[번역] 내가 어떻게 여기까지 왔을까?
N
n-ryu
Computer Science•2025.12.30
female - (날짜 미기재)
위의 traceroute(경로 추적)가 로드되는 동안 페이지의 이 부분은 아직 로딩 중입니다.

비하인드 스토리 (Behind the Scenes)
이 웹사이트에 접속하기 위해, 여러분의 컴퓨터는 인터넷을 통해 몇 개의 패킷(packet)을 보냈습니다. 그 경로가 어떠했는지 궁금하다면, traceroute를 생성하는 도구를 실행해 볼 수 있습니다. 이는 여러분의 패킷이 목적지에 도달하기 위해 거쳐 간 모든 서버의 대략적인 목록입니다. 이 웹사이트(GitHub의 소스 코드)를 만들기 위해, 저는 각 홉(hop)에 대한 흥미로운 정보를 동시에 찾아보면서 실시간으로 결과를 스트리밍할 수 있는 ktr(이 또한 오픈 소스)이라는 저만의 traceroute 프로그램을 작성했습니다.
ktr은 어떻게 작동할까요? 인터넷 라우팅(Routing)에 대한 단순화된 설명부터 시작해 보겠습니다.
소스 장치에서 시작하여, 패킷을 처리하는 각 컴퓨터는 패킷을 전달할 최적의 장치를 선택해야 합니다. 이러한 라우팅 결정이 어떻게 내려지는지는 잠시 후에 설명하겠습니다. 모든 것이 올바르게 작동한다고 가정하면, 패킷은 결국 목적지로 직접 보내는 방법을 아는 라우터에 도달하게 됩니다.
저의 traceroute 구현은 ICMP(인터넷 제어 메시지 프로토콜)라는 프로토콜을 사용합니다. ICMP는 인터넷상에서 진단 정보를 보내기 위해 특별히 설계되었으며, 다행히도 거의 모든 인터넷 연결 장치가 이 프로토콜을 지원합니다. 흥미롭게도 ICMP 패킷에는 "TTL"(Time To Live, 생존 시간) 필드가 있습니다. 이름에서 암시하는 것처럼 실제 "시간"은 아니며, 일종의 카운트다운입니다! 라우터가 ICMP 패킷을 전달할 때마다 TTL 숫자를 1씩 감소시켜야 합니다. TTL이 0이 되면 라우터는 패킷 전달을 중단하고, 대신 패킷의 소스 IP에 패킷이 최대 홉 수에 도달했다는 오류 메시지를 보내야 합니다.
우리는 이 TTL 기능을 활용할 수 있습니다! traceroute를 수행하기 위해, 우리는 점점 더 큰 TTL 값을 가진 ICMP 패킷들을 뭉치로 보낼 수 있습니다. TTL이 1인 첫 번째 패킷은 도달하는 첫 번째 장치에서 오류가 발생할 것이고, 이런 식으로 패킷을 거친 모든 라우팅 장치로부터 오류를 돌려받을 때까지 계속됩니다. 이 오류 패킷에는 오류를 보낸 장치의 IP 주소와 같은 진단 정보가 포함되어 있어, 인터넷을 가로지르는 여러분 패킷의 대략적인 경로를 추적할 수 있게 해줍니다.
프론트엔드의 재미 (Frontend Fun)
이 페이지는 JavaScript를 비활성화해도 완벽하게 작동합니다. 브라우저의 관점에서 보면 이 웹사이트는 그냥 느리게 로드된 것뿐입니다. 여러분의 관점에서는 traceroute가 마법처럼 로드된 것이죠.
여러분이 이 웹사이트를 로드했을 때, 제 프로그램은 여러분의 IP 주소로부터 HTTP 요청을 받았습니다. 프로그램은 즉시 여러분의 IP로 traceroute를 실행하기 시작했습니다. 그런 다음 서버는 HTTP 요청에 응답하기 시작했습니다. 웹 페이지의 시작 부분을 보내고 연결을 열어둔 상태로 유지했습니다. 제 traceroute 프로그램인 ktr이 서버에 traceroute 업데이트를 제공함에 따라, 서버는 관련 HTML을 렌더링하여 여러분의 컴퓨터로 보냈습니다. traceroute가 끝나면 서버는 모든 텍스트를 생성하고 연결을 종료하기 전에 웹사이트의 나머지 부분을 보냈습니다.
traceroute가 맨 아래 줄 위로 줄들이 점진적으로 로드되는 것을 보셨을 수도 있습니다. 웹 페이지는 앞으로만 로드될 수 있습니다. JavaScript를 사용하고 싶지 않았기 때문에, 저는 가능한 가장 "해킹"스러운 방법을 썼습니다. traceroute 표시를 업데이트할 때마다 이전 반복 내용을 숨기는 CSS 블록을 삽입한 것입니다! 브라우저는 페이지가 로드되는 동안 CSS를 렌더링하므로, 마치 traceroute가 시간이 지남에 따라 수정되는 것처럼 보이게 되었습니다.
