[번역] USE 방법론 (The USE Method)
B
Beomsu Son
Back-End•2026.02.21
Brendan Gregg

보잉 707 비상 체크리스트 (1969)
활용도(Utilization), 포화도(Saturation), 에러(Errors)의 앞글자를 딴 USE 방법론은 모든 시스템의 성능을 분석하기 위한 방법론입니다. 이 방법론은 체크리스트 작성을 안내하며, 서버 분석 시 리소스의 병목 현상이나 에러를 신속하게 식별하는 데 사용할 수 있습니다. 이 방법론은 주어진 지표(부분적인 답변)에서 시작하여 역방향으로 추론하는 대신, 질문을 던지고 그에 대한 답변을 찾는 방식으로 시작합니다.
다양한 운영체제에 대해 USE 방법론으로 도출된 체크리스트는 왼쪽 탐색 패널(Linux, Solaris 등)에 나열되어 있습니다. 여러분의 환경에 맞게 이를 커스터마이징하고, 사용 중인 추가 도구들을 넣을 수 있습니다. 또한 일부 체크리스트에서 자동으로 생성된 성능 체크리스트의 로제타 스톤(Rosetta Stone of Performance Checklists)도 있습니다. 성능 모니터링 제품들은 사용하기 쉬운 인터페이스를 통해 관련 지표를 제공함으로써 USE 방법론을 더 쉽게 따를 수 있게 해줍니다.
서론 (Intro)
심각한 성능 문제가 발생했고, 서버가 원인이라고 의심되는 상황입니다. 가장 먼저 무엇을 확인하시겠습니까?
시작이 가장 어려운 법입니다. 우리는 다른 사람들이 중요한 영역을 간과하지 않고 일반적인 성능 문제를 신속하게 해결하는 방법을 가르치기 위해 USE 방법론을 개발했습니다. 비행 매뉴얼의 비상 체크리스트처럼, 이 방법론은 단순하고, 명확하며, 완전하고, 빨라야 합니다. USE 방법론은 다양한 기업 환경, 교육 환경(학습 도구로서), 그리고 최근에는 클라우드 컴퓨팅 환경에서 수없이 성공적으로 사용되었습니다.
USE 방법론은 세 가지 지표 유형과 복잡한 시스템에 접근하는 전략을 기반으로 합니다. 우리는 이 방법론이 5%의 노력으로 서버 문제의 약 80%를 해결한다는 것을 발견했으며, 앞으로 보여드리겠지만 서버 이외의 시스템에도 적용할 수 있습니다. 이는 더 큰 방법론 도구 상자의 일부인 하나의 도구로 생각해야 합니다. 이 방법론으로 해결할 수 없는 문제 유형도 많으며, 그런 경우에는 다른 방법과 더 긴 시간이 필요할 것입니다.
요약 (Summary)
USE 방법론은 다음과 같이 요약할 수 있습니다:
모든 리소스에 대해 활용도, 포화도, 에러를 확인하십시오.
이 방법론은 성능 조사 초기 단계에서 시스템적인 병목 현상을 식별하기 위해 사용하도록 고안되었습니다.
용어 정의:
- 리소스(resource): 모든 물리적 서버 기능 구성 요소 (CPU, 디스크, 버스 등) [1]
- 활용도(utilization): 리소스가 작업을 처리하느라 바빴던 시간의 평균 [2]
- 포화도(saturation): 리소스가 처리하지 못한 추가 작업이 있는 정도 (종종 큐(queue)에 대기 중임)
- 에러(errors): 에러 이벤트의 횟수
[1] 일부 소프트웨어 리소스나 소프트웨어에 의해 부과된 제한(리소스 제어)을 고려하고 어떤 지표가 가능한지 확인하는 것도 유용할 수 있습니다.
[2] 활용도를 리소스가 사용된 비율로 정의하는 또 다른 정의도 있습니다. 이 경우 100% 활용도는 위의 "바쁨(busy)" 정의와 달리 더 이상 작업을 수락할 수 없음을 의미합니다.
지표는 보통 다음과 같은 용어로 표현됩니다:
- 활용도: 시간 간격에 따른 백분율. 예: "한 디스크가 90% 활용도로 실행 중임".
- 포화도: 큐의 길이. 예: "CPU의 평균 실행 큐(run queue) 길이가 4임".
- 에러: 스칼라 카운트. 예: "이 네트워크 인터페이스에서 50번의 후기 충돌(late collision)이 발생함".
에러는 성능을 저하시킬 수 있고, 장애 모드가 복구 가능한 경우 즉시 인지되지 않을 수 있으므로 조사해야 합니다. 여기에는 실패 후 재시도되는 작업이나, 중복 장치 풀(pool)에서 실패한 장치 등이 포함됩니다.
낮은 활용도는 포화도가 없음을 의미할까요?
긴 시간 간격으로 평균을 냈을 때 활용도가 낮더라도, 일시적인 높은 활용도(burst)가 포화도와 성능 문제를 일으킬 수 있습니다. 이는 직관에 반할 수 있습니다!
한 고객이 CPU 활용도가 80%를 넘지 않는다는 모니터링 도구의 결과에도 불구하고 CPU 포화도(지연 시간) 문제를 겪었던 사례가 있었습니다. 모니터링 도구는 5분 평균치를 보고하고 있었는데, 그 5분 동안 CPU 활용도가 몇 초간 100%를 찍었던 것입니다.
