[번역] Apple, 퓨전(Fusion)을 선보이다.
A
anotherminor
Computer Science•2026.03.06
Om Malik - 2026-03-04T02:07:16+00:00
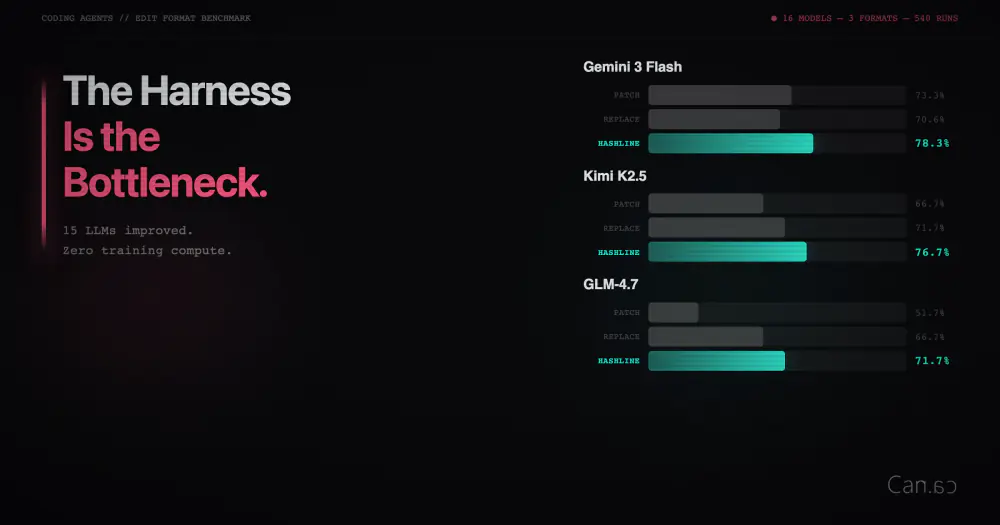
Apple Silicon 5세대 역사상 처음으로, 이 칩들은 단일 실리콘 조각이 아닙니다. 최근 발표된 M5 Pro와 M5 Max는 Apple이 '퓨전 아키텍처(Fusion Architecture)'라고 부르는 기술을 사용합니다. 이는 장기적인 함의를 지닌 거대한 구조적 변화입니다. 그리고 우리는 새로 발표된 Apple의 플래그십 노트북에서 이 기술이 작동하는 모습을 볼 수 있습니다. 겉으로 보기에 이 칩들은 두 개의 3세대 3나노미터(nm) 다이(die)를 하나의 시스템 온 칩(SoC)으로 결합한 형태입니다. 하지만 더 깊이 들여다보면, 이러한 모듈식의 확장 가능한 실리콘 접근 방식을 통해 Apple은 AI 미래의 컴퓨팅 수요로부터 수익을 창출할 준비를 마쳤음을 알 수 있습니다.
오늘 Apple이 출시한 제품을 이해하려면, Apple이 2020년 11월 M1을 출시했던 5년 전으로 거슬러 올라가야 합니다. 당시 저는 이렇게 썼습니다.
"단일 칩으로의 통합, 최대 처리량, 메모리에 대한 신속한 액세스, 작업에 따른 최적의 컴퓨팅 성능, 그리고 머신러닝(Machine Learning) 알고리즘에 대한 적응이라는 이 접근 방식은 모바일 칩뿐만 아니라 데스크톱과 노트북 컴퓨터의 미래이기도 합니다."
이 예측은 적중했습니다. 업계의 나머지 기업들도 이 새로운 접근 방식을 받아들였습니다. Qualcomm은 Snapdragon X를 만들었고, AMD는 노트북 칩의 구조를 재편했습니다. Intel조차 아키텍처를 완전히 개편했습니다. M1은 단순히 Apple을 바꾼 것이 아니라, 칩이 구상되고 제작되는 방식 자체를 바꾸어 놓았습니다.
그렇다면 퓨전 아키텍처에 대한 자연스러운 질문은 이것입니다. Apple이 다시 한번 혁신을 일으키고 있는가? 이것이 Apple이 업계의 방향을 다시 설정하는 또 다른 순간인가? 솔직한 대답은 '아니오'입니다. 하지만 그렇다고 해서 이 기술이 흥미롭지 않다는 뜻은 아닙니다.
수년 동안 Apple의 'M 시리즈' 칩에 대한 서사는 '통합'에 관한 것이었습니다. 하나의 칩, 하나의 다이. 모든 것이 동일한 실리콘 조각 위에 놓여 있었습니다. CPU, GPU, Neural Engine이 데이터를 복사하지 않고도 동일한 데이터에 액세스할 수 있는 통합 메모리(Unified Memory) 구조였습니다. 이는 M1과 M2에서 아름답게 작동했습니다. 하지만 이제 AI의 부상과 함께 칩은 더 커져야만 합니다. AI는 더 많은 코어, 더 넓은 메모리 대역폭, 더 높은 연산 능력을 요구합니다. 따라서 하나의 거대하고 육중한 칩을 만드는 것은 비용이 매우 많이 들게 됩니다.