앞에서 뒤로, 뒤에서 앞으로 (Front to Back, Back to Front)
이 웹사이트의 traceroute가 여러분의 패킷이 제 서버에 도달하기 위해 거친 경로라는 제 주장은 사실 약간의 선의의 거짓말이었습니다. 그것을 계산하려면 여러분의 컴퓨터에서 제 서버로 traceroute를 실행할 수 있어야 했습니다. 대신 저는 제 서버에서 여러분의 컴퓨터로 traceroute를 실행하고 그것을 반전시켰을 뿐입니다. 상단의 traceroute가 겉보기에 역순으로 로드되는 이유이기도 합니다.
"역방향 traceroute"를 실행하면 정확도가 떨어질까요? 사실 조금 그렇습니다.
인터넷 라우팅을 설명할 때 말했듯이, 패킷이 통과하는 각 장치는 최종 목적지에 도달할 때까지 패킷을 다음에 어디로 보낼지 결정합니다. 패킷을 반대 방향으로 보내면 장치들이 다른 라우팅 결정을 내릴 수도 있고... 한 장치가 다른 결정을 내리면 나머지 경로도 확실히 달라질 것입니다.
하지만 이 역방향 traceroute는 여전히 유용합니다. 경로는 대략 비슷할 것이며, 아마도 어떤 특정 라우터가 여러분의 패킷을 보는지 정도만 다를 것입니다.
그래서, 그 네트워크들은 다 무엇인가요?
이 사이트는 여러분이 제 서버에 도달하기 위해 거쳐 온 "네트워크"에 대한 이야기로 시작했습니다. 구체적으로 이 네트워크들은 무엇일까요?
각 네트워크는 자율 시스템(Autonomous System, AS)이라고도 불리며, 서로 사적으로 연결되어 있고 일반적으로 동일한 회사가 소유한 라우터와 서버의 집합입니다. 이러한 자율 시스템의 소유자들은 어떤 다른 자율 시스템과 연결할지 선택함으로써 인터넷의 형태를 결정합니다. 인터넷 트래픽은 서로 "피어링 협약(Peering arrangements)"을 맺은 자율 시스템들을 가로질러 이동합니다.
인터넷은 종종 여러분이나 저 같은 개인이 소유한 컴퓨터와 회사가 소유한 컴퓨터를 연결하는 개방적이고 거의 무정부적인 네트워크로 묘사됩니다. 현실적으로 인터넷은 기업 소유 네트워크들의 네트워크이며, 이에 대한 접근과 통제는 금융 거래에 의해 지배되고 관료주의로 가득 차 있습니다.
자신만의 자율 시스템을 갖고 싶다면, 인터넷 번호를 관리하는 5개의 대륙별 인터넷 등록기관(RIRs) 중 하나에 자율 시스템 번호(ASN)를 신청할 수 있습니다. 주의할 점은, 기업의 지원을 받지 않거나 인터넷상에 충분한 서비스 거점(Points of Presence)이 없다면 그들은 아마 여러분의 말을 듣지 않을 것입니다. 우리가 IP 주소를 사용하여 식별하는 것처럼—
잠깐, IP 주소는 정확히 무엇을 식별하나요? 음... 인터넷 접속이 가능한 장치를 나타낸다고 해두죠.
... 우리가 인터넷 접속 장치를 식별하기 위해 IP 주소를 사용하는 것처럼, 인터넷의 네트워크를 식별하기 위해 ASN을 사용합니다. 시작 부분의 traceroute에 있는 "AS24940"과 같은 숫자들이 바로 그것입니다.
WHOIS에 관한 노트
제가 직접 멋진 traceroute 프로그램을 만든 이유 중 하나는 여러분의 traceroute 경로에 있는 IP를 소유한 자율 시스템 정보를 가져오기 위해서였습니다. 몇몇 조직들이 어떤 AS가 어떤 IP 주소를 포함하고 있는지 추적하려고 노력합니다. 그들 중 다수는 WHOIS 프로토콜을 사용하여 ASN 조회를 수행할 수 있게 해주므로, 제가 임의로 선택한 일부 서버의 응답을 파싱(Parsing)하기 위한 작은 클라이언트를 작성했습니다.