리소스 목록 (Resource List)
시작하려면 반복해서 확인할 리소스 목록이 필요합니다. 다음은 서버를 위한 일반적인 목록입니다:
- CPU: 소켓, 코어, 하드웨어 스레드 (가상 CPU)
- 메모리: 용량
- 네트워크 인터페이스
- 스토리지 장치: I/O, 용량
- 컨트롤러: 스토리지, 네트워크 카드
- 상호 연결(Interconnects): CPU, 메모리, I/O
일부 구성 요소는 두 가지 유형의 리소스입니다. 스토리지 장치는 서비스 요청 리소스(I/O)이면서 용량 리소스(채워진 정도)이기도 합니다. 두 유형 모두 시스템 병목 현상이 될 수 있습니다. 요청 리소스는 요청을 큐에 대기시킨 후 처리할 수 있는 *큐잉 시스템(queueing systems)*으로 정의될 수 있습니다.
하드웨어 캐시(예: MMU TLB/TSB, CPU 캐시)와 같은 일부 물리적 구성 요소는 제외되었습니다. USE 방법론은 높은 활용도나 포화도 상태에서 성능 저하가 발생하여 병목 현상으로 이어지는 리소스에 가장 효과적입니다. 캐시는 높은 활용도 상황에서 성능을 향상시킵니다.
캐시 적중률(hit rates) 및 기타 성능 특성은 USE 방법론을 통해 시스템적 병목 현상을 배제한 후에 확인할 수 있습니다. 리소스를 포함해야 할지 확실하지 않다면 일단 포함시킨 후 지표가 얼마나 잘 작동하는지 확인하십시오.
기능 블록 다이어그램 (Functional Block Diagram)
리소스를 반복 확인하는 또 다른 방법은 시스템의 기능 블록 다이어그램(Functional Block Diagram)을 찾거나 그리는 것입니다. 이는 관계를 보여주므로 데이터 흐름의 병목 현상을 찾을 때 매우 유용할 수 있습니다. 다음은 Sun Fire V480 가이드 (82페이지)의 예시입니다:
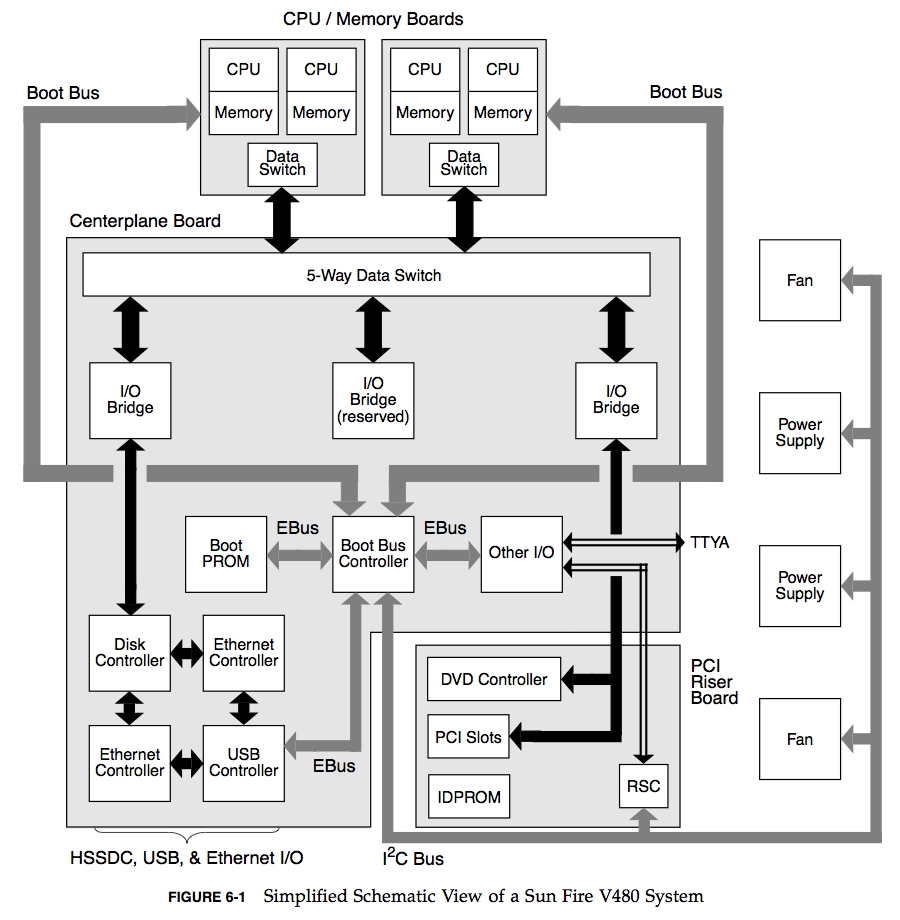
우리는 이런 다이어그램을 좋아하지만, 구하기 어려울 수도 있습니다. 하드웨어 엔지니어, 즉 실제로 물건을 만드는 사람들이 가장 좋은 리소스가 될 수 있습니다. 아니면 직접 그려볼 수도 있습니다.
