는데 이는 이펙트와 생명주기 패러다임의 차이를 극명하게 보여줍니다. 다음 번역을 고려해 보세요.
여러분은 이렇게 생각할 수도 있습니다. "이봐요 Dan, 우리 모두
useEffect가 componentDidMount와 componentDidUpdate를 합친 것과 같다는 걸 알아요. 그만 좀 하세요!" 하지만 이것은 componentDidUpdate를 사용해도 작동하지 않습니다.당연하죠,
fetchData는 클래스 메서드니까요! (정확히는 클래스 프로퍼티지만, 결과는 같습니다.) state 변경 때문에 달라지지 않습니다. 따라서 this.props.fetchData는 prevProps.fetchData와 항상 같을 것이고 우리는 절대 다시 페칭하지 않을 것입니다. 그럼 이 조건을 그냥 제거해 볼까요?잠깐만요, 이러면 모든 재렌더링마다 페칭하게 됩니다. (트리 상단에 애니메이션을 추가해 보면 이를 발견하는 재미가 쏠쏠할 겁니다.) 그럼 특정 쿼리에 바인딩해 볼까요?
하지만 그러면
this.props.fetchData !== prevProps.fetchData는 query가 바뀌지 않았더라도 항상 true가 됩니다! 그래서 항상 다시 페칭하게 되죠.클래스에서 이 난제를 해결하는 유일한 실제 방법은 울며 겨자 먹기로
query 자체를 Child 컴포넌트에 전달하는 것입니다. Child는 실제로 query를 사용하지는 않지만, 그것이 바뀔 때 다시 페칭을 트리거할 수 있습니다.React에서 클래스로 작업해 온 수년 동안, 저는 불필요한 props를 아래로 전달하고 부모 컴포넌트의 캡슐화를 깨는 것에 너무 익숙해져서, 왜 그렇게 해야만 했는지 일주일 전에서야 깨달았습니다.
클래스에서 함수 props는 그 자체로 진정한 데이터 흐름의 일부가 아닙니다. 메서드는 가변적인
this 변수를 닫고 있으므로 그들의 정체성이 무엇을 의미한다고 신뢰할 수 없습니다. 따라서 함수만 원할 때조차도 이를 "비교"할 수 있도록 다른 데이터들을 함께 전달해야 합니다. 부모로부터 전달된 this.props.fetchData가 어떤 state에 의존하는지, 그리고 그 state가 방금 바뀌었는지 알 수 없기 때문입니다.useCallback을 사용하면 함수가 데이터 흐름에 온전히 참여할 수 있습니다. 함수 입력이 바뀌면 함수 자체가 바뀌고, 그렇지 않으면 그대로 유지된다고 말할 수 있습니다. useCallback이 제공하는 세밀함 덕분에 props.fetchData와 같은 props의 변경 사항이 자동으로 아래로 전파될 수 있습니다.모든 곳에
useCallback을 넣는 것은 꽤 번거롭다는 점을 강조하고 싶습니다. 이는 훌륭한 탈출구이며, 함수가 아래로 전달되면서 동시에 자식의 이펙트 내부에서 호출될 때 유용합니다. 또는 자식 컴포넌트의 메모이제이션(Memoization)이 깨지는 것을 방지하고 싶을 때도 유용하죠. 하지만 Hooks는 콜백을 아래로 전달하는 것을 피하는 방식에 더 적합합니다.위의 예시들에서 저는
fetchData가 이펙트 내부에 있거나(이펙트 자체가 커스텀 Hook으로 추출될 수 있음) 최상위 레벨의 import인 것을 훨씬 선호합니다. 저는 이펙트를 단순하게 유지하고 싶고, 이펙트 안의 콜백은 그에 도움이 되지 않습니다. ("요청이 진행 중인 동안 어떤 props.onComplete 콜백이 바뀌면 어떡하지?") 클래스 동작을 시뮬레이션할 수는 있지만, 그것이 경쟁 상태(Race condition)를 해결해 주지는 않습니다.경쟁 상태에 대하여
클래스를 사용한 전형적인 데이터 페칭 예시는 다음과 같을 것입니다.
이미 아시겠지만, 이 코드는 버그가 있습니다. 업데이트를 처리하지 않기 때문입니다. 그래서 온라인에서 찾을 수 있는 두 번째 전형적인 예시는 다음과 같습니다.
이것이 확실히 더 낫습니다! 하지만 여전히 버그가 있습니다. 요청이 순서와 다르게 도착할 수 있기 때문입니다. 제가
{id: 10}을 페칭하다가 {id: 20}으로 바꿨는데, {id: 20} 요청이 먼저 도착한다면, 더 일찍 시작했지만 더 늦게 끝난 요청이 제 state를 잘못 덮어쓰게 될 것입니다.이를 경쟁 상태라고 하며,
async / await(무언가 결과를 기다린다고 가정함)를 하향식 데이터 흐름(비동기 함수 중간에 props나 state가 바뀔 수 있음)과 섞어 쓸 때 흔히 발생합니다.이펙트가 이 문제를 마법처럼 해결해 주지는 않지만, 이펙트에
async 함수를 직접 전달하려고 하면 경고를 줄 것입니다. (우리가 겪을 수 있는 문제들을 더 잘 설명하기 위해 그 경고를 개선해야 합니다.)사용하는 비동기 방식이 취소(Cancellation)를 지원한다면 훌륭합니다! 클린업 함수에서 바로 비동기 요청을 취소할 수 있습니다.