그런 다음 PeeringDB라는 멋진 데이터베이스를 사용하여 ASN 뒤에 있는 회사를 파악했습니다. PeeringDB는 모든 자율 시스템의 약 1/3에 대한 정보를 가지고 있습니다. 저는 이 모든 정보와 수백 줄의 if 문을 사용하여 여러분을 위한 네트워크 이동 텍스트를 생성했습니다.
WHOIS는 사실 파서를 만들기에... 흥미로운 프로토콜입니다. WHOIS 프로토콜 사양은 실제로는 많은 것을 규정하지 않는 것으로 드러났습니다. WHOIS 서버에 TCP 연결을 만들고, 조회하고 싶은 내용을 보내면, 서버가 정보를 보내고 연결을 종료한다는 것만 명시되어 있습니다. 그게 전부입니다.
그럼에도 불구하고 많은 WHOIS 서버는 구조화된 것처럼 보이는 정보로 응답합니다.
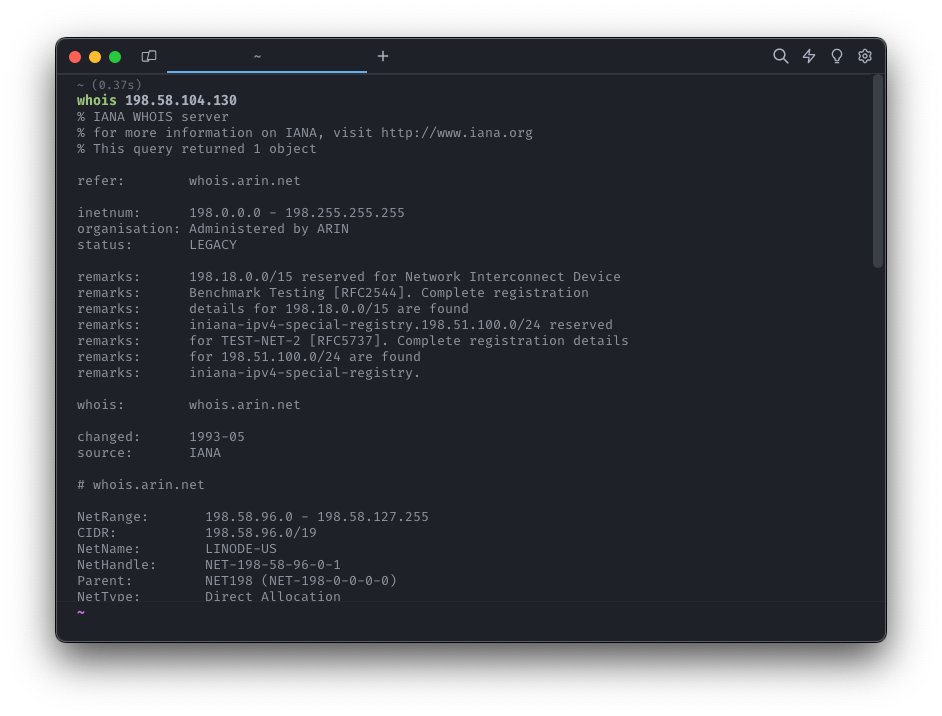
이 구조는 WHOIS 서버 관리자가 만든 것이며, 서버들 사이에 공유되는 몇 가지 관행이 있을 뿐인 것으로 밝혀졌습니다. 구조화되어 있음에도 불구하고, 원하는 필드가 다른 이름(origin? originas?)으로 나타나거나 심지어 여러 곳에 동시에 나타나기도 합니다.
저의 "파서"는 결국 파서라기보다는 인간인 제가 필요한 ASN을 찾기 위해 WHOIS 결과를 읽는 방식을 흉내 낸 가벼운 시뮬레이터에 가깝게 되었습니다.
BGP
인터넷을 통해 패킷을 보낼 때, 이러한 네트워크들이 연결되는 경계에 있는 라우터들은 패킷이 목적지 장치를 포함하는 네트워크에 도달할 때까지 다음에 어느 네트워크로 보낼지 결정합니다.
이러한 경계 라우터들은 경계 경로 프로토콜(Border Gateway Protocol, BGP)이라는 프로토콜을 사용하여 자신들이 연결할 수 있는 네트워크에 대해 서로 대화합니다.