다양한 버스의 활용도를 결정하는 동안, 기능 다이어그램의 각 버스에 최대 대역폭을 표시해 두십시오. 이렇게 하면 단 한 번의 측정도 하기 전에 시스템적 병목 현상을 식별할 수 있는 다이어그램이 완성됩니다. (이는 물리적 구성 요소를 변경할 수 있는 하드웨어 제품 설계 단계에서 유용한 연습이 됩니다.)
상호 연결 (Interconnects)
CPU, 메모리 및 I/O 상호 연결은 종종 간과됩니다. 다행히도 이들이 시스템 병목의 원인인 경우는 흔치 않습니다. 불행히도 만약 원인이라면, 조치를 취하기가 어려울 수 있습니다(메인보드를 업그레이드하거나, "제로 카피(zero copy)" 프로젝트 등을 통해 메모리 버스 부하를 줄이는 식의 부하 감소가 필요할 수 있습니다). USE 방법론을 사용하면 적어도 고려하지 않았던 부분인 상호 연결 성능에 대해 인지하게 됩니다. USE 방법론으로 식별한 상호 연결 문제의 예시는 HyperTransport 분석을 참조하십시오.
지표 (Metrics)
리소스 목록이 준비되면 활용도, 포화도, 에러라는 지표 유형을 고려하십시오.
다음은 몇 가지 예시입니다. 아래 표에서 각 리소스와 지표 유형에 대해 생각하며 빈칸을 채울 수 있는지 확인해 보십시오. 빈 셀에 마우스를 올리면 일반적인 Unix/Linux 용어로 설명된 몇 가지 가능한 답변이 나타납니다 (더 구체적일 수도 있습니다):
리소스 | 유형 | 지표 |
|---|---|---|
CPU | 활용도 | CPU 활용도 (CPU당 또는 시스템 전체 평균) |
CPU | 포화도 | 실행 큐 길이 또는 스케줄러 지연 시간(scheduler latency) |
메모리 용량 | 활용도 | 사용 가능한 여유 메모리 (시스템 전체) |
메모리 용량 | 포화도 | 익명 페이징(anonymous paging) 또는 스레드 스와핑 (또는 "페이지 스캐닝") |
네트워크 인터페이스 | 활용도 | 수신(RX)/송신(TX) 처리량 / 최대 대역폭 |
스토리지 장치 I/O | 활용도 | 장치 바쁨(busy) 퍼센트 |
스토리지 장치 I/O | 포화도 | 대기 큐 길이 |
스토리지 장치 I/O | 에러 | 장치 에러 ("soft", "hard" 등) |
타이밍 정보는 생략했습니다. 이 지표들은 간격당 평균이거나 카운트입니다. 또한 지표를 가져오는 방법도 생략했습니다. 여러분의 커스텀 체크리스트에는 어떤 OS 도구나 모니터링 소프트웨어를 사용할지, 어떤 통계치를 읽을지 포함하십시오. 제공되지 않는 지표에 대해서는 "?"를 적으십시오. 그러면 따라 하기 쉽고 빠르며, 시스템에 대해 가능한 한 완전한 체크리스트를 갖게 될 것입니다.
더 어려운 지표들 (Harder Metrics)
이제 좀 더 어려운 조합들입니다 (마찬가지로 먼저 생각해 보십시오!):
리소스 | 유형 | 지표 |
|---|---|---|
CPU | 에러 | 예: 수정 가능한 CPU 캐시 ECC 이벤트 또는 결함이 있는 CPU (OS와 하드웨어가 지원하는 경우) |
메모리 용량 | 에러 | 예: malloc() 실패 (보통 물리적 메모리가 아닌 가상 메모리 고갈 때문이지만) |
네트워크 | 포화도 | 포화 관련 NIC 또는 OS 이벤트; 예: "dropped", "overruns" |
스토리지 컨트롤러 | 활용도 | 컨트롤러에 따라 다름; 현재 활동 대비 체크 가능한 최대 IOPS 또는 처리량이 있을 수 있음 |
CPU 상호 연결 | 활용도 | 포트당 처리량 / 최대 대역폭 (CPU 성능 카운터) |
메모리 상호 연결 | 포화도 | 메모리 스톨 사이클(stall cycles), 높은 CPI (CPU 성능 카운터) |
I/O 상호 연결 | 활용도 | 버스 처리량 / 최대 대역폭 (하드웨어에 성능 카운터가 존재할 수 있음; 예: Intel "uncore" 이벤트) |
이러한 지표들은 일반적으로 OS에 따라 측정하기가 더 어려우며, 종종 이를 위해 직접 소프트웨어를 작성해야 할 때도 있습니다 (예: HyperTransport 분석의 "amd64htcpu" 스크립트).
모든 조합에 대해 반복하고 각 지표를 가져오기 위한 지침을 포함하십시오. 약 30개의 지표 목록이 만들어질 것이며, 그중 일부는 측정이 불가능하고 일부는 측정이 까다로울 것입니다. 다행히 가장 일반적인 문제들은 보통 쉬운 지표들(예: CPU 포화도, 메모리 용량 포화도, 네트워크 인터페이스 활용도, 디스크 활용도)에서 발견되므로 이를 먼저 확인할 수 있습니다.
Linux, Solaris, Mac OS X, FreeBSD 등에 대한 예시 체크리스트는 이 페이지 상단을 참조하십시오.