단일 다이가 커질수록 제조는 더 어려워집니다. 실리콘 어디에서든 아주 작은 결함 하나만 발생해도 전체를 폐기해야 합니다. 수율(Yield)은 떨어지고 비용은 치솟습니다. AMD의 CEO 리사 수(Lisa Su)는 최근 네 개의 작은 칩렛(chiplet)을 사용한 설계가 하나의 큰 칩을 만드는 비용의 59%만으로도 더 높은 총체적 역량을 제공한다는 것을 보여주었습니다.
Apple 역시 선택의 기로에 섰습니다. 점점 더 큰 단일 칩을 계속 만들 것인가, 아니면 큰 칩을 작은 조각으로 나누고 소프트웨어가 그 분할을 거의 알아채지 못할 정도로 빠르게 연결할 것인가. 그들은 두 번째 옵션을 선택했고, 이를 자신들만의 방식으로 완성했습니다. 그들은 이를 '퓨전 아키텍처'라고 부릅니다.
이것은 업계에서 새로운 개념은 아닙니다. AMD는 수년 동안 Ryzen과 EPYC 라인업에서 칩렛 전략을 사용해 왔습니다. Intel은 3D 적층(stacking)과 브리지 인터커넥트(bridge interconnect) 기술을 사용해 왔습니다. Nvidia는 멀티 다이 패키징을 사용하여 거대한 AI 가속기를 구축합니다. 칩렛 시장은 현재 연간 약 400억 달러 규모에 달하며, 거의 모든 데이터 센터용 AI 제품이 이 방식으로 제작됩니다. 거대한 단일 구조(Monolithic) 다이의 시대가 저물고 있습니다. 칩 전문가들은 미래가 모듈식 실리콘에 있다는 점에 동의합니다.
이러한 접근 방식에는 트레이드오프(tradeoff)가 따릅니다. 칩을 조각으로 나누면 그 조각들이 서로 통신해야 합니다. 이는 다이 사이를 데이터가 이동해야 함을 의미하며, 이는 지연 시간(latency)을 유발합니다. 메모리는 칩렛 간에 나뉘게 됩니다. 제조 문제는 해결되지만 아키텍처 측면에서는 타협이 발생하는 것입니다. Apple은 이를 자신들만의 방식으로 해결하기로 했습니다.
수년 동안 Apple의 실리콘 개발을 이끌어온 조니 스루지(Johny Srouji)는 Apple이 통합 메모리 구조를 그대로 유지했다고 말합니다. 그는 보도 자료에서 퓨전 아키텍처가 "성능, 전력 효율성, 통합 메모리 아키텍처라는 핵심 원칙을 유지하면서 Apple 실리콘의 역량을 확장할 것"이라고 밝혔습니다. Apple은 두 다이 모두에서 통합 메모리가 보존된다고 말하지만, 메모리가 단일 다이와 비교하여 두 개의 다이에서 실제로 어떻게 작동하는지에 대한 기술적 세부 사항은 명시되지 않았습니다.
이는 Apple이 M1 Ultra와 M2 Ultra에서 취했던 'UltraFusion' 방식과는 다릅니다. 당시에는 동일한 칩을 복제하여 두 개를 이어 붙였습니다. 하지만 퓨전 아키텍처에서 두 다이는 기능적으로 서로 다릅니다. Ars Technica의 M5 Pro 및 M5 Max 칩 분석은 새로운 모듈형 퓨전 아키텍처가 어떻게 작동하는지에 대한 힌트를 제공합니다.
M5 Pro와 M5 Max는 첫 번째 다이를 공유합니다. 이 다이는 18코어 CPU, 16코어 Neural Engine, SSD 컨트롤러, 그리고 Thunderbolt 포트를 담당합니다. 두 칩이 달라지는 지점은 두 번째 다이입니다. M5 Pro는 최대 20개의 GPU 코어, 단일 미디어 엔진, 그리고 최대 307GB/s 대역폭의 메모리 컨트롤러를 갖습니다. M5 Max는 최대 40개의 GPU 코어, 두 개의 미디어 엔진, 그리고 최대 614GB/s의 대역폭을 갖습니다. 따라서 미래에 Apple은 두 번째 다이를 하나가 아닌 두 개를 탑재하여 AI 성능을 더욱 강화한 새로운 M 칩을 만들 수도 있을 것입니다.
스루지는 2020년에 저에게 이렇게 말했습니다.
"우리는 제품과 소프트웨어가 이를 어떻게 사용할지에 완벽하게 부합하는 맞춤형 실리콘을 개발하고 있습니다. 우리가 3~4년 앞을 내다보고 칩을 설계할 때, 크레이그(Craig Federighi)와 저는 같은 방에 앉아 우리가 무엇을 제공하고 싶은지 정의하고 손을 맞잡고 일합니다. Intel이나 AMD, 혹은 그 누구도 이런 방식으로는 할 수 없습니다."