역사 시간 (History Time)
닐 암스트롱이 달에 착륙한 것과 같은 해인 1969년, ARPANET의 프로토타입에서 메시지가 (부분적으로) 전송되었습니다. 이후 20년 동안 이 "상호 연결된 컴퓨터 네트워크"라는 것은 꽤 인기를 얻었고 모두가 그 흐름에 동참하고 싶어 했습니다. 다양한 대학, 정부 기관, 그리고 몇몇 무작위 회사들이 좌우로 자신들의 컴퓨터 네트워크를 만들기 시작했습니다.
이들 조직 중 몇몇은 데이터를 더 쉽게 공유하기 위해 네트워크를 서로 연결하기 시작했습니다. 우리가 아는 인터넷은 아직 존재하지 않았지만, 이러한 네트워크 상호 연결은 걷잡을 수 없이 늘어났고 이를 조정하기 위한 훌륭한 표준이 없었습니다. 1989년, Cisco와 IBM의 엔지니어들은 최초의 BGP 버전을 설명하는 RFC 1105를 발표했습니다.
그 후 몇 년 동안 "인터넷"이 급격히 현실화되면서 상호 연결된 네트워크 사람들은 매우 바빠졌습니다. BGP v1 RFC가 나온 지 불과 1년 만에 Cisco는 상장하여 네트워킹 산업에 막대한 자금을 끌어들였고, "IANA"라는 용어는 인터넷의 번호를 추적하던 어떤 사람과 그의 대학 학과를 지칭하기 위해 처음 사용되었으며, ARPANET은 영구히 폐쇄되었고, BGP v2가 출시되었습니다.
1994년, 인터넷의 광풍이 잦아들기 시작할 무렵, BGP의 마지막 주요 버전인 v4가 RFC 1654에서 규정되었습니다. 이는 두 번 개정되었고(1995년 및 2006년) 몇 가지 패치가 이루어졌지만, BGP v4는 현대 인터넷을 구성하는 상호 연결된 네트워크 전반에서 경로를 선택하기 위해 우리가 여전히 사용하는 프로토콜입니다.
이 BGP라는 것은 어떻게 작동하나요?
자율 시스템 간의 경계에 있는 라우터("경계 게이트웨이")는 *라우팅 테이블(Routing table)*이라고 불리는, 자신들이 알고 있는 모든 BGP 경로 목록을 유지합니다. 각 BGP 경로는 특정 IP 주소 집합을 제어하는 자율 시스템에 도달하기 위해 따라갈 수 있는 ASN들의 경로를 명시합니다.
인터넷을 가로지르는 이러한 경로들은 자율 시스템 간의 *피어링 관계(Peering relationships)*에 의해 형성됩니다. 두 자율 시스템의 경계 게이트웨이가 피어링을 맺을 때, 그들은 일반적으로 다음에 동의합니다:
- 두 라우터 간에 트래픽이 이동할 수 있도록 허용합니다. 즉, BGP 경로가 두 AS 간에 직접 연결될 수 있음을 의미합니다.
- 자신들이 알고 있는 BGP 경로에 대해 서로 최신 상태를 유지합니다.
예시 시간입니다! AS0001의 라우터 A가 AS0002의 라우터 B와 물리적으로 연결되어 있고 서로 피어링을 맺고 싶어 합니다. 그들은 서로 BGP 메시지를 보내 BGP 세션을 수립합니다. 이제 라우터 A는 AS0002로 시작하는 모든 BGP 경로에 대해 라우터 B를 거쳐야 한다는 것을 알게 되며, 그 반대도 마찬가지입니다.

BGP 피어들은 *경로 광고(Route advertisement)*라는 프로세스를 통해 자신들이 알고 있는 경로를 서로 공유합니다. 위의 예에서 라우터 A가 라우터 B에 연결될 때, 라우터 A는 라우터 B에게 "이봐, 내가 알고 있는 모든 경로가 여기 있어. 내 ASN(그리고 확장해서 나)을 거쳐서 이 모든 경로에 도달할 수 있어"라고 말합니다. 라우터 B는 라우터 A를 거치는(즉, AS0001로 시작하는) 그 모든 경로를 자신의 라우팅 테이블에 추가합니다. 라우터 A의 또 다른 피어가 새로운 경로를 광고할 때마다, 라우터 A는 그 경로들을 라우터 B에게 전달하여 광고할 것입니다.