실무에서 (In Practice)
OS의 모든 조합에 대한 지표를 읽는 것은 매우 시간이 많이 걸릴 수 있으며, 특히 버스 및 상호 연결 지표를 다루기 시작하면 더욱 그렇습니다. CPU, 메모리 용량, 스토리지 용량, 스토리지 장치 I/O, 네트워크 인터페이스와 같은 하위 집합만 확인할 시간이 있을 수도 있습니다. 이것만으로도 생각보다 괜찮습니다! USE 방법론은 여러분이 확인하지 않은 것이 무엇인지 인지하게 해주었습니다. 한때는 '모른다는 사실조차 몰랐던 것(unknown-unknowns)'들이 이제는 '모른다는 것을 아는 것(known-unknowns)'이 되었습니다. 그리고 회사가 성능 문제의 근본 원인을 파악해야 하는 중요한 순간이 오면, 더 철저한 분석을 위해 수행할 수 있는 추가 작업 목록을 이미 갖게 된 것이며, 정말 필요할 때 USE 방법론을 완성할 수 있습니다.
USE 방법론을 더 쉽게 만들기 위해 OS에 더 많은 지표가 추가됨에 따라, 확인하기 쉬운 지표의 하위 집합이 시간이 지남에 따라 늘어나기를 바랍니다. 성능 모니터링 소프트웨어 또한 USE 방법론 마법사를 추가하여 작업을 대신 해줌으로써 도움을 줄 수 있습니다.
소프트웨어 리소스 (Software Resources)
일부 소프트웨어 리소스도 비슷한 방식으로 고려될 수 있습니다. 이는 보통 전체 애플리케이션이 아닌 소프트웨어의 작은 구성 요소에 적용됩니다. 예를 들어:
- 뮤텍스 락(mutex locks): 활용도는 락을 보유한 시간으로, 포화도는 락을 기다리며 큐에 대기 중인 스레드로 정의할 수 있습니다.
- 스레드 풀(thread pools): 활용도는 스레드가 작업을 처리하느라 바빴던 시간으로, 포화도는 스레드 풀에 의해 서비스되기를 기다리는 요청의 수로 정의할 수 있습니다.
- 프로세스/스레드 용량: 시스템은 프로세스나 스레드의 수가 제한되어 있을 수 있으며, 현재 사용량을 활용도로 정의할 수 있습니다. 할당 대기는 포화도가 될 수 있고, 할당 실패(예: "cannot fork")는 에러가 됩니다.
- 파일 디스크립터(file descriptor) 용량: 위와 비슷하지만 파일 디스크립터에 대한 것입니다.
이런 유형에 너무 매달리지 마십시오. 지표가 잘 작동한다면 사용하고, 그렇지 않다면 소프트웨어는 다른 방법론(예: 지연 시간)에 맡겨둘 수 있습니다.
권장 해석 (Suggested Interpretations)
USE 방법론은 어떤 지표를 사용할지 식별하는 데 도움을 줍니다. 운영체제에서 지표를 읽는 방법을 배운 후, 다음 과제는 현재 값을 해석하는 것입니다. 어떤 지표는 해석이 명확(하고 문서화가 잘 되어)할 수 있습니다. 다른 지표들은 그렇지 않을 수 있으며, 워크로드 요구 사항이나 기대치에 따라 달라질 수 있습니다.
다음은 지표 유형 해석에 대한 몇 가지 일반적인 제안입니다:
- 활용도: 100% 활용도는 대개 병목 현상의 신호입니다 (포화도와 그 영향을 확인하여 확증하십시오). 높은 활용도(예: 70% 이상)는 다음과 같은 몇 가지 이유로 문제가 되기 시작할 수 있습니다:
- 활용도가 비교적 긴 시간(수 초 또는 수 분) 동안 측정될 때, 예를 들어 70%의 전체 활용도는 짧은 순간의 100% 활용도를 숨길 수 있습니다.
- 하드 디스크와 같은 일부 시스템 리소스는 더 높은 우선순위의 작업이 있더라도 작업 중에 중단될 수 없습니다. 활용도가 70%를 넘으면 큐잉 지연이 더 빈번해지고 눈에 띄게 나타날 수 있습니다. 거의 언제든지 중단("선점(preempted)")될 수 있는 CPU와 비교해 보십시오.
- 포화도: 어떤 정도의 포화도든 문제가 될 수 있습니다(0이 아님). 이는 대기 큐의 길이나 큐에서 대기하며 보낸 시간으로 측정될 수 있습니다.
- 에러: 0이 아닌 에러 카운터는 조사할 가치가 있으며, 특히 성능이 좋지 않은 동안 계속 증가하고 있다면 더욱 그렇습니다.
부정적인 사례를 해석하는 것은 쉽습니다: 낮은 활용도, 포화도 없음, 에러 없음. 이는 생각보다 유용합니다. 조사 범위를 좁히면 문제 영역에 빠르게 집중할 수 있기 때문입니다.