M1이 혁명이었다면, M2, M3, M4는 정교화의 과정이었습니다. 각 세대는 코어를 추가하고, 대역폭을 높이며, 공정 노드에서 더 많은 것을 쥐어짜 냈습니다. M5는 다릅니다. 이는 원래의 M1 아이디어가 오늘날과 미래의 칩 제조 방식의 근본적인 변화 속에서도 살아남을 만큼 견고하다는 첫 번째 증거입니다. 새로운 설계의 역량이 이를 반영합니다.
예를 들어, 코어 수는 변하지 않았지만 Apple은 모든 GPU 코어 내부에 '뉴럴 액셀러레이터(Neural Accelerator)'를 탑재했습니다. M5 Pro는 여전히 20개의 GPU 코어를, M5 Max는 40개를 가지고 있습니다. M4와 동일합니다. 하지만 이제 각 코어는 두 가지 역할을 수행합니다. 이것이 바로 Apple이 실리콘을 추가하지 않고도 AI 연산 능력을 4배 향상했다고 주장하는 비결입니다. GPU가 때때로 그래픽 작업을 수행하는 AI 프로세서가 되어가고 있는 것입니다.
메모리 대역폭도 계속해서 높아지고 있습니다. M5 Max는 M4 Max의 546GB/s에서 증가한 614GB/s에 도달했습니다. M5 Pro는 M4 Pro의 273GB/s에서 증가한 307GB/s에 도달했습니다. 이 수치는 대규모 언어 모델(LLM)을 로컬에서 실행하는 데 있어 가장 중요한 지표입니다. Apple은 노트북에서 700억 개의 파라미터(70B) 모델을 실행하는 세상을 위해 이 칩들을 만들고 있습니다.
CPU 또한 기존 방식에서 벗어났습니다. M5 Pro와 M5 Max는 효율 코어(Efficiency core)를 완전히 제거했습니다. 처음으로 Apple의 프로급 칩이 '올 빅 코어(all-big-core)' 설계로 제작된 것입니다. 최상단에는 6개의 '슈퍼 코어(super cores)'가 피크 싱글 스레드 성능을 담당합니다. 그 아래에는 멀티 스레드 처리량에 최적화된 12개의 새로운 성능 코어(Performance cores)가 배치되었습니다. 존 그루버(John Gruber)가 언급했듯이, 명칭이 다소 혼란스럽습니다. Apple이 M1부터 M4까지 '성능' 코어라고 불렀던 것들이 이제는 '슈퍼 코어'가 되었습니다. 새로운 '성능' 코어는 이전에는 존재하지 않았던 중간 계층의 완전히 새로운 설계입니다. 참고로, 이러한 접근 방식은 AMD의 Zen 5 및 Zen 5c 코어 전략과 매우 유사합니다.
이것이 제가 퓨전 아키텍처가 이번 발표의 진짜 핵심이라고 생각하는 이유입니다.
M5 Pro와 M5 Max가 오늘 당장 무엇을 할 수 있기 때문이 아닙니다. 이 기술이 열어줄 가능성 때문입니다. 일단 칩을 분할하고도 조각들 사이에서 통합 메모리가 작동하게 할 수 있음을 증명했다면, 질문은 달라집니다. 이제 질문은 "이 칩을 얼마나 크게 만들 수 있는가?"가 아니라, "얼마나 많은 조각을, 그리고 몇 차원으로 연결할 수 있는가?"가 됩니다.
그리고 이것을 고려해 보십시오. Apple이 이 다이들을 결합하기 위해 사용하는 패키징 기술은 데이터 센터의 AI 서버를 구동하는 것과 동일한 인터커넥트 기술입니다. Apple은 그것을 노트북에 집어넣었습니다.
실리콘 조각 위에 더 많은 트랜지스터를 배치하는 것이 점점 더 어려워지고 있다는 사실은 칩 업계에 잘 알려져 있습니다. Apple은 퓨전 아키텍처를 그 문제에 대한 해답으로 사용하고 있습니다. 물리 법칙과 싸우는 것이 아니라, 그것을 길들이는 영리한 방법을 찾아냄으로써 말입니다.
2026년 3월 3일. 샌프란시스코.
M 칩에 관한 이전 기사들
- "스티브 잡스의 마지막 승부수: Apple의 M1 칩", 2020년 11월 17일.
- "Apple M1 칩에 관한 나의 노트", 2020년 11월 10일.
- "Apple, 새로운 (M2) 칩 출시", 2023년 1월 17일.
- "새로운 M3 칩과 함께 AI 파티에 합류한 Apple", 2023년 10월 30일.
- "M4 칩에 관한 몇 가지 생각들", 2024년 5월 13일.
0
13
댓글
?
아직 댓글이 없습니다.
첫 번째 댓글을 작성해보세요!
anotherminor님의 다른 글
더보기
번역
2028년 글로벌 지능 위기 (THE 2028 GLOBAL INTELLIGENCE CRISIS)
anotherminor • Career
0
0
18

번역
‘안도르’ 제작자 토니 길로이, 방영 당시에는 할 수 없었던 인터뷰를 전하다
anotherminor • Career
0
0
19