AS0001은 아마 직접 몇몇 IP 주소들을 제어하고 있을 것입니다. 라우터 A는 이것들도 라우터 B에게 광고할 것입니다. 그러면 라우터 B는 다시 그 직접 경로들을 앞으로 광고하며, 자신의 피어들에게 AS0002 → AS0001이 해당 IP들에 도달하기 위한 유효한 경로라고 말할 것입니다. 피어들에게 경로 광고를 전달하는 이 과정을 통해, BGP 경로는 자율 시스템의 전체 네트워크로 전파되어 모든 경계 게이트웨이가 인터넷상의 모든 IP에 도달하기 위한 하나 또는 여러 개의 AS 경로를 알 수 있게 됩니다.
특정 IP로 패킷을 라우팅하기 위해, 경계 게이트웨이는 먼저 자신의 라우팅 테이블에서 해당 IP를 제어하는 AS로 연결되는 모든 경로를 검색합니다. 그런 다음 라우터는 최단 경로를 찾거나 특정 자율 시스템에 대한 하드코딩된 선호도를 가중치로 두는 등의 다양한 휴리스틱(Heuristics)을 통해 "최적의" 경로를 선택합니다. 마지막으로, 피어링을 맺고 있는 해당 AS의 게이트웨이 라우터로 패킷을 보냄으로써 그 경로의 첫 번째 AS로 패킷을 라우팅합니다. 그 라우터는 다시 자신의 라우팅 테이블을 보고 패킷을 다음에 어디로 보낼지 스스로 결정합니다.
요약
- 여러분이 이 웹사이트를 로드했을 때, 웹사이트는 저의 커스텀 traceroute 프로그램을 사용하여 여러분의 공인 IP(168.107.33.19)로 traceroute를 실행하고, 이를 HTTP로 스트리밍한 다음, traceroute에 대한 텍스트 설명을 렌더링했습니다.
- traceroute는 인터넷상의 두 장치 사이에서 거쳐 간 라우터들의 경로를 묘사합니다. 저의 특정 구현 방식은 증가하는 TTL 필드를 가진 ICMP 패킷을 보내는 방식으로 작동합니다.
- 이러한 라우터들은 자율 시스템(AS)이라고 불리는 네트워크에 속해 있습니다. 이러한 AS의 가장자리에 있는 라우터들은 BGP를 사용하여 서로 피어링을 맺습니다. 경계 라우터들은 BGP를 사용하여 서로의 라우팅 테이블을 공유하고, 이 지식을 사용하여 라우팅 결정을 내립니다.
- BGP 피어링 세션은 자율 시스템 소유자들 간의 (종종 사적인) 협약에 따라 생성됩니다. 트래픽은 피어링된 네트워크 사이에서만 통과할 수 있으므로, 이러한 협약은 인터넷상의 도달 가능성(Reachability)을 지배하는 유일한 통제 요소입니다.
에필로그
저는 인터넷 구조에 대한 이해 수준에 답답함을 느꼈고, 프로토콜의 관점에서 인터넷의 역사와 정치를 다루는 포괄적이고 인터랙티브한 기사를 쓰고 싶었습니다. 하지만 삶의 여러 복잡한 일들에 얽매이게 되었고, 촉박한 마감 기한에 직면하여 제가 세웠던 높은 목표를 달성할 시간이 부족했습니다.
Hack Club 친구들의 격려 덕분에 제가 가진 것들로 최선을 다했습니다. "크루즈 요트를 절대 띄우지 못하는 것보다 작은 뗏목이라도 띄우는 게 낫다!" 다른 건 몰라도, 이 사이트의 가장 빛나는 부분을 담당하는 멋진 traceroute 프로그램을 활용할 수 있어서 좋았습니다 :)
이것이 웹상에서 오래 지속되고, 공유되며, 사람들에게 영감을 줄 수 있는 또 하나의 재미있고 유익하며 잘 만들어진 결과물이 되기를 바랍니다.
사랑을 담아,
Lexi
기타 정보
확인해 볼 만한 것들:
자랑스러운 오픈 소스:
0
15
댓글
?
아직 댓글이 없습니다.
첫 번째 댓글을 작성해보세요!
n-ryu님의 다른 글
더보기
번역
Async Hooks (비동기 훅)
n-ryu • Back-End
0
0
10

번역
JavaScript에서 "undefined"를 확인하는 가장 적절한 방법은 무엇인가요?
n-ryu • Front-End
0
0
10

번역
좋은 질문을 하는 방법은 무엇인가요? - 고객 센터
n-ryu • Career
0
0
10

Recursive Data Structures and Lazy Evaluation
n-ryu
3
7
220