클라우드 컴퓨팅 (Cloud Computing)
클라우드 컴퓨팅 환경에서는 한 시스템을 공유하는 테넌트(tenant)를 제한하거나 조절하기 위해 소프트웨어 리소스 제어가 적용될 수 있습니다. 여기에는 메모리, CPU, 네트워크 및 스토리지 I/O에 대한 하이퍼바이저 또는 컨테이너(cgroup) 제한이 포함될 수 있습니다. 외부 하드웨어가 네트워크 처리량 등에 제한을 둘 수도 있습니다. 이러한 각 리소스 제한은 물리적 리소스를 조사하는 것과 유사하게 USE 방법론으로 검사할 수 있습니다.
예를 들어, 우리의 환경에서 "메모리 용량 활용도"는 테넌트의 메모리 사용량 대 메모리 캡(cap)이 될 수 있습니다. "메모리 용량 포화도"는 전통적인 Unix 페이지 스캐너가 유휴 상태이더라도 익명 페이징 활동을 통해 확인할 수 있습니다.
전략 (Strategy)
USE 방법론은 아래 순서도와 같이 시각화할 수 있습니다. 에러는 활용도와 포화도보다 먼저 확인할 수 있는데, 이는 사소한 최적화입니다(에러는 보통 해석하기가 더 빠르고 쉽습니다).
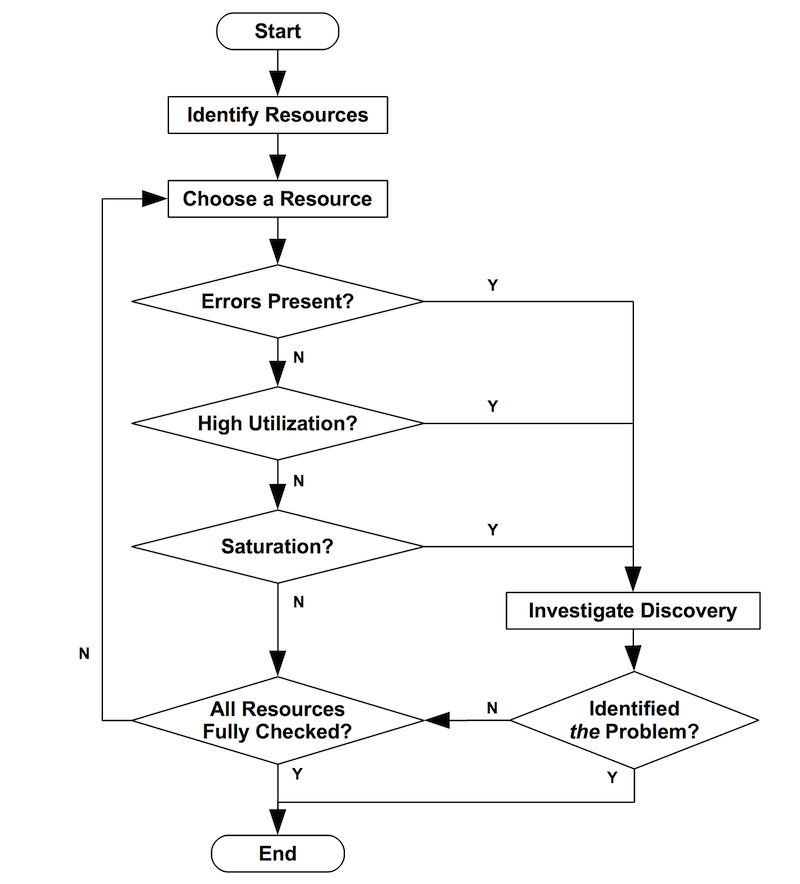
USE 방법론은 시스템 병목 현상일 가능성이 높은 문제를 식별합니다. 불행히도 시스템은 하나 이상의 성능 문제를 겪고 있을 수 있으므로, 처음 발견한 것이 하나의 문제일 수는 있어도 유일한 원인이 아닐 수도 있습니다. 각 발견 사항은 추가 방법론을 사용하여 조사할 수 있으며, 필요한 경우 더 많은 리소스를 반복 확인하기 위해 USE 방법론을 계속 진행할 수 있습니다.
추가 분석을 위한 전략으로는 워크로드 특성 분석(workload characterization)과 드릴다운 분석(drill-down analysis)이 있습니다. 이를 완료하면(필요한 경우), 수정 조치가 적용된 부하를 조정하는 것인지 아니면 리소스 자체를 튜닝하는 것인지에 대한 증거를 확보할 수 있습니다.
아폴로 (Apollo)
앞서 USE 방법론을 서버 이외의 분야에도 적용할 수 있다고 말씀드렸습니다. 재미있는 예시를 찾다가, 제가 전혀 전문 지식이 없고 어디서부터 시작해야 할지 모르는 시스템인 아폴로 달 착륙선(Lunar Module) 유도 시스템을 떠올렸습니다. USE 방법론은 시도해 볼 수 있는 간단한 절차를 제공합니다.