또는, 가장 쉬운 임시방편은 불리언(Boolean) 값으로 추적하는 것입니다.
이 글은 에러와 로딩 상태를 처리하는 방법뿐만 아니라 해당 로직을 커스텀 Hook으로 추출하는 방법에 대해 더 자세히 다룹니다. Hooks를 사용한 데이터 페칭에 대해 더 배우고 싶다면 확인해 보시길 권장합니다.
기준 높이기
클래스 생명주기 사고방식에서 사이드 이펙트(Side effect)는 렌더링 출력물과 다르게 동작합니다. UI 렌더링은 props와 state에 의해 주도되며 그것들과 일관성이 보장되지만, 사이드 이펙트는 그렇지 않습니다. 이것이 버그의 흔한 원인입니다.
useEffect의 사고방식에서는 모든 것이 기본적으로 동기화됩니다. 사이드 이펙트는 React 데이터 흐름의 일부가 됩니다. 모든 useEffect 호출에 대해, 일단 올바르게 작성하면 컴포넌트는 에지 케이스(Edge case)를 훨씬 더 잘 처리합니다.하지만 올바르게 작성하기 위한 초기 비용이 더 높습니다. 이는 성가실 수 있습니다. 에지 케이스를 잘 처리하는 동기화 코드를 작성하는 것은 렌더링과 일관되지 않은 일회성 사이드 이펙트를 실행하는 것보다 본질적으로 더 어렵습니다.
만약
useEffect가 여러분이 대부분의 시간 동안 사용하는 도구였다면 이는 걱정스러운 일이었을 것입니다. 하지만 이것은 저수준(Low-level)의 빌딩 블록입니다. 지금은 Hooks 초기 단계라 모든 사람이 항상 저수준 Hooks를 사용하며, 특히 튜토리얼에서 더욱 그렇습니다. 하지만 실제로는 좋은 API들이 탄력을 받으면서 커뮤니티가 더 고수준의 Hooks로 이동하기 시작할 것입니다.저는 여러 앱이 앱의 인증 로직을 캡슐화한
useFetch나 테마 컨텍스트를 사용하는 useTheme과 같은 고유한 Hooks를 만드는 것을 보고 있습니다. 그런 도구 상자를 갖추게 되면 useEffect를 그렇게 자주 사용하지 않게 됩니다. 하지만 그것이 가져다주는 회복탄력성은 그 위에 구축된 모든 Hook에 혜택을 줍니다.지금까지
useEffect는 데이터 페칭에 가장 흔히 사용되었습니다. 하지만 데이터 페칭은 정확히 말하면 동기화 문제는 아닙니다. 특히 우리 deps가 종종 []인 것을 보면 명확합니다. 우리는 무엇을 동기화하고 있는 걸까요?장기적으로 데이터 페칭을 위한 Suspense는 서드파티 라이브러리들이 비동기적인 무언가(코드, 데이터, 이미지 등 무엇이든)가 준비될 때까지 렌더링을 중단하라고 React에게 알릴 수 있는 일급(First-class) 방식을 제공할 것입니다.
Suspense가 점진적으로 더 많은 데이터 페칭 유스케이스를 커버함에 따라, 저는
useEffect가 실제로 props와 state를 어떤 사이드 이펙트와 동기화하고 싶을 때 사용하는 파워 유저용 도구로 물러날 것이라고 예상합니다. 데이터 페칭과 달리, 이펙트는 이를 위해 설계되었기 때문에 이 케이스를 자연스럽게 처리합니다. 하지만 그때까지는 여기서 보여준 것과 같은 커스텀 Hooks가 데이터 페칭 로직을 재사용하는 좋은 방법입니다.마치며
이제 제가 이펙트 사용에 대해 알고 있는 거의 모든 것을 알게 되셨으니, 처음에 있는 요약(TLDR)을 다시 확인해 보세요. 이제 이해가 되시나요? 제가 놓친 것이 있나요? (아직 종이가 다 떨어지지는 않았습니다!)
트위터에서 여러분의 의견을 듣고 싶습니다! 읽어주셔서 감사합니다.
0
3
댓글
?
아직 댓글이 없습니다.
첫 번째 댓글을 작성해보세요!
Inkyu Oh님의 다른 글
더보기[번역] 프로그래밍 언어로서의 TypeScript 타입
Inkyu Oh • Front-End
0
0
11
[번역] at:// 프로토콜을 아시나요?
Inkyu Oh • Back-End
0
0
28

React Compiler의 소리 없는 실패 (그리고 해결 방법)
Inkyu Oh • Front-End
0
0
10