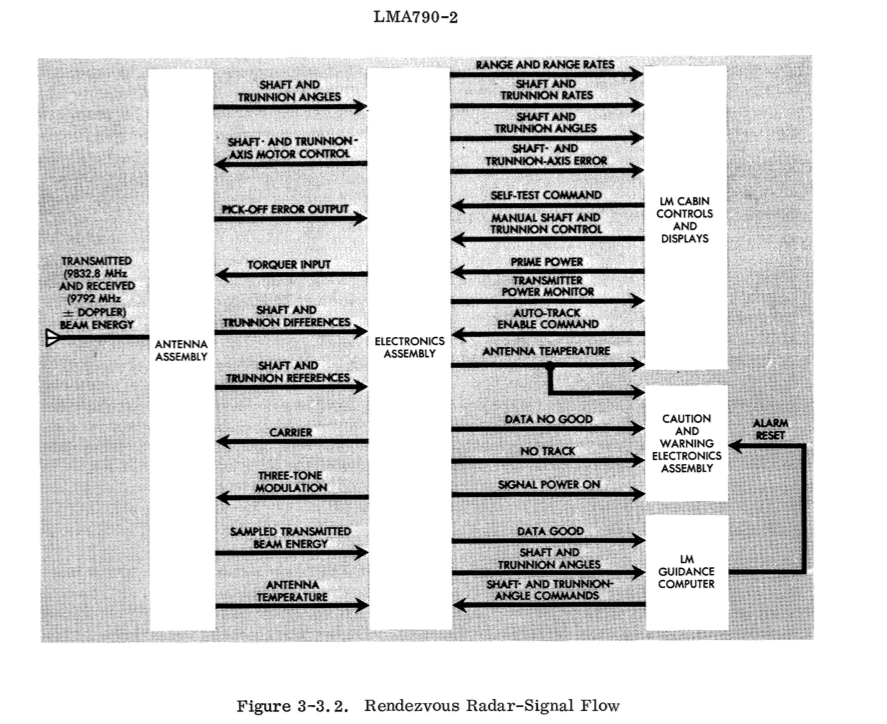
첫 번째 단계는 리소스 목록이나 더 좋은 기능 블록 다이어그램을 찾는 것입니다. "Lunar Module - LM10 Through LM14 Familiarization Manual" (1969)에서 다음을 찾았습니다:
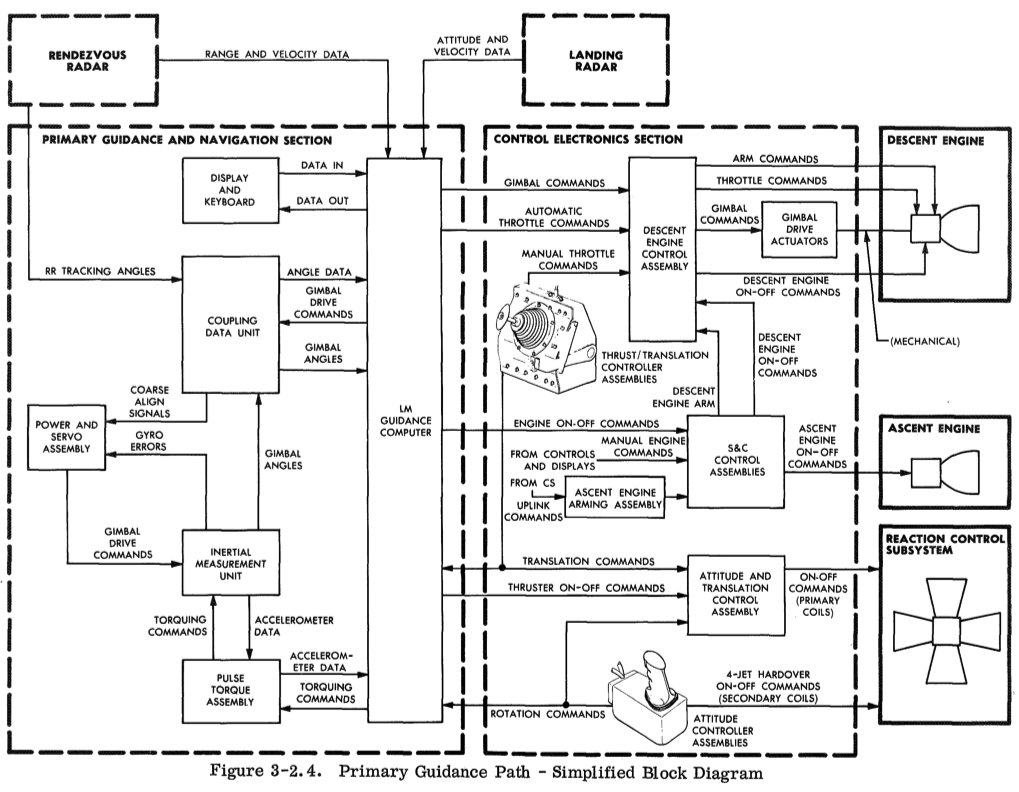
이러한 구성 요소 중 일부는 활용도나 포화도 특성을 나타내지 않을 수도 있습니다. 이를 반복 확인한 후 관련 구성 요소만 포함하도록 다시 그릴 수 있습니다. (우리는 메모리의 "erasable storage" 섹션, "core set area", "vac area" 레지스터 등도 더 포함할 것입니다.)
아폴로 유도 컴퓨터(AGC) 자체부터 시작하겠습니다. 각 지표에 대해 어떤 것이 타당할지 여러 LM 문서를 훑어보았습니다:
- AGC 활용도: 이는 작업을 수행하는 CPU 사이클 수("DUMMY JOB" 제외)를 클록 속도(2.048 MHz)로 나눈 값으로 정의할 수 있습니다. 이 지표는 당시에도 잘 이해되었던 것으로 보입니다.
- AGC 포화도: 이는 프로그램 상태를 저장하기 위한 7개의 레지스터 세트인 "core set area"에 있는 작업 수로 정의할 수 있습니다. 이를 통해 더 높은 우선순위의 작업에 대한 인터럽트가 도착하면 작업이 중단될 수 있습니다(요즘의 "커널"이라 부르는 "EXECUTIVE" 프로그램에 의해). 이것이 고갈되면 포화 상태에서 에러 상태로 넘어가고, AGC는 1202 "EXECUTIVE OVERFLOW-NO CORE SETS" 알람을 보고합니다.
- AGC 에러: 많은 알람이 정의되어 있습니다. 1202 외에도 1203 알람 "WAITLIST OVERFLOW-TOO MANY TASKS"가 있는데, 이는 다른 유형의 성능 문제입니다. 일반 작업 스케줄링으로 돌아가기 전에 너무 많은 타이머 작업이 처리되고 있는 것입니다. 1202와 마찬가지로, WAITLIST의 길이를 포화도 지표로 정의하여 오버플로우와 에러가 발생하기 전에 포화도를 측정할 수 있다면 유용할 것입니다.
이러한 세부 사항 중 일부는 우주 팬들에게 익숙할 수 있습니다. 1201("NO VAC AREAS")과 1202 알람은 아폴로 11호 하강 중에 발생한 것으로 유명합니다. ("VAC"는 벡터 수량을 처리하는 작업을 위한 추가 저장소인 "vector accumulator"의 약자입니다. 위키피디아의 "vacant"라는 설명은 틀린 것 같습니다.)
아폴로 11호의 1201 알람이 발생했을 때, 워크로드 특성 분석과 같은 다른 방법론을 사용하여 분석을 계속할 수 있습니다. 워크로드는 주로 인터럽트를 통해 가해지며, 그중 많은 것들이 기능 다이어그램에서 확인됩니다. 여기에는 사령선(Command Module)을 추적하는 데 사용되는 랑데부 레이더가 포함되는데, 이 레이더는 착륙선이 하강 중임에도 불구하고 AGC에 인터럽트를 걸어 작업을 시키고 있었습니다. 이는 불필요한 작업(또는 낮은 우선순위 작업; 착륙선 AGC가 필요한 경우 즉시 중단 궤도와 사령선 랑데부를 계산할 수 있도록 레이더의 일부 업데이트가 바람직했을 수도 있음)을 찾아낸 사례입니다.
더 어려운 예로, 랑데부 레이더를 리소스로 검사해 보겠습니다. 에러는 식별하기 가장 쉽습니다. "DATA NO GOOD", "NO TRACK", "SHAFT- AND TRUNNION-AXIS ERROR" 신호의 세 가지 유형이 있습니다. 활용도는 더 어렵습니다. 한 가지 유형은 구동 모터의 활용도일 수 있는데, 이는 각도 명령에 응답하느라 바빴던 시간으로 정의됩니다(기능 다이어그램의 "COUPLING DATA UNIT"을 통해 확인 가능). 구동 모터나 반환된 레이더 데이터에 포화도 특성이 있는지 확인하려면 LM 문서를 더 읽어봐야 할 것입니다.
짧은 시간 안에 이 방법론을 사용하여, 어디서부터 시작해야 할지 전혀 모르던 상태에서 연구하고 찾아야 할 구체적인 지표를 갖게 되었습니다.
다른 방법론들 (Other Methodologies)
USE 방법론이 서버 문제의 80%를 찾을 수 있는 반면, 지연 시간 기반 방법론(예: Method R)은 모든 문제의 100%를 찾는 데 접근할 수 있습니다. 그러나 소프트웨어 내부 구조에 익숙하지 않다면 이러한 방법은 훨씬 더 많은 시간이 걸릴 수 있습니다. 이러한 방법은 이미 내부 구조에 익숙한 데이터베이스 관리자나 애플리케이션 개발자에게 더 적합할 수 있습니다. USE 방법론은 운영체제(OS)와 하드웨어를 책임지고 전문 지식을 갖춘 주니어 또는 시니어 시스템 관리자에게 더 적합합니다. 또한 시스템 상태를 빠르게 확인하고자 할 때 다른 직원들도 이 방법론을 채택할 수 있습니다.
도구 방법론 (Tools Method)
USE 방법론과 비교하기 위해 도구 기반 접근 방식(이를 "도구 방법론"이라 부르겠습니다)을 설명하겠습니다:
- 사용 가능한 성능 도구를 나열합니다 (선택적으로 더 설치하거나 구매합니다).
- 각 도구에 대해 제공하는 유용한 지표를 나열합니다.
- 각 지표에 대해 가능한 해석 규칙을 나열합니다.
이 결과는 어떤 도구를 실행하고, 어떤 지표를 읽으며, 어떻게 해석해야 하는지를 보여주는 처방적인 체크리스트가 됩니다. 이것이 꽤 효과적일 수는 있지만, 한 가지 문제는 사용 가능하거나 알려진 도구에만 전적으로 의존한다는 점입니다. 이는 시스템에 대한 불완전한 시야를 제공할 수 있습니다. 사용자는 자신이 불완전한 시야를 가지고 있다는 사실조차 인지하지 못하며, 따라서 문제는 해결되지 않은 채로 남게 됩니다.
반면 USE 방법론은 시스템 리소스를 반복 확인하여 질문할 전체 목록을 만든 다음, 그에 대한 답을 줄 도구를 찾습니다. 더 완전한 시야가 구축되고, 알지 못하는 영역은 문서화되어 그 존재를 알게 됩니다("알려진 미지수"). USE를 기반으로 어떤 도구를 실행할지(가능한 경우), 어떤 지표를 읽을지, 어떻게 해석할지를 보여주는 유사한 체크리스트를 개발할 수 있습니다.
또 다른 문제는 수많은 도구를 훑어보는 것이 병목 현상을 찾는다는 목표를 흐트러뜨릴 수 있다는 점입니다. USE 방법론은 다루기 힘들 정도로 많은 도구와 지표가 있더라도 병목 현상과 에러를 효율적으로 찾을 수 있는 전략을 제공합니다.
결론 (Conclusion)
USE 방법론은 시스템 상태를 완벽하게 점검하고 일반적인 병목 현상과 에러를 식별하기 위해 사용할 수 있는 간단한 전략입니다. 조사의 초기 단계에 도입하여 문제 영역을 신속하게 식별할 수 있으며, 필요한 경우 다른 방법론을 통해 더 자세히 연구할 수 있습니다. USE의 강점은 속도와 가시성입니다. 모든 리소스를 고려함으로써 문제를 간과할 가능성이 낮아집니다. 하지만 이 방법론은 특정 유형의 문제(병목 현상과 에러)만 찾아내므로, 더 큰 도구 상자의 도구 중 하나로 간주해야 합니다.
이 페이지에서 USE 방법론을 설명하고 지표의 일반적인 예시를 제공했습니다. USE 방법론을 적용하기 위한 도구와 지표가 제안된 특정 운영체제별 예시 체크리스트는 왼쪽 탐색 창을 참조하십시오.
감사의 말 (Acknowledgments)
- Cary Millsap과 Jeff Holt의 "Optimizing Oracle Performance" (2003)는 Method R(및 기타 방법론)을 설명하고 있으며, 최근 제가 이 방법론을 기록해야겠다고 생각나게 해주었습니다.
- PAE 및 ISV를 포함한 Sun Microsystems의 그룹들은 스토리지 어플라이언스 시리즈에 (이름 붙여지기 전의) USE 방법론을 적용하는 데 도움을 주었습니다. 우리는 지표 이름과 버스 속도가 표시된 ASCII 기능 블록 다이어그램을 그렸는데, 이는 생각보다 구성하기 어려웠습니다 (하드웨어 팀에 더 빨리 도움을 요청했어야 했습니다).
- 수년 전 성능 수업을 들었던 학생들은 제가 이 방법론을 가르쳤을 때 피드백을 주었습니다.
- Virtual AGC 프로젝트는 ibiblio.org에서 호스팅하는 문서 라이브러리를 읽는 동안 즐거운 소일거리가 되었습니다. 특히 LMA790-2 "Lunar Module LM-10 Through LM-14 Vehicle Familiarization Manual" (48페이지에 기능 블록 다이어그램이 있음)과 순서도를 포함하여 EXECUTIVE 프로그램에 대한 좋은 설명이 담긴 "Apollo Guidance and Navigation Lunar Module Student Study Guide"가 도움이 되었습니다. (이 문서들은 크기가 109MB와 9MB에 달합니다.)
- Deirdré Straughan은 편집과 피드백을 통해 제 설명을 개선해 주었습니다.
- 이 포스트 상단의 이미지는 1969년에 인쇄된 보잉 707 비행 매뉴얼에서 가져온 것입니다. 이것은 (당연히) 구식이며 참고용으로 사용해서는 안 됩니다. 이미지를 클릭하면 전체 페이지를 볼 수 있습니다.
업데이트 (Updates)
USE 방법론 업데이트:
- ACMQ에 Thinking Methodically about Performance (2012)로 게재되었습니다.
- Communications of the ACM에 Thinking Methodically about Performance (2013)로 게재되었습니다.
- FISL13 강연 The USE Method (2012)에서 발표했습니다.
- USENIX LISA '12 강연 Performance Analysis Methodology에 포함되었습니다.
- Prentice Hall에서 출판된 저의 저서 Systems Performance (2013)에서 다루고 있습니다.
추가 업데이트 (2014년 4월):
- MacIT 2014에서 OS X를 위한 USE 방법론에 대해 발표했습니다 (슬라이드).
추가 업데이트 (2017년 8월):
- Heinrich Hartmann이 System Monitoring with the USE Dashboard를 게시하여 Circonus 모니터링 제품에서 USE 방법론 대시보드가 어떻게 구현되었는지 보여주었습니다.
0
13
댓글
?
아직 댓글이 없습니다.
첫 번째 댓글을 작성해보세요!
Beomsu Son님의 다른 글
더보기
번역
RED 메서드: 서비스 계측 방법
Beomsu Son • Back-End
0
0
6
게임 서버 프레임워크 Pomelo: 디자인 모티베이션
Beomsu Son • Back-End
2
0
67
Event-Driven Architecture - System Design
Beomsu Son • Back-End
2
0
56
{kind=link}
{kind=link